In-Memory Data Grids With Hazelcast, Hibernate, and Spring Boot
If your priority is the performance of queries on large amounts of data and you have a lot of RAM, an in-memory data grid is the right solution for you!
Join the DZone community and get the full member experience.
Join For FreeIn my previous article about JPA caching with Hazelcast, Hibernate, and Spring Boot, I described an example illustrating Hazelcast usage as a solution for the Hibernate second-level cache. One big disadvantage of that example was an ability by caching entities only by primary key. The opportunity to cache JPA queries by some other indices helped, but that did not solve the problem completely because the query could use already-cached entities even if they matched the criteria.
In this article, I’m going to show you a smart solution of that problem based on Hazelcast distributed queries.
Spring Boot has a built-in auto configuration for Hazelcast if such a library is available under the application classpath and @BeanConfig is declared:
@Bean
Config config() {
Config c = new Config();
c.setInstanceName("cache-1");
c.getGroupConfig().setName("dev").setPassword("dev-pass");
ManagementCenterConfig mcc = new ManagementCenterConfig().setUrl("http://192.168.99.100:38080/mancenter").setEnabled(true);
c.setManagementCenterConfig(mcc);
SerializerConfig sc = new SerializerConfig().setTypeClass(Employee.class).setClass(EmployeeSerializer.class);
c.getSerializationConfig().addSerializerConfig(sc);
return c;
}In the code fragment above, we declared cluster names and password credentials, connection parameters to the Hazelcast Management Center, and entity serialization configuration. The entity is pretty simple; it has @Id and two fields for searching personId and company.
@Entity
public class Employee implements Serializable {
private static final long serialVersionUID = 3214253910554454648 L;
@Id
@GeneratedValue
private Integer id;
private Integer personId;
private String company;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getPersonId() {
return personId;
}
public void setPersonId(Integer personId) {
this.personId = personId;
}
public String getCompany() {
return company;
}
public void setCompany(String company) {
this.company = company;
}
}Every entity needs to have the serializer declared if it is to be inserted and selected from the cache. There are same default serializers available inside the Hazelcast library, but I implemented the custom one for our sample. It is based on StreamSerializer and ObjectDataInput.
public class EmployeeSerializer implements StreamSerializer < Employee > {
@Override
public int getTypeId() {
return 1;
}
@Override
public void write(ObjectDataOutput out, Employee employee) throws IOException {
out.writeInt(employee.getId());
out.writeInt(employee.getPersonId());
out.writeUTF(employee.getCompany());
}
@Override
public Employee read(ObjectDataInput in ) throws IOException {
Employee e = new Employee();
e.setId( in .readInt());
e.setPersonId( in .readInt());
e.setCompany( in .readUTF());
return e;
}
@Override
public void destroy() {}
}There is also a DAO interface for interacting with the database. It has two searching methods and extends Spring data CrudRepository.
public interface EmployeeRepository extends CrudRepository<Employee, Integer> {
public Employee findByPersonId(Integer personId);
public List<Employee> findByCompany(String company);
}In this sample, the Hazelcast instance is embedded into the application. When starting the Spring Boot application, we have to provide VM argument -DPORT , which is used for exposing the service REST API. Hazelcast automatically detects other running member instances and its port will be incremented out of the box. Here’s the REST @Controller class with exposed API:
@RestController
public class EmployeeController {
private Logger logger = Logger.getLogger(EmployeeController.class.getName());
@Autowired
EmployeeService service;
@GetMapping("/employees/person/{id}")
public Employee findByPersonId(@PathVariable("id") Integer personId) {
logger.info(String.format("findByPersonId(%d)", personId));
return service.findByPersonId(personId);
}
@GetMapping("/employees/company/{company}")
public List < Employee > findByCompany(@PathVariable("company") String company) {
logger.info(String.format("findByCompany(%s)", company));
return service.findByCompany(company);
}
@GetMapping("/employees/{id}")
public Employee findById(@PathVariable("id") Integer id) {
logger.info(String.format("findById(%d)", id));
return service.findById(id);
}
@PostMapping("/employees")
public Employee add(@RequestBody Employee emp) {
logger.info(String.format("add(%s)", emp));
return service.add(emp);
}
}@Service is injected into the EmployeeController. Inside EmployeeService, there is a simple implementation of switching between the Hazelcast cache instance and Spring Data DAO @Repository. In every find method, we are trying to find data in the cache, and in case it’s not there, we are searching for it in the database and then putting the found entity into the cache.
