Top Methods to Improve ETL Performance Using SSIS
Improve ETL performance in SSIS with parallel extraction, optimized transformations, and proper configuration of concurrency, batch sizes, and data types.
Join the DZone community and get the full member experience.
Join For FreeExtract, transform, and load (ETL) is the backbone of many data warehouses. In the data warehouse world, data is managed through the ETL process, which consists of three steps: extract—pulling or acquiring data from sources, transform—converting data into the required format, and load—pushing data to the destination, typically a data warehouse or data mart.
SQL Server Integration Services (SSIS) is an ETL tool widely used for developing and managing enterprise data warehouses. Given that data warehouses handle large volumes of data, performance optimization is a key challenge for architects and DBAs.
ETL Improvement Considerations
Today, we will discuss how you can easily improve ETL performance or design a high-performing ETL system using SSIS. To better understand this, we will divide ten methods into two categories: first, SSIS package design-time considerations, and second, configuring property values of components within the SSIS package.
SSIS Package Design-Time Considerations
Extract Data in Parallel
SSIS allows data extraction in parallel using Sequence Containers in control flow. By designing a package to pull data from non-dependent tables or files simultaneously, you can significantly reduce overall ETL execution time.
Extract Required Data
Pull only the required set of data from any table or file. Avoid the tendency to retrieve all available data from the source just because you might need it in the future—it consumes network bandwidth, system resources (I/O and CPU), extra storage, and degrades overall ETL performance. If your ETL system is highly dynamic and requirements frequently change, consider other design approaches, such as metadata-driven ETL, rather than pulling everything at once.
Avoid the Use of Asynchronous Transformation Components
SSIS is a powerful tool with a variety of transformation components for handling complex tasks during ETL execution. However, improper use of these components can significantly impact performance. SSIS offers two types of transformation components: synchronous and asynchronous.
- Synchronous transformations process each row and pass it directly to the next component or destination. They use allocated buffer memory efficiently and don’t require additional memory since each input/output data row fits entirely within the allocated space. Components like Lookup, Derived Columns, and Data Conversion fall into this category.
- Asynchronous transformations first store data in buffer memory before processing operations like Sort and Aggregate. These transformations require additional buffer memory, and until it becomes available, the entire dataset remains in memory, blocking the transaction—this is known as a blocking transformation. To complete the task, the SSIS engine (data flow pipeline engine) allocates extra buffer memory, adding overhead to the ETL system. Components like Sort, Aggregate, Merge, and Join fall into this category.
Overall, you should avoid asynchronous transformations. However, if you have no other choice, you must be aware of how to manage the available property values of these components. We’ll discuss them later in this article.
Make Optimum Use of Event in Event Handlers
To track package execution progress or take other appropriate actions on specific events, SSIS provides a set of event handlers. While events are useful, excessive use can add unnecessary overhead to ETL execution. Therefore, it’s important to carefully evaluate their necessity before enabling them in an SSIS package.
Consider the Destination Table Schema When Working With Large Data Volumes
You should think twice when pulling large volumes of data from the source and loading it into a data warehouse or data mart. You may see performance issues when executing a high volume of insert, update, and delete (DML) operations, especially if the destination table has clustered or non-clustered indexes. These indexes can lead to significant data shuffling in memory, further impacting ETL performance.
If ETL performance issues arise due to a high volume of DML operations on an indexed table, consider modifying the ETL design. One approach is to drop existing clustered indexes before execution and re-create them after the process completes. Depending on the scenario, alternative solutions may be more effective in optimizing performance.
Configure Components Properties
Control parallel task execution by configuring the MaxConcurrentExecutables and EngineThreads properties. MaxConcurrentExecutables is a package-level property with a default value of -1, meaning the maximum number of concurrent tasks is equal to the total number of processors on the machine plus two.
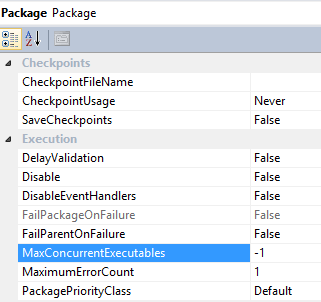
EngineThreads is a data flow task level property and has a default value of 10, which specifies the total number of threads that can be created for executing the data flow task.
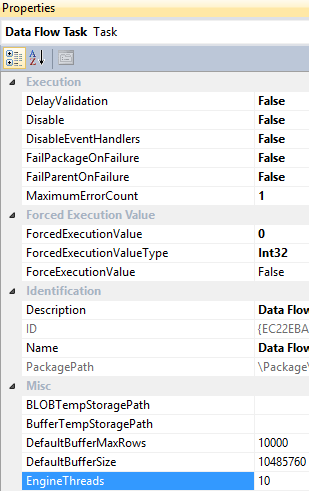
You can adjust the default values of these properties based on ETL requirements and available system resources.
Configure the Data Access Mode option in the OLE DB Destination. In the SSIS data flow task, the OLE DB destination offers multiple options for inserting data into the destination table. The "Table or view" option inserts one row at a time, whereas the "Table or view - fast load" option utilizes bulk insert, significantly improving performance compared to other methods.
Once you choose the "fast load" option, it provides greater control over the destination table's behavior during a data push operation. You can configure options such as Keep Identity, Keep Nulls, Table Lock, and Check Constraints to optimize performance and maintain data integrity.

It’s highly recommended to use the fast load option when pushing data into the destination table to improve ETL performance.
Configure Rows per Batch and Maximum Insert Commit Size in OLEDB Destination. These two settings are crucial for managing tempdb and transaction log performance. With the default values, all data is pushed in a single batch and transaction, leading to excessive tempdb and transaction log usage. This can degrade ETL performance by consuming excessive memory and disk storage.

To improve ETL performance, you can set a positive integer value for both properties based on the anticipated data volume. This will divide the data into multiple batches, allowing each batch to be committed separately to the destination table. This approach helps reduce excessive tempdb and transaction log usage, ultimately improving ETL performance.
Use SQL Server Destination in a data flow task. When pushing data into a local SQL Server database, it is highly recommended to use SQL Server Destination to improve ETL performance. This option leverages SQL Server's built-in bulk insert feature, offering better performance compared to other methods. Additionally, it allows data transformation before loading and provides control over triggers, enabling or disabling them as needed to reduce ETL overhead.
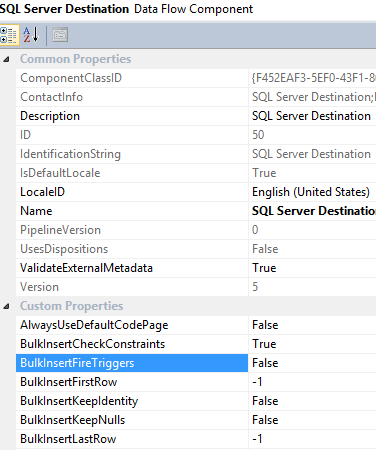
Avoid implicit typecasting. When data comes from a flat file, the Flat File Connection Manager treats all columns as string (DS_STR) data types, including numeric columns. Since SSIS uses buffer memory to store data and apply transformations before loading it into the destination table, storing numeric values as strings increases buffer memory usage, reducing ETL performance.
To improve ETL performance, you should convert all the numeric columns into the appropriate data type and avoid implicit conversion, which will help the SSIS engine to accommodate more rows in a single buffer.
Summary of ETL Performance Improvements
In this article, we explored how easily ETL performance can be controlled at any point in time. These are common ways to improve ETL performance, though there may be other methods depending on specific scenarios. By categorizing these strategies, you can better determine how to tackle performance challenges. If you're in the design phase of a data warehouse, you may need to focus on both categories, but if you're supporting a legacy system, it's best to start by working closely on the second category.
Opinions expressed by DZone contributors are their own.
Comments