The 4 R’s of Pipeline Reliability: Designing Data Systems That Last
In this article, learn how the 4 R’s — robust architecture, resumability, recoverability, and redundancy — enhance reliability in AI and ML data pipelines.
Join the DZone community and get the full member experience.
Join For FreeAs AI and machine learning applications continue to proliferate, the data pipelines that power them have become more mission-critical than ever. As retrieval-augmented generation (RAG) applications and real-time AI systems are becoming the norm, any glitch in a data pipeline can lead to stale insights, suboptimal model performance, and inflated infrastructure costs.
Working in this domain has taught me that even minor lapses in pipeline reliability can escalate into major outages. To combat this, I rely on a framework I call the 4 R’s of pipeline reliability: robust architecture, resumability, recoverability, and redundancy. Here’s how each element contributes to building data systems that truly last.
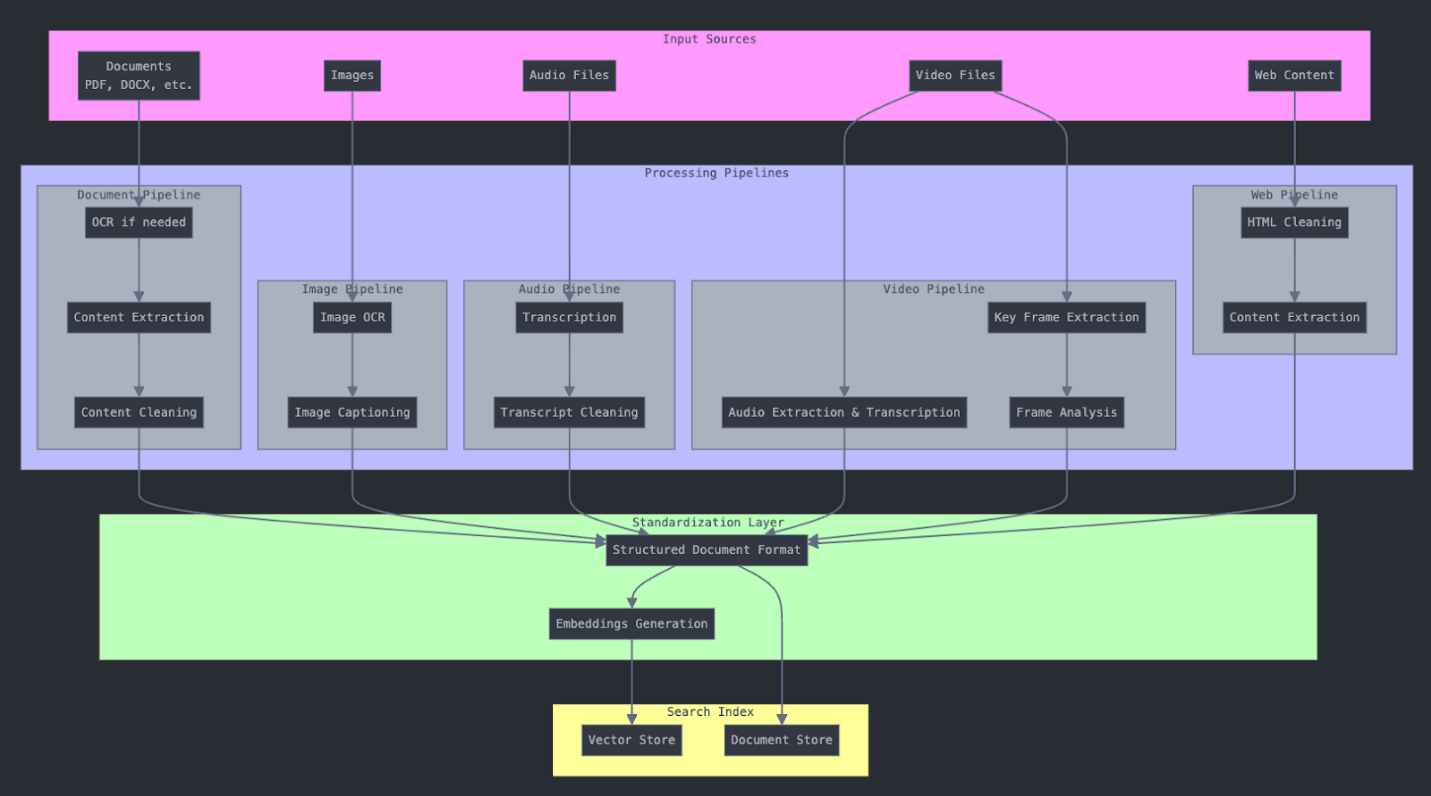
R1: Robust Architecture
Problem
How do we ensure fault tolerance in streaming dataflows?
