Improving Query Speed to Make the Most Out of Your Data
Our struggle with data warehouses when data becomes overwhelming.
Join the DZone community and get the full member experience.
Join For FreeToo Much Data on My Plate
The choice of data warehouses was never high on my worry list until 2021. I have been working as a data engineer for a Fintech SaaS provider since its incorporation in 2014. In the company's infancy, we didn't have too much data to juggle. We only needed a simple tool for OLTP and business reporting, and the traditional databases would cut the mustard.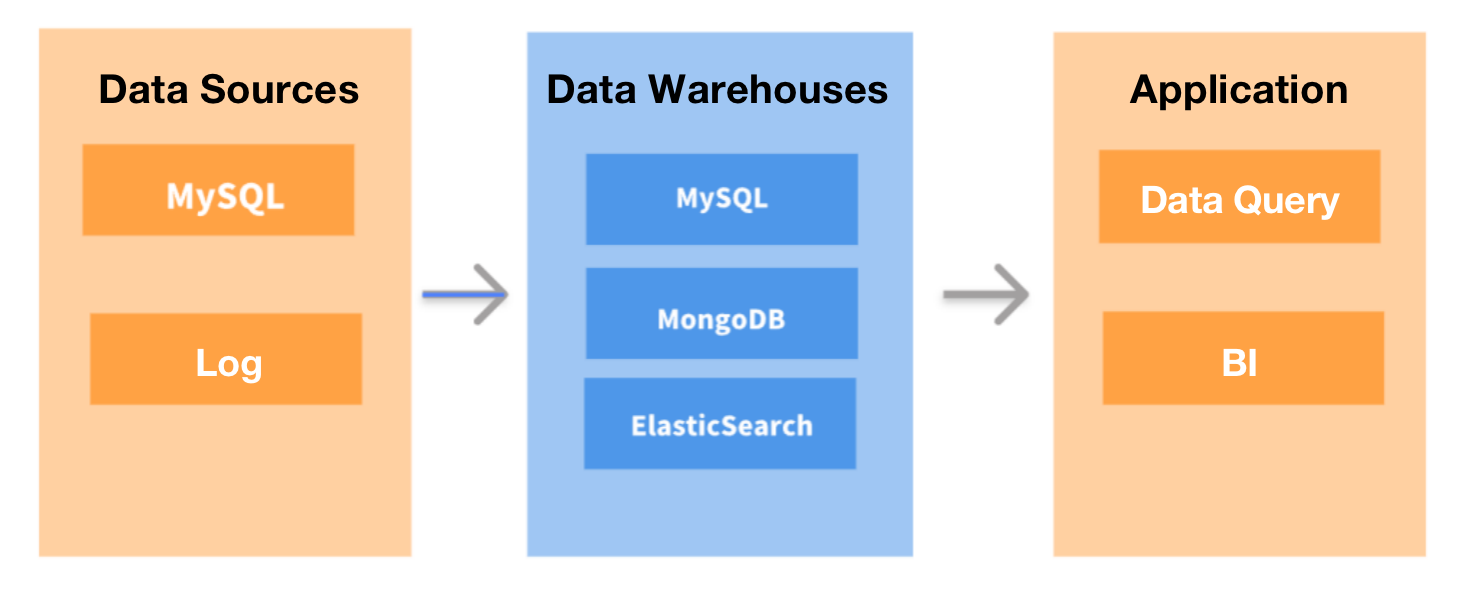
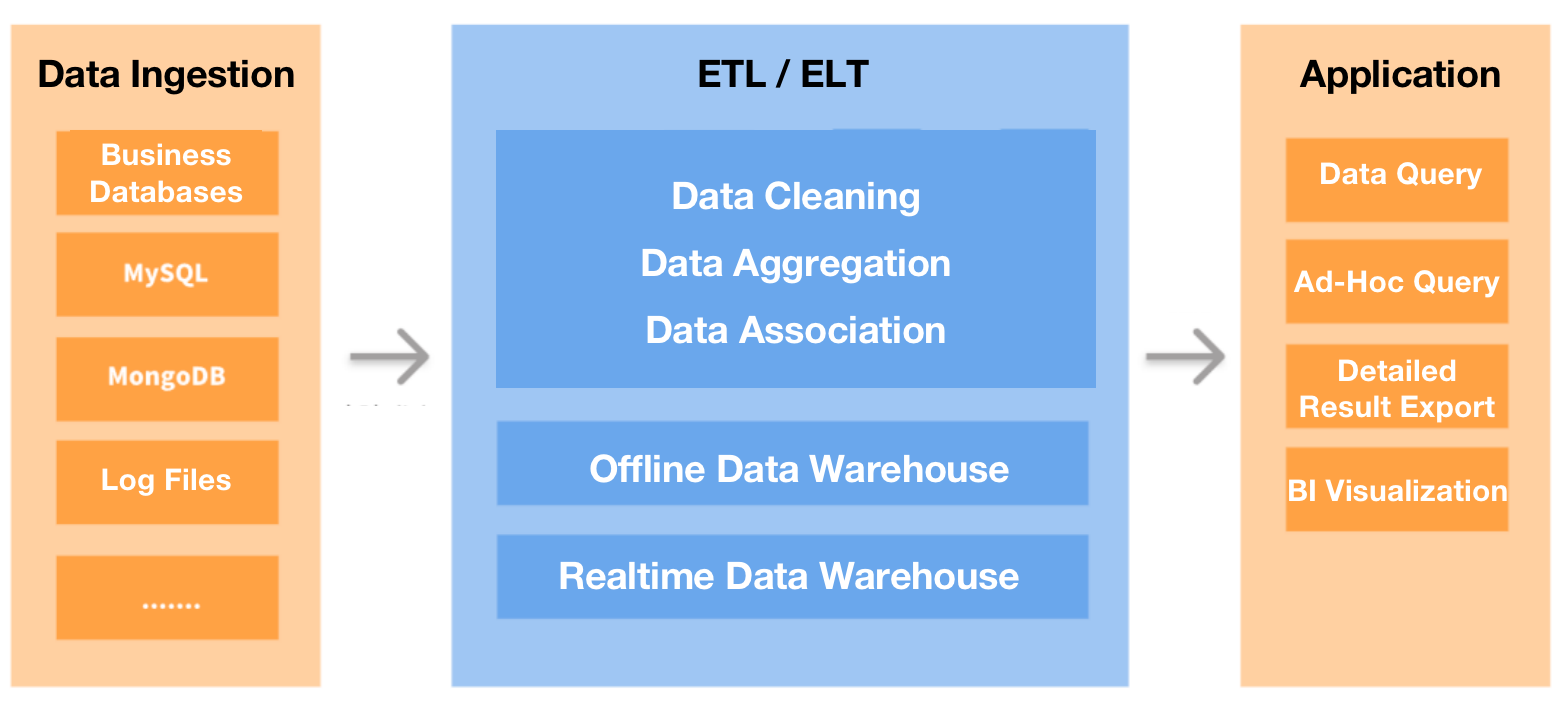
The first thing we did was to revolutionize our data processing architecture. We used DataHub to collect all our transactional or log data and ingest it into an offline data warehouse for data processing (analyzing, computing. etc.). Then the results would be exported to MySQL and then forwarded to QuickBI to display the reports visually. We also replaced MongoDB with a real-time data warehouse for business queries.
- We wanted faster responses. MySQL could be slow in aggregating large tables, but our product guys requested a query response time of fewer than five seconds. So first, we tried to optimize MySQL. Then we also tried to skip MySQL and directly connect the offline data warehouse with QuickBI, hoping that the combination of query acceleration capability of the former and caching of the latter would do the magic. Still, that five-second goal seemed to be unreachable. There was a time when I believed the only perfect solution was for the product team to hire people with more patience.
- We wanted less pain in maintaining dimension tables. The offline data warehouse conducted data synchronization every five minutes, making it not applicable for frequent data updates or deletions scenarios. If we needed to maintain dimension tables in it, we would have to filter and deduplicate the data regularly to ensure data consistency. Out of our trouble-averse instinct, we chose not to do so.
- We wanted support for point queries of high concurrency. The real-time database that we previously used required up to 500ms to respond to highly concurrent point queries in both columnar storage and row storage, even after optimization. That was not good enough.
Hit It Where It Hurts Most
