Resilient Data Pipelines in GCP: Handling Failures and Latency in Distributed Systems
Learn resilience strategies for Google Cloud data pipelines. Balance latency, reliability, and recovery with Pub/Sub, Dataflow, BigQuery, and SRE practices.
Join the DZone community and get the full member experience.
Join For FreeI have spent years designing and operating data pipelines in Google Cloud, and one thing has not changed: resilience is not optional. It does not matter how nice your design diagrams look or how scalable the architecture is. In practice, nodes die, quotas are exhausted, regions are shaded, schemas alter unannounced, and message queues are clogged up at the most unpredictable moments. The main distinction between a functional pipeline and a resilient pipeline lies in the fact that the former can withstand failures and still meet latency requirements.
The article explains my philosophy on resilience in distributed data pipelines on GCP, based not only on the experience of running these systems, but also more broadly on systems research and Google operational experience.
Why Resilience and Latency Are Twin Problems
When discussing data pipeline reliability, individuals often focus solely on availability. However, latency is also necessary. A pipeline that is operational but with a 10-minute delay in event delivery can be as detrimental as a pipeline that is down altogether, especially when the use case involves real-time applications, such as fraud detection, personalization, or IoT monitoring.
Latency and resilience are synonymous in GCP. In turn, over-provisioning resilience (e.g., through over-aggressive data replication) can introduce tail latency across regions. On the other hand, optimizing solely on latency may compromise your failure resilience. The big question in the design of resilient pipelines in GCP is how to broker this trade-off.
The Failure Modes That Matter
Over time, I’ve seen a pattern of recurring failure modes in GCP pipelines:
- Node failures in Dataflow or Composer that trigger retries but risk cascading backlogs.
- Quota exhaustion for Pub/Sub or BigQuery streaming inserts during traffic bursts.
- Regional outages that break latency SLAs unless workloads are designed for failover.
- Schema mismatches occur when producers evolve faster than consumers, resulting in silent data loss.
- Stragglers in distributed processing, where 1% of workers delay the entire job.
Each of these failures isn’t catastrophic in isolation. But when compounded, say, a traffic spike hitting quota limits during a regional blip, they can bring pipelines to their knees unless you’ve deliberately engineered resilience into the design.
Lessons From the Field
When I seek inspiration beyond my own work, I often turn to research and operational tales that reveal the truth about distributed systems. As an example, I have found LEGOStore.
A geo-distributed datastore that is assessed across Google Cloud regions. It had a dynamic reconfiguration between erasure code and replication to optimize cost, latency, and failure resiliency. Although I do not use erasure coding in my pipelines, the general concept of resilience being dynamic was familiar: resilience is not fixed. In the case of LEGOStore, the strategy changed based on the workload situation. Similarly, in practice, I have had to design flexibility into how the pipelines buffer and process data, e.g,. adjusting Pub/Sub throughput and backlog retention dynamically based on observed latency budgets.
On the operational side, there is the Google SRE workbook. It has found its way to be equally influential. It does not idealize pipelines; it records the dirty details of dealing with overload recovery, canary changes, and coping with stragglers. The single concept that I took directly is the concept of latency budgets. We are no longer measuring generic system metrics, but we explicitly measure lag: the difference between event time and processing time. That is the metric, not the CPU utilization, that says whether customers are receiving real-time data. Alignment to latency budgets has shifted our dialogue with engineers who are no longer interested in firefighting symptoms, but in whether the pipeline is fulfilling its commitments.
Designing for Failure in GCP Pipelines
Over the years, I’ve converged on a set of patterns that consistently improve resilience in distributed pipelines on GCP:
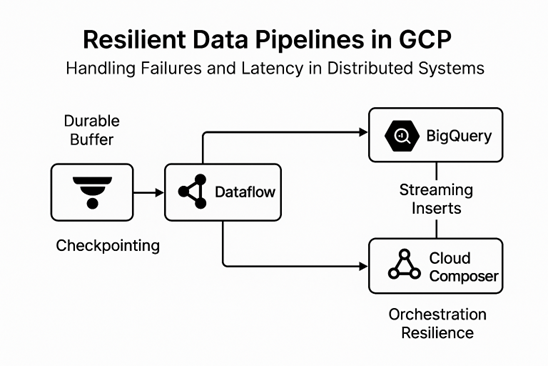
Pub/Sub as a Durable Buffer
Pub/Sub is a standard first line of defense. I use it not only to communicate, but as a stable cushion. The at-least-once delivery semantics imply that duplicates are possible, so idempotent consumers are not optional. I also pay a lot of attention to backlog retention: storing messages up to seven days gives you a lifeline in the event of an outage, but also causes storage and replay overheads. The key is to size retention windows according to the recovery expectations and not some random default.
Dataflow Resiliency Features
Auto-scaling in Dataflow is very strong; however, resilience is not automatic. I have encountered situations where auto-scaling failed to keep pace with bursts, leading to several minutes of pipeline backlog. We balance this by tuning scaling thresholds and occasionally over-provision deliberately at times of high risk. Another lifesaver is Streaming Engine check-pointing, which means that in the case of node failures, the job does not have to restart completely.
A hot/cold path design is one pattern that has proven helpful to me: the most critical events are handled on a high-speed simplified path, and bulk data is handled on a more complex pipeline. In such a manner, the business-essential data continues to flow in even when there is partial failure.
BigQuery and Latency SLAs
BigQuery is powerful; however, during high activity, streaming inserts can reach the quota limit. To curb this, I have adopted micro-batching using Dataflow: I store events temporarily (before committing them in larger batches). This minimizes quota load while maintaining end-to-end latency at an acceptable level. Another source of pain is schema drift; streaming inserts might silently fail when the producers append fields. The solution is to apply schema evolution contracts and track rejected rows as a first-class metric.
Cloud Composer for Orchestration
Everything can be magnified with orchestration failures. I have learned to be careful with retries in Cloud Composer DAGs- naive retries may overwhelm downstream systems. Instead, we apply exponential back-off with jitter and, in some cases, cross-region orchestration of critical workflows.
Detecting and Responding to Latency Spikes
Observability is the backbone of resilience. I’ve had pipelines where everything “looked fine” in infrastructure dashboards, but customers were seeing hour-old data. The missing link was lag monitoring.
Using cloud monitoring and OpenTelemetry, we track:
- Pub/Sub subscription lag (backlog size over throughput).
- Dataflow watermark metrics (event time vs processing time).
- BigQuery load latencies per partition.
When a spike is felt, the response is contextual. When stragglers cause the skew in the data distribution, we study skew. Where it is a downstream quota issue, we redirect loads to alternative tables or regions. In the case that it is only input burstiness, we can wait until auto-scaling has caught up, but with alerts to prevent silent degradation.
The goal is not just to react, but to have run-books as predefined responses, so engineers don't have to improvise at 2 a.m.
Recovery Patterns That Work
A resilient pipeline doesn’t avoid failure; it contains it. Some patterns I rely on:
- Check-pointing + idempotency: Every stage must be able to replay inputs without duplication.
- Dead-letter queues: Invalid events go into DLQs for later inspection rather than blocking the pipeline.
- Canary pipelines: We roll out changes to a small slice of traffic first, so failures don’t cascade.
- Chaos testing: We deliberately kill workers, delay messages, or exhaust quotas in test environments. This surfaces weaknesses before production does.
These patterns are not glamorous, but they’re what keep pipelines resilient in practice.
What Resilience Has Taught Me
Among the most challenging things I have learned is that resilience is not a check box at design time. It is a continuing practice. Architecture diagrams can have a five-nines availability claim, but actual resilience is achieved after months of operation in unpredictable conditions, postmortems, and playbook refinement.
Another lesson I have learnt is that resilience is a matter of culture as much as it is of technology. Teams need to appreciate the importance of observability, perform postmortems without blame, and be ready to make trade-offs to optimize reliability over immediate delivery speed.
I did not feel proud of my design doc when a pipeline we designed was hit with a regional disruption, and customers were not affected. I felt proud of the team that was disciplined enough to operationalize resilience day in and day out.
Conclusion
Distributed systems are bound to fail. There are latency spikes that cannot be avoided when unpredictable traffic is involved. However, with GCP, we are in a position to absorb such shocks gracefully. Pub/Sub provides us with persistent buffers. Dataflow gives checkpointing and auto-scaling. BigQuery provides scalable analytics that are managed with caution to quota. Cloud Composer orchestrates, retries, and controls DAG.
The actual problem is how to incorporate them into pipelines that work well, even on the most dreadful days. Research like that on the LEGOStore, demonstrates that flexibility in data resilience strategies can maintain system efficiency without undermining reliability. Our SRE lessons at Google tell us that resilience is not a theory; it is an operation. It is the small, disciplined practices, lag monitoring, run-books, and chaos tests that make a difference.
We did not develop resilience for grace. We have created it because businesses require reliability. And each time a failure did not become an incident, the investment was justified.
Opinions expressed by DZone contributors are their own.
Comments