A strong pipeline begins with a well-architected foundation. Every stage of the pipeline should be clearly defined, with distinct boundaries and a well-understood failure domain.
Key Principles
- Clear phases: Separate transformations into distinct stages to improve clarity and modularity.
- Failure domain segmentation: Group operations that are tightly coupled (e.g., all OCR calls) so they can fail together without impacting unrelated components.
- Microservice isolation: Leverage circuit breakers, feature flags, and health checks to isolate and contain failures.
- Data contracts and validation: Ensure strict validation rules and enforce data contracts at every interface.
- Scalability and cost optimization: Design a tiered architecture so that only necessary parts scale, keeping cost in check.
Case in Point
In a pipeline structured as a waterfall chain (A → B → C), we introduced dynamic feature flag controls and developed a health monitoring system. This allowed for automatic reordering of services based on real-time metrics.
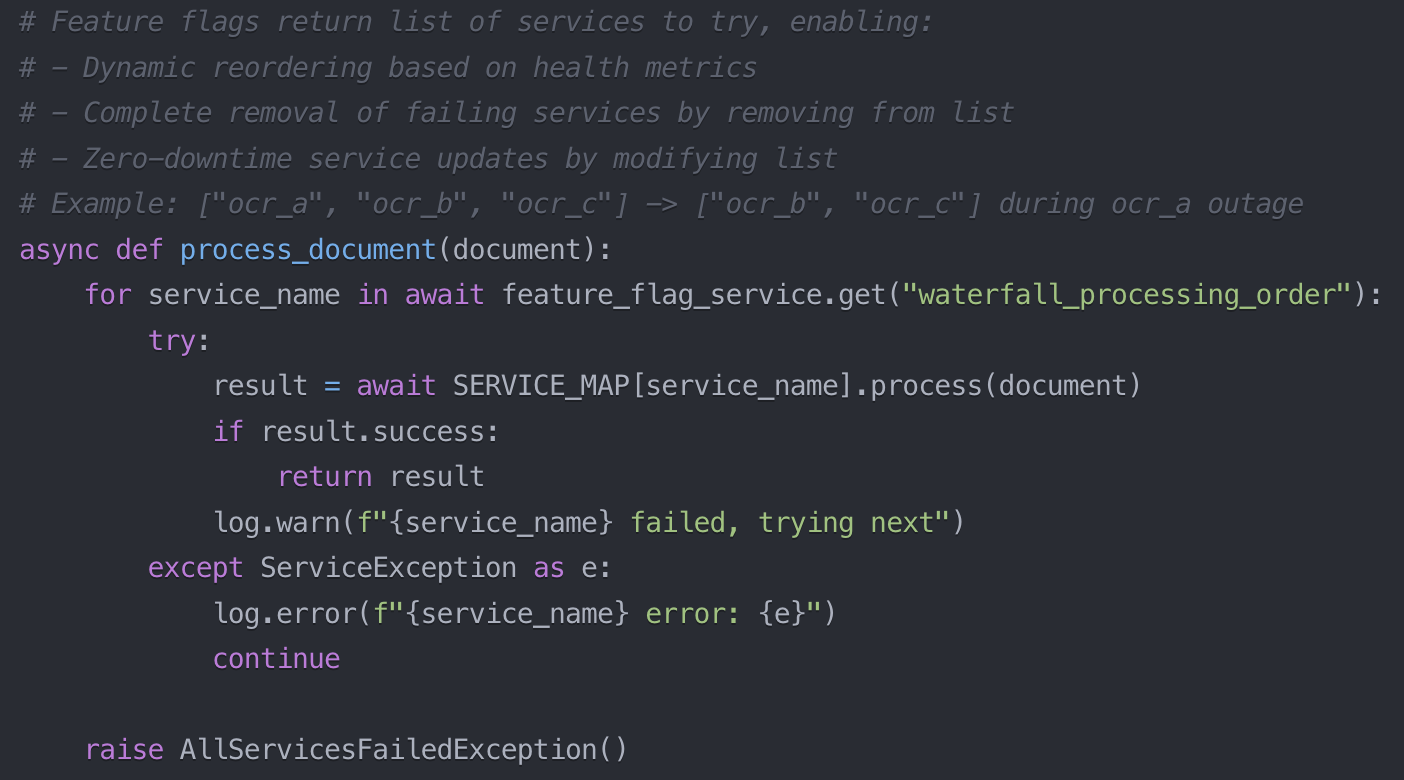
Impact
- The pipeline continued functioning even when individual services failed.
- Automatic rerouting maintained uptime and system performance.
- Zero-downtime orchestration became achievable through health-aware logic.
Key Learning
Feature flags, when combined with real-time health monitoring, create a resilient architecture that gracefully handles service failures.
R2: Resumability
Problem
How do we return to the last known good state after a failure?
Interruptions are inevitable. What matters is how gracefully a system can pick up from where it left off, without starting over or losing valuable progress.
Key Principles
- Strategic checkpointing: Place checkpoints after high-cost operations such as embeddings, OCR, or AI model queries.
- State persistence: Store intermediate states only when necessary to avoid ballooning storage costs.
- Progress tracking: Maintain clear markers for resumption and ensure integrity verification.
- Storage efficiency: Use staged or temporary checkpoints to balance cost and reliability.
Case in Point
Our team identified costly operations within the pipeline and applied checkpointing selectively. To manage storage costs, we introduced automatic cleanup mechanisms to discard temporary checkpoints once they were no longer needed.
Impact
- Over 80% of pipelines avoided redundant processing.
- Storage usage was significantly reduced.
- The system achieved higher reliability without sacrificing resource efficiency.
Key Learning
Selective and strategic checkpointing is the most efficient way to maintain reliability while minimizing overhead.
R3: Recoverability
Question
What happens when something breaks?
Every pipeline is bound to fail at some point. The key is to detect, diagnose, and recover from failures quickly and effectively.
Key Principles
- Structured logging: Use well-labeled, structured logs to capture failures and operational states.
- Error detection and alerting: Categorize errors systematically and automate alerts.
- Automated recovery: Implement retry mechanisms with exponential backoff and clear documentation for manual recovery steps.
- Visualization: Build real-time dashboards that reflect the health and performance of every stage in the pipeline.
Case in Point
To better track complex data flows, we used Prefect and enhanced our labeling of pipeline tasks. Dashboards were created to offer real-time insight into execution status and duration, with alerts triggered on failure.
Impact
- Faster identification of failure points.
- Reduced time to resolution thanks to granular visibility.
- Improved system transparency for engineering teams.
Key Learning
Structured logging and real-time flow tracking are essential for scalable, maintainable pipeline systems.
Case Study: Flow Tracking With Prefect
Challenge
Difficulty monitoring complex data pipelines.
Solution
To improve identification, labeled tasks were introduced to enhance the ability to identify pipeline execution. Real-time dashboards were developed to help monitor the execution status and to raise an alarm in case of an incident.
Impact
This approach enabled quicker debugging and more responsive incident handling since we now get a direct view and trace into each ingestion flow, as well as a timeline of how long each stage takes..
Major Learning
Structured logging and flow tracking are a must-have to support developers in scaling and maintaining pipeline-based systems..
R4: Redundancy
Question
How can we ensure continued operation even when components fail?
Relying on a single processing path or service provider introduces unnecessary risk. Redundancy mitigates this by allowing systems to remain functional despite failures.
Key Principles
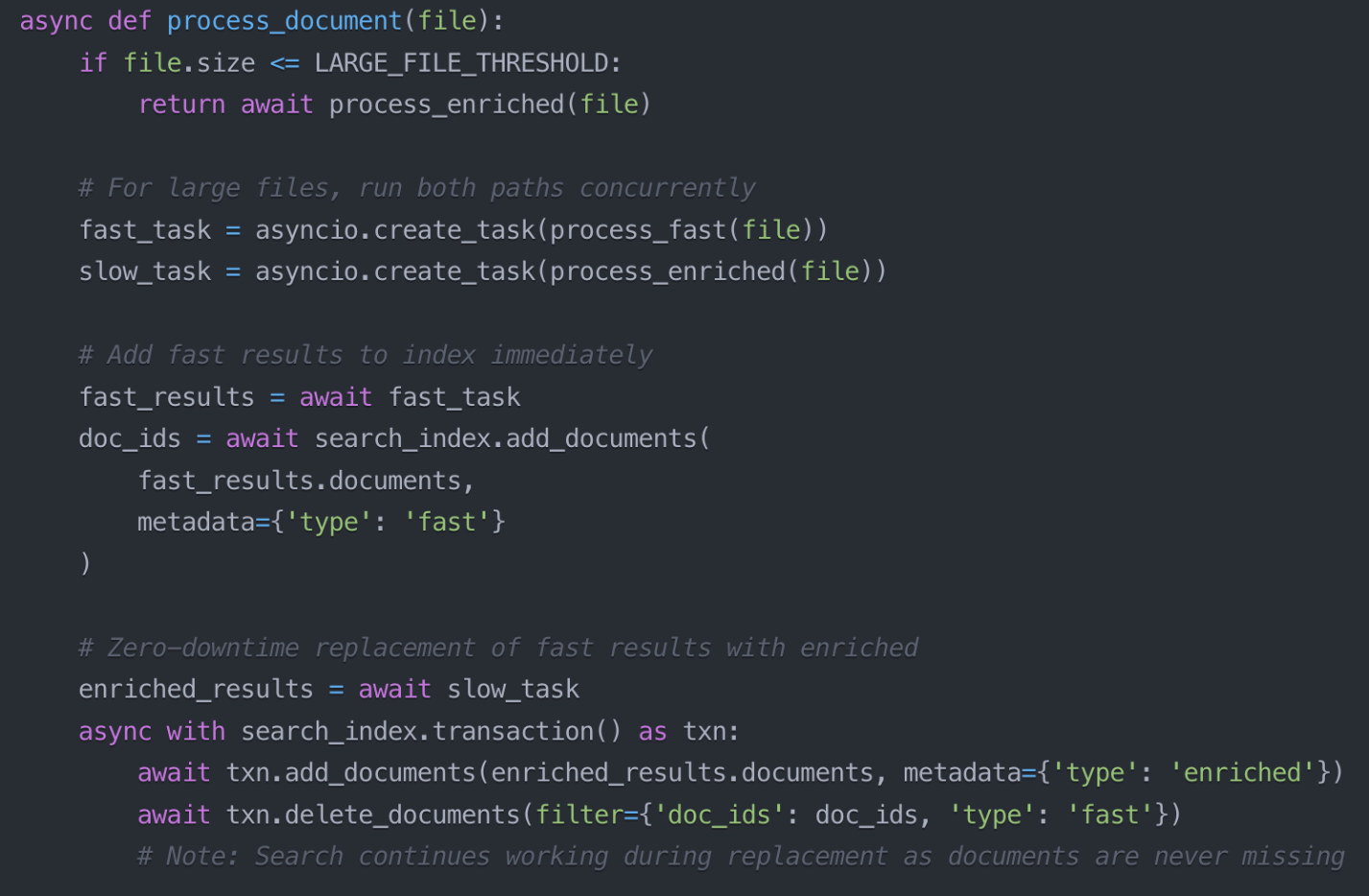
- Multiple processing paths: Use an initial fast-track path for immediate output, with a background path for enrichment.
- Service alternatives: Integrate multiple service providers for fallback capability.
- Graceful degradation: Define degraded modes of operation that allow the system to function acceptably, even under failure.
- Load balancing: Distribute workloads across redundant resources to prevent bottlenecks.
Case in Point
We implemented a fast-processing route for rapid output, supplemented by a background enrichment pipeline. A trigger mechanism automatically transitioned the user-facing output from the fast result to the enriched version once it became available.
Impact
- Users received immediate results, reducing latency.
- Data quality improved over time without user disruption.
The system gracefully handled service outages.
Key Learning
Multiple processing paths optimize the trade-off between speed and data quality.
Conclusion: Building Pipelines That Endure
Reliability in data pipelines isn’t an afterthought — it’s a product of intentional design choices. The 4 R’s framework — robust architecture, resumability, recoverability, and redundancy — provides a comprehensive approach to building resilient systems that power the future of AI and ML.
Practical Next Steps
- Begin with an audit of your existing pipelines. Identify where data loss or inefficiency is occurring.
- Implement each of the 4 R’s gradually, starting with the areas that will yield the highest improvement in reliability.
- Continuously measure key metrics like time to recover, processing efficiency, and operational cost.
- Consider tools such as Prefect, Airflow, or other orchestration platforms to streamline and automate workflows.
As AI-enabled applications continue to evolve, the reliability of their underlying data systems will become even more crucial. By embracing the 4 R’s, we can build pipelines that are not only robust, but also adaptable, efficient, and ready for what comes next.
Opinions expressed by DZone contributors are their own.
Comments