@Service
public class EmployeeService {
private Logger logger = Logger.getLogger(EmployeeService.class.getName());
@Autowired
EmployeeRepository repository;
@Autowired
HazelcastInstance instance;
IMap < Integer, Employee > map;
@PostConstruct
public void init() {
map = instance.getMap("employee");
map.addIndex("company", true);
logger.info("Employees cache: " + map.size());
}
@SuppressWarnings("rawtypes")
public Employee findByPersonId(Integer personId) {
Predicate predicate = Predicates.equal("personId", personId);
logger.info("Employee cache find");
Collection < Employee > ps = map.values(predicate);
logger.info("Employee cached: " + ps);
Optional < Employee > e = ps.stream().findFirst();
if (e.isPresent())
return e.get();
logger.info("Employee cache find");
Employee emp = repository.findByPersonId(personId);
logger.info("Employee: " + emp);
map.put(emp.getId(), emp);
return emp;
}
@SuppressWarnings("rawtypes")
public List < Employee > findByCompany(String company) {
Predicate predicate = Predicates.equal("company", company);
logger.info("Employees cache find");
Collection < Employee > ps = map.values(predicate);
logger.info("Employees cache size: " + ps.size());
if (ps.size() > 0) {
return ps.stream().collect(Collectors.toList());
}
logger.info("Employees find");
List < Employee > e = repository.findByCompany(company);
logger.info("Employees size: " + e.size());
e.parallelStream().forEach(it -> {
map.putIfAbsent(it.getId(), it);
});
return e;
}
public Employee findById(Integer id) {
Employee e = map.get(id);
if (e != null)
return e;
e = repository.findOne(id);
map.put(id, e);
return e;
}
public Employee add(Employee e) {
e = repository.save(e);
map.put(e.getId(), e);
return e;
}
}If you are interested in running a sample application, you can clone my repository on GitHub. In the person-service module, there is an example of my previous article about Hibernate second cache with Hazelcast. In employee-module , there is an example for this article.
Testing
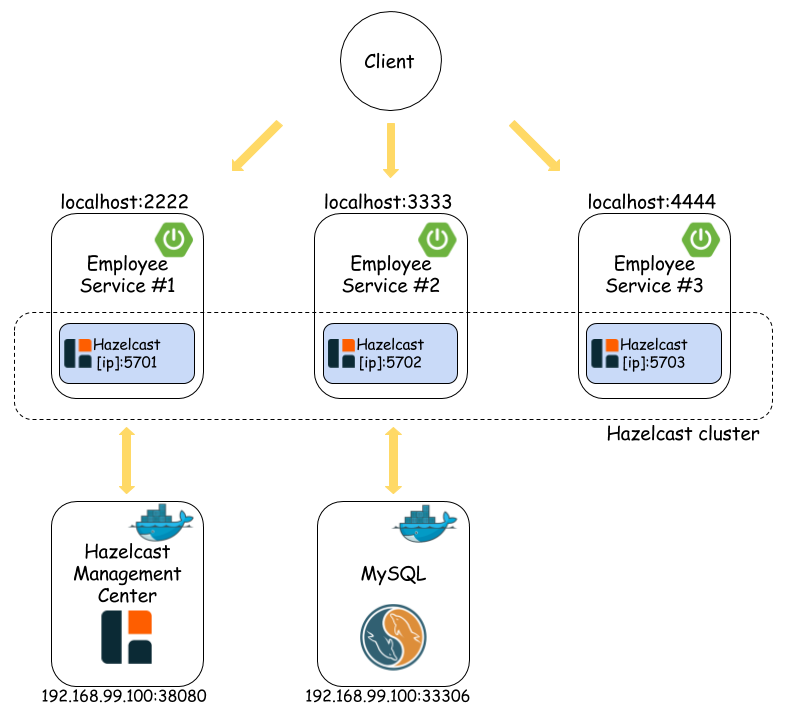
Let’s start three instances of employee service on different ports using the VM argument -DPORT. In the first figure visible in the beginning of the article, these ports are 2222, 3333, and 4444. When starting the last third service’s instance, you should see the fragment visible below in the application logs. It means that a Hazelcast cluster of three members has been set up.