In March 2022, we started our hunt for a better data warehouse. To our disappointment, there was no one-size-fits-all solution. Most of the tools we looked into were only good at one or a few of the tasks, but if we gathered the best performer for each usage scenario, that would add up to a heavy and messy toolkit, which was against instinct.So we decided to solve our biggest headache first: slow response, as it was hurting both the experience of our users and our internal work efficiency. To begin with, we tried to move the largest tables from MySQL to Apache Doris, a real-time analytical database that supports MySQL protocol. That reduced the query execution time by a factor of eight. Then we tried and used Doris to accommodate more data.
As for now, we are using two Doris clusters: one to handle point queries (high QPS) from our users and the other for internal ad-hoc queries and reporting. As a result, users have reported smoother experiences, and we can provide more features that used to be bottlenecked by slow query execution. Moving our dimension tables to Doris also brought fewer data errors and higher development efficiency.

Tips
Data Model
Data Ingestion
For offline data ingestion, we use DataX: This mainly involves the computed report data in our offline data warehouse.
Data Management
Monitoring and Alerting
Tradeoff Between Resource Usage and Real-Time Availability
Communication With Developers
We have been in close contact with the open-source Doris community all the way from our investigation to our adoption of the data warehouse, and we've provided a few suggestions to the developers:- Enable Flink-Doris-Connector to support simultaneous writing of multiple tables in a single sink.
- Enable Materialized Views to support the Join of multiple tables.
- Optimize the underlying compaction of data and reduce resource usage as much as possible.
- Provide optimization suggestions for slow SQL and warnings for abnormal table creation behaviors.
Conclusion
As we set out to find a single data warehouse that could serve all our needs, we ended up finding something less than perfect but good enough to improve our query speed by a wide margin and discovered some surprising features of it along the way. So if you wiggle between different choices, you may bet on the one with the thing you want most badly, and taking care of the rest wouldn't be so hard.Opinions expressed by DZone contributors are their own.
Comments