Idempotency in Distributed Systems: When and Why It Matters
This article explains idempotency in distributed systems and ensuring consistent results regardless of multiple executions, with implementation and challenges.
Join the DZone community and get the full member experience.
Join For FreeFailures are inevitable in distributed systems due to network partitions, timeouts, and intermittent connectivity issues. When these failures occur, they can lead to delays, incomplete transactions, or inconsistent data states, ultimately impacting the user experience and system reliability. When a system experiences a failure, clients often retry requests to ensure the operation completes successfully.
However, without proper handling, retries can result in unintended consequences such as duplicate transactions, data corruption, or inconsistent states. Implementing idempotency in a system or API ensures that retries following such failures are processed reliably, maintaining the integrity and consistency of the system.
What Is Idempotency?
Idempotency is a property of an operation that guarantees the same result regardless of how many times it is executed. In other words, performing the operation multiple times should not change the outcome beyond the first successful execution.
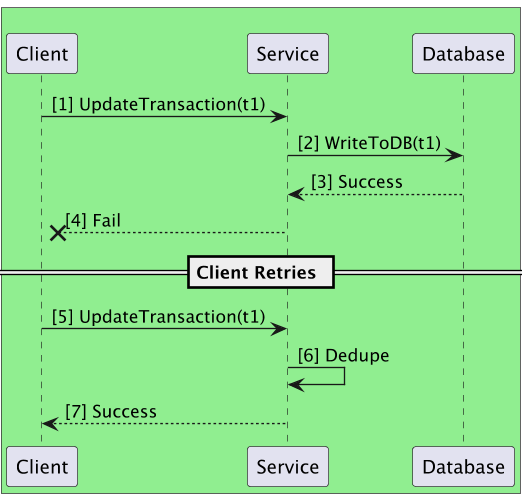
Imagine a client updating a transaction by calling a service, where the service updates its database to mark the transaction as complete. However, while the service is returning a success response to the client, a temporary network failure occurs, preventing the client from receiving the success message. As a result, the client is unaware of whether the request was successfully processed and retries the request.
Without idempotency, the second request could cause the transaction to be updated again, leading to unintended side effects. When idempotency is implemented, the second call is recognized as a duplicate, and the system ensures that the database remains unchanged, preventing duplicate updates.
When Should a System be Idempotent?
Whether idempotency is required depends on the use case and primarily applies to write operations.
Read operations do not require idempotency checks because they inherently exhibit idempotency. Since reads do not modify system state, performing a read operation multiple times will yield the same result, provided the underlying data remains unchanged.
Not all write operations require idempotency. A key principle for determining if idempotency is necessary is to evaluate whether the operation involves computations based on the input that can alter the system state.
For example, a simple write operation that directly stores input into a database does not require idempotency, as repeated calls with the same input will simply overwrite the data without causing inconsistencies (e.g., setting a number to X). However, a write operation that modifies the existing state (e.g., increasing a number by X) requires idempotency to ensure consistency.
Mechanisms to Implement Idempotency
There are multiple ways to implement idempotency in distributed systems. Below are some of the key techniques used:
Unique Keys
The most common approach to implementing idempotency is by using unique identifiers assigned to each request. This approach ensures that duplicate requests are detected and handled appropriately.
General Flow for Processing a Request
- Extract the unique identifier from the request.
- Check if a request with the same identifier has already been processed.
- If not (first-time request): Process the request, persist the result along with the unique identifier, and return the result.
- If yes (duplicate request): Retrieve the previously stored result and return it, optionally indicating that the request was already processed.
If no unique identifier is provided in the request, the system can generate one by computing a hash of all input parameters and using it as the identifier. However, the API documentation must clearly specify this approach to ensure clients do not include variable fields, such as the current timestamp, in the request. Doing so could generate different identifiers for retries, defeating the purpose of idempotency.
Optimistic Locking
Optimistic locking is a concurrency control mechanism used in databases and distributed systems to handle concurrent updates to the same data while minimizing contention. It can also be leveraged to implement idempotency which follows a "read-then-write" approach.
General Flow for Processing a Request
- The client reads a value along with its version number, say
xfrom the server. - The client sends an update request, including the previously read version number (
x). - The server checks if the version number in the client’s request matches the current version in the database.
- If yes: The server processes the request and increments the version number (
x → x+1). - If no: The request is rejected. A mismatch means the version has already been updated—either due to a duplicate request or another system updating the data.
- If yes: The server processes the request and increments the version number (
- If the request is rejected, the client must fetch the latest value with its updated version and decide whether to retry based on the new version and value.
This approach ensures that duplicate or outdated requests do not override the latest data, maintaining consistency and preventing unintended modifications.
Challenges in Implementing Idempotency
While idempotency is essential, implementing it can introduce complexities, including:
- State management. Maintaining unique keys, or version numbers adds overhead to the system and requires efficient storage and retrieval mechanisms.
- Handling side effects. Some operations trigger side effects (e.g., sending emails, triggering notifications). Ensuring that these actions do not happen repeatedly requires additional safeguards.
- Data consistency across distributed systems. If multiple services participate in an operation, coordinating idempotency across them becomes challenging.
Conclusion
The ideal system for idempotency is one that doesn’t require it — such as stateless operations where the output is always directly derived from the inputs. However, in real-world applications, not all systems can be stateless. For example, a banking system must first read the current account balance before making updates like deposits or withdrawals. In such cases, implementing idempotency is crucial to maintaining a consistent system state, preventing unintended side effects, and ensuring a seamless customer experience by avoiding duplicate transactions or data corruption.
With techniques like unique keys, and optimistic locking, developers can ensure idempotency while being mindful of trade-offs. Unique keys require additional storage and request tracking, optimistic locking may lead to higher rejection rates in high-concurrency environments, and request deduplication relies on maintaining logs, which could introduce overhead.
Understanding these challenges helps in selecting the right approach for a given system; allowing developers to build failure-resistant systems that handle retries effectively and maintain data integrity in distributed environments.
Opinions expressed by DZone contributors are their own.
Comments