2017 - 05 - 09 23: 01: 48.127 INFO 16432-- - [ration.thread - 0] c.h.internal.cluster.ClusterService: [192.168 .1 .101]: 5703[dev][3.7 .7]
Members[3] {
Member[192.168 .1 .101]: 5701 - 7 a8dbf3d - a488 - 4813 - a312 - 569 f0b9dc2ca
Member[192.168 .1 .101]: 5702 - 494 fd1ac - 341 b - 451 c - b585 - 1 ad58a280fac
Member[192.168 .1 .101]: 5703 - 9750 bd3c - 9 cf8 - 48 b8 - a01f - b14c915937c3 this
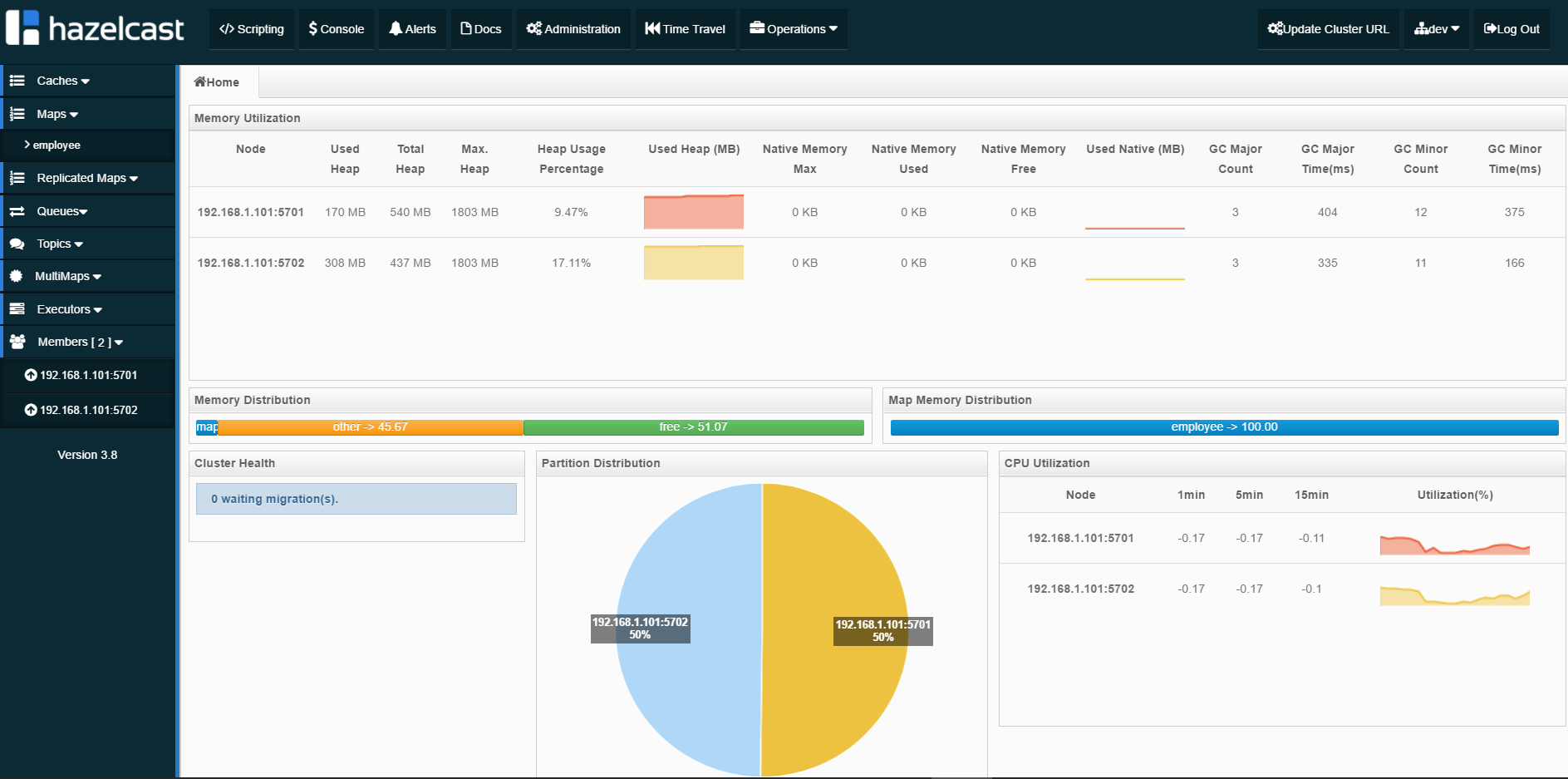
}Here is a picture from the Hazelcast Management Center for two running members (only two members are available in the freeware version of Hazelcast Management Center).
Then, run Docker containers with MySQL and Hazelcast Management Center.
docker run -d --name mysql -p 33306:3306 mysql
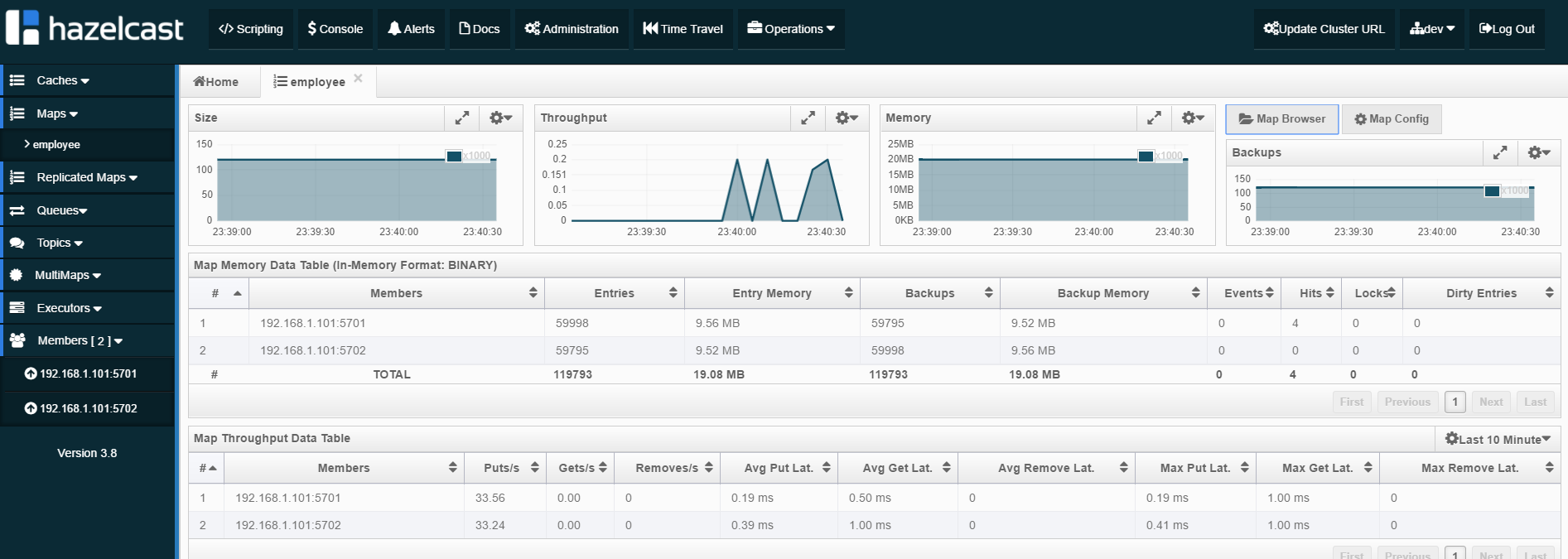
docker run -d --name hazelcast-mgmt -p 38080:8080 hazelcast/management-center:latestNow, you could try to call endpoint http://localhost:/employees/company/{company} on all of your services. You should see that data is cached in the cluster and even if you call the endpoint on a different service, it find entities put into the cache by different services. After several attempts, my service instances put about 100k entities into the cache. Distribution between two Hazelcast members is 50% to 50%.
Final Words
We could probably implement a smarter solution, but I just wanted to show you the idea. I tried to use Spring Data Hazelcast for that, but I’ve got a problem with running it on Spring Boot application. It has a HazelcastRepository interface, which is something similar to Spring data CrudRepository but is based on cached entities in Hazelcast grid and also uses the Spring data KeyValue module. The project is not well-documented and like I said before, it didn’t work with Spring Boot, so I decided to implement my simple solution!
In my local environment, which was visualized in the beginning of the article, queries on the cache were about 10 times faster than similar queries on the database. I inserted 2M records into the employee table. Hazelcast data grid could not only be a second-level cache but even a middleware between your application and database. If your priority is a performance of queries on large amounts of data and you have a lot of RAM, an in-memory data grid is the right solution for you!
Published at DZone with permission of Piotr Mińkowski. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments