Best Performance Practices for Hibernate 5 and Spring Boot 2 (Part 4)
Learn more about improving your performance in Hibernate 5 and Spring Boot 2 applications.
Join the DZone community and get the full member experience.
Join For FreePart 1 is available here (recipes from 1 to 25).
Part 2 is available here (recipes from 26 to 51).
Part 3 is available here (recipes from 52 to 77)
Note: Reading this part is not imposing reading the first three as well!
If you liked the first three parts of this article, then I am sure that you will enjoy this part as well. Mainly, we continue in the same manner and tackle some persistence layer performance issues via Spring Boot applications. Moreover, for a detailed explanation of 150+ performance items check out my book, Spring Boot Persistence Best Practices. This book helps every Spring Boot developer to squeeze the performances of the persistence layer.

Item 78: The Best Way To Publish Domain Events From Aggregate Root
Description: Starting with Spring Data Ingalls release publishing domain events by aggregate roots becomes easier. Entities managed by repositories are aggregate roots. In a Domain-Driven Design application, these aggregate roots usually publish domain events. Spring Data provides an annotation @DomainEvents you can use on a method of your aggregate root to make that publication as easy as possible.
A method annotated with @DomainEvents is automatically invoked by Spring Data whenever an entity is saved using the right repository. Moreover, Spring Data provides the @AfterDomainEventsPublication annotation to indicate the method that should be automatically called for clearing events after publication.
Spring Data Commons comes with a convenient template base class (AbstractAggregateRoot) to help to register domain events and is using the publication mechanism implied by @DomainEventsand @AfterDomainEventsPublication. The events are registered by calling the AbstractAggregateRoot.registerEvent() method. The registered domain events are published if we call one of the save methods (e.g., save()) of the Spring Data repository and cleared after publication.
This is a sample application that relies on AbstractAggregateRoot and its registerEvent() method. We have two entities, Book and BookReview, involved in a lazy-bidirectional @OneToMany association. A new book review is saved in CHECK status, and a CheckReviewEvent is published. This event handler is responsible to check the review grammar, content, etc and switch the review status from CHECK to ACCEPT or REJECT and propagate the new status to the database. So, this event is registered before saving the book review in CHECK status and is published automatically after we call the BookReviewRepository.save() method. After publication, the event is cleared.
Key points:
- The entity (aggregate root) that publish events should extend
AbstractAggregateRootand provide a method for registering events. - Here, we register a single event (
CheckReviewEvent), but more can be registered. - Event handling takes place is
CheckReviewEventHandlerin an asynchronous manner via@Async
Source code can be found here.
Item 79: How to Use Hibernate Query Plan Cache
Description: This application is an example of testing the Hibernate Query Plan Cache (QPC). Hibernate QPC is enabled by default and, for entity queries (JPQL and Criteria API), the QPC has a size of 2048, while for native queries it has a size of 128. Pay attention to alter these values to accommodate all queries executed by your application. If the number of executed queries is higher than the QPC size (especially for entity queries), then you will start to experiment performance penalties caused by entity compilation time added for each query execution.
In this application, you can adjust the QPC size in application.properties. Mainly, there are 2 JPQL queries and a QPC of size 2. Switching from size 2 to size 1 will cause the compilation of one JPQL query at each execution. Measuring the times for 5,000 executions using a QPC of size 2, respectively 1, reveals the importance of QPC in terms of time.
Key points:
- For JPQL and Criteria API you can set the QPC via
hibernate.query.plan_cache_max_size - For native queries you can set the QPC via
hibernate.query.plan_parameter_metadata_max_size
Source code can be found here.
Item 80: How to Cache Entities and Query Results in Second-Level Cache (EhCache)
Description: This is a SpringBoot application that enables Hibernate Second Level Cache and EhCache provider. It contains an example of caching entities and an example of caching a query result.
Key points:
- enable Second Level Cache (
EhCache) - rely on
@Cache - relying on JPA hint
HINT_CACHEABLE
Source code can be found here.
Item 81: How to Load Multiple Entities by Id via Specification
Description: This is a SpringBoot application that loads multiple entities by id via a @Query based on the IN operator and via Specification.
Key points:
- for using the
INoperator in a@Querysimply add the query in the proper repository - for using a
Specificationrely onjavax.persistence.criteria.Root.in()
Source code can be found here.
Item 82: How to Fetch DTO via a Custom ResultTransformer
Description: Fetching more read-only data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use a SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]>, and most probably, you will need to represent it as a List<ParentDto>, where a ParentDto instance has a List<ChildDto>. For such cases, we can rely on a custom Hibernate ResultTransformer. This application is a sample of writing a custom ResultTransformer.
Key points:
- implement the
ResultTransformerinterface
Source code can be found here.
Item 83: How to Implement Complex Data Integrity Constraints and Rules
Description: Consider the Book and Chapter entities. A book has a maximum accepted number of pages (book_pages), and the author should not exceed this number. When a chapter is ready for review, the author is submitting it. At this point, the publisher should check that the current total number of pages doesn't exceed the allowed book_pages:
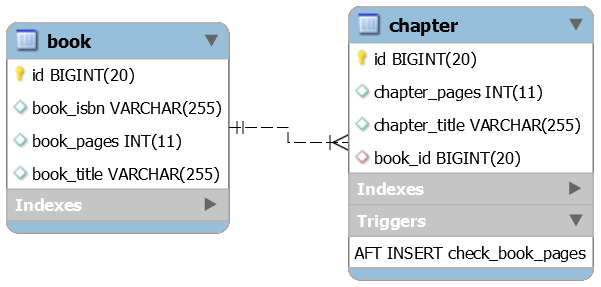
These kinds of checks or constraints are easy to implement via database triggers. This application relies on a MySQL trigger to empower our complex constraint (check_book_pages).
Key points:
- define a MySQL trigger that runs after each insert (if you want to run it after each update as well then extract the trigger logic into a function and call it from two triggers — this is specific to MySQL, while is PostgreSQL we have
AFTER INSERT OR AFTER UPDATE)
Source code can be found here.
Item 84: How to Check if a Transient Entity Exists in the Database via Spring Query by Example (QBE)
Description: This application is an example of using Spring Data Query By Example (QBE) to check if a transient entity exists in the database. Consider the Book entity and a Spring controller that exposes an endpoint as:
public String checkBook(@Validated @ModelAttribute Book book, ...)
Besides writing an explicit JPQL, we can rely on the Spring Data Query Builder mechanism or, even better, on Query By Example (QBE) API. In this context, QBE API is quite useful if the entity has a significant number of attributes and:
- for all attributes, we need a head-to-head comparison of each attribute value to the corresponding column value
- for a subset of attributes, we need a head-to-head comparison of each attribute value to the corresponding column value
- for a subset of attributes, we return true at the first match between an attribute value and the corresponding column value
- any other scenario
Key points:
- the repository,
BookRepositoryextendsQueryByExampleExecutor - the application uses
<S extends T> boolean exists(Example<S> exmpl)with the proper probe (an entity instance populated with the desired fields values) - moreover, the probe relies on
ExampleMatcherwhich defines the details on how to match particular fields
Note: Do not conclude that Query By Example (QBE) defines only the exists() method. Check out all methods here.
Source code can be found here.
Item 85: How to Use JPA JOINED Inheritance Strategy and Visitor Design Pattern
Description: This application is an example of using JPA JOINED inheritance strategy and Visitor pattern.
Key points:
- this application allows us to define multiple visitors and apply the one that we want
Source code can be found here.
Item 86: How to Use JPA JOINED Inheritance Strategy and Strategy Design Pattern
Description: This application is an example of using JPA JOINED inheritance strategy and Strategy pattern.
Key points:
- this application allows us to define multiple strategies and apply the one that we want
Source code can be found here.
Item 87: How Spring Transaction Propagation Work
Description: This folder holds several applications that show how each Spring transaction propagation works.
Source code can be found here.
Item 88: How to Use JPA GenerationType.AUTO and UUID Identifiers
Description: This application is an example of using the JPA GenerationType.AUTO for assigning automatically UUID identifiers.
Key points:
- store UUID in a
BINARY(16)column
Source code can be found here.
Item 89: How to Manually Assign UUID Identifiers
Description: This application is an example of manually assigning UUID identifiers.
Key points:
- store UUID in a
BINARY(16)column
Source code can be found here.
Item 90: How to Use Hibernate uuid2 for Generating UUID Identifiers
Description: This application is an example of using the Hibernate RFC 4122 compliant UUID generator, uuid2.
Key points:
- store UUID in a
BINARY(16)column
Source code can be found here.
Item 91: How Hibernate Session-Level Repeatable Reads Works
Description: This Spring Boot application is a sample that reveals how the Hibernate session-level repeatable reads work. Persistence Context guarantees session-level repeatable reads. Check out how it works.
Key points:
- rely on two transactions implemented via
TransactionTemplate
Note: For a detailed explanation of this application consider my book, Spring Boot Persistence Best Practices
Source code can be found here.
Item 92: Why to Avoid Hibernate-specific hibernate.enable_lazy_load_no_trans
Description: This application is an example of using Hibernate-specific hibernate.enable_lazy_load_no_trans. Check out the application log to see how transactions and database connections are used.
Key points:
- always avoid Hibernate-specific
hibernate.enable_lazy_load_no_trans
Source code can be found here.
Item 93: The Best Way to Clone Entities
Description: This application is an example of cloning entities. The best way to achieve this goal relies on copy-constructors. This way, we can control what we copy. Here, we use a bidirectional-lazy @ManyToMany association between Author and Book.
Key points:
- clone an
Author(only thegenre) and associate the corresponding books - clone an
Author(only thegenre) and clone the books as well
Source code can be found here.
Item 94: How to Include in the UPDATE Statement Only the Modified Columns via Hibernate @DynamicUpdate
Description: This application is an example of using the Hibernate-specific, @DynamicUpdate. By default, even if we modify only a subset of columns, the triggered UPDATE statements will include all columns. By simply annotating the corresponding entity at class-level with @DynamicUpdate, the generated UPDATE statement will include only the modified columns.
Key points:
- pro: avoid updating unmodified indexes (useful for heavy indexing)
- con: cannot reuse the same
UPDATEfor different subsets of columns via JDBC statements caching (each triggeredUPDATEstring will be cached and reused accordingly)
Source code can be found here.
Item 95: How to Log Spring Data JPA Repository Query-Method Execution Time
Description: This application is an example of logging execution time for a repository query-method.
Key points:
- write an AOP component (see
RepositoryProfiler)
Source code can be found here.
Item 96: How to Take Control Before/After Transaction Commits/Completes via Callbacks
Description: This application is an example of using the TransactionSynchronizationAdapter for overriding beforeCommit(), beforeCompletion(), afterCommit(), and afterCompletion() callbacks globally (application-level) and at method-level.
Key points:
- application-level: write an AOP component (see
TransactionProfiler) - method-level: use
TransactionSynchronizationManager.registerSynchronization()
Source code can be found here.
Item 97: How to Fetch Entity Via SqlResultSetMapping And NamedNativeQuery Using {EntityName}.{RepositoryMethodName} Naming Convention
Description: This is a sample application of using SqlResultSetMapping, NamedNativeQuery and EntityResult for fetching single entity and multiple entities as List<Object[]>. In this application, we rely on the {EntityName}.{RepositoryMethodName} naming convention. This convention allows us to create in the repository interface methods with the same name as of native named query.
Key points:
- use
SqlResultSetMapping,NamedNativeQueryandEntityResult
Source code can be found here.
Check also:
Item 98: How To Use JPA Named Queries @NamedQuery And Spring Projection (DTO)
Item 99: How To Use JPA Named Native Queries @NamedNativeQuery And Spring Projection (DTO)
Item 100: How To Use JPA Named Queries Via a Properties File
Item 101: How To Use JPA Named Queries Via The orm.xml File
Item 102: How To Use JPA Named Queries Via Annotations
Item 103: How To Use JPA Named Queries Via Properties File And Spring Projection (DTO)
Item 104: How To Use JPA Named Native Queries Via Properties File And Spring Projection (DTO)
Item 105: How To Use JPA Named Queries Via orm.xml File And Spring Projection (DTO)
Item 106: How To Use JPA Named Native Queries Via orm.xml File And Spring Projection (DTO)
Item 107: How To DTO Via Named Native Query And Result Set Mapping Via orm.xml
Item 108: How to Use Spring Projections(DTO) and Cross Joins

Description: This application is a proof of concept for using Spring Projections (DTO) and cross joins written via JPQL and native SQL (for MySQL).
Key points:
- define two entities (e.g.,
BookandFormat) - populate the database with some test data (e.g., check the file
resources/data-mysql.sql) - write interfaces (Spring projections) that contains getters for the columns that should be fetched from the database (e.g., check
BookTitleAndFormatType.java) - write cross joins queries using JPQL/SQL
Source code can be found here.
Item 109: Calling Stored Procedure That Returns a Result Set via JdbcTemplate and BeanPropertyRowMapper
Description: This application is an example of calling a MySQL stored procedure that returns a result set via JdbcTemplate and BeanPropertyRowMapper.
Key points:
- rely on
JdbcTemplate,SimpleJdbcCall, andBeanPropertyRowMapper
Source code can be found here.
Item 110: Defining Entity Listener Class via @EntityListeners
Description: This application is a sample of using the JPA @MappedSuperclass and @EntityListeners with JPA callbacks.
Key points:
- the base class ,
Book, is not an entity, it can beabstract, and is annotated with@MappedSuperclassand@EntityListeners(BookListener.class) BookListenerdefines JPA callbacks (e.g.,@PrePersist)- subclasses of the base class are mapped in tables that contain columns for the inherited attributes and for their own attributes
- when any entity that is a subclass of
Bookis persisted, loaded, updated, etc the corresponding JPA callbacks are called
Source code can be found here.
Item 111: Improper Usage of @Fetch(FetchMode.JOIN) May Cause N+1 Issues
Advice: Always evaluate JOIN FETCH and entities graphs before deciding to use FetchMode.JOIN. The FetchMode.JOIN fetch mode always triggers an EAGER load so the children are loaded when the parents are. Besides this drawback, FetchMode.JOIN may return duplicate results. You’ll have to remove the duplicates yourself (e.g. storing the result in a Set). But, if you decide to go with FetchMode.JOIN at least pay attention to avoid N+1 issues discussed below.
Note: Let's assume three entities, Author, Book, and Publisher. Between Author and Book, there is a bidirectional-lazy @OneToMany association. Between Author and Publisher, there is a unidirectional-lazy @ManyToOne. Between Book and Publisher, there is no association.
Now, we want to fetch a book by id (BookRepository#findById()), including its author, and the author's publisher. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN), works as expected. Using JOIN FETCH or entity graph is also working as expected.
Next, we want to fetch all books (BookRepository#findAll()), including their authors and the author's publishers. In such cases, using Hibernate fetch mode, @Fetch(FetchMode.JOIN), will cause N+1 issues. It will not trigger the expected JOIN. In this case, using JOIN FETCH or entity graph should be used.
Key points:
- using Hibernate fetch mode,
@Fetch(FetchMode.JOIN)doesn't work for query-methods - Hibernate fetch mode,
@Fetch(FetchMode.JOIN), works in cases that fetch the entity by id (primary key), like usingEntityManager#find(), Spring Data,findById(), andfindOne().
Source code can be found here.
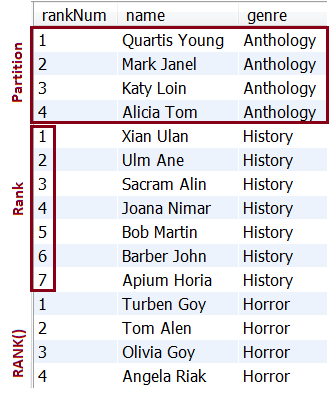
Item 112: How to Efficiently Assign A Database Temporary Ranking of Values To Rows via RANK()
Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, RANK(). This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
- commonly, you don't need to fetch in the result set the temporary ranking of values produced by
RANK()(you will use it internally, in the query, usually in theWHEREclause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated byRANK()as well - write several native queries relying on
RANK()window function
Output sample:
Source code can be found here.
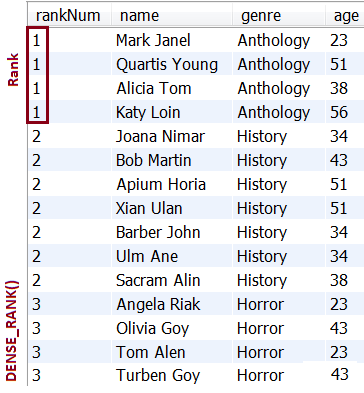
Item 113: How to Efficiently Assign a Database Temporary Ranking of Values to Rows via DENSE_RANK()
Description: This application is an example of assigning a database temporary ranking of values to rows via the window function, DENSE_RANK(). In comparison with the RANK() window function, DENSE_RANK() avoid gaps within the partition. This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
- commonly, you don't need to fetch in the result set the temporary ranking of values produced by
DENSE_RANK()(you will use it internally, in the query, usually in theWHEREclause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated byDENSE_RANK()as well - write several native queries relying on
DENSE_RANK()window function
Output sample:
Source code can be found here.
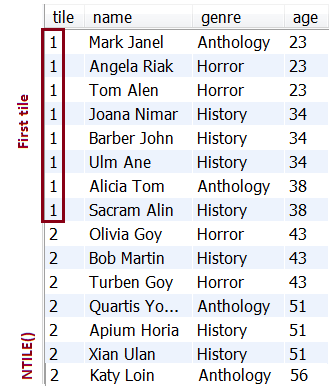
Item 114: How to Efficiently Distribute the Number of Rows in the Specified (N) Number of Groups via NTILE(N)
Description: This application is an example of distributing the number of rows in the specified (N) number of groups via the window function, NTILE(N). This window function is available in almost all databases, and starting with version 8.x is available in MySQL as well.
Key points:
- commonly, you don't need to fetch in the result set the temporary ranking of values produced by
NTILE()(you will use it internally, in the query, usually in theWHEREclause and CTEs), but, this time, let's write a Spring projection (DTO) that contains a getter for the column generated byNTILE()as well - write several native queries relying on
NTILE()window function
Output sample:
Source code can be found here.
Item 115: How to Write Derived Count and Delete Queries
Description: Spring Data comes with the Query Builder mechanism for JPA that is capable to interpret a query method name (known as a derived query) and convert it into a SQL query in the proper dialect. This is possible, as long as we respect the naming conventions of this mechanism. Besides the well-known query of type find..., Spring Data supports derived count queries and derived delete queries.
Key points:
- a derived count query starts with
count...(e.g.,long countByGenre(String genre)) - Spring Data will generate aSELECT COUNT(...) FROM ...query - a derived delete query can return the number of deleted records or the list of the deleted records
- a derived delete query that returns the number of deleted records starts with
delete...orremove...and returnslong(e.g.,long deleteByGenre(String genre)) — Spring Data will trigger first aSELECTto fetch entities in the Persistence Context, and, afterward, it triggers aDELETEfor each entity that must be deleted - a derived delete query that returns the list of deleted records starts with
delete...orremove...and returnsList<entity>(e.g.,List<Author> removeByGenre(String genre)) - Spring Data will trigger first aSELECTto fetch entities in the Persistence Context, and, afterward, it triggers aDELETEfor each entity that must be deleted
Source code can be found here.
Item 116: Working With Spring Data Property Expressions
Description: Property expressions can refer to a direct property of the managed entity. However, you can also define constraints by traversing nested properties. This application is a sample of traversing nested properties for fetching entities and DTOs.
Key points:
- Assume an
Authorhas severalBookand each book has severalReview(betweenAuthorandBookthere is a bidirectional-lazy@oneToManyassociation, and, betweenBookandReviewthere is also a bidirectional-lazy@OneToManyassociation) - Assume that we fetched a
Reviewand we want to know theAuthorof theBookthat has received thisReview - via property expressions, we can write in
AuthorRepositorythe following query that will be processed by the Spring Data Query Builder mechanism:Author findByBooksReviews(Review review); - Behind the scene, Spring Data will produce a
SELECTwith twoLEFT JOIN - In this case, the method creates the property traversal
books.reviews. The algorithm starts by interpreting the entire part (BooksReviews) as the property and checks the domain class for a property with that name (uncapitalized). If the algorithm succeeds, it uses that property. If not, the algorithm splits up the source at the camel case parts from the right side into a head and a tail and tries to find the corresponding property — in our example,BooksandReviews. If the algorithm finds a property with that head, it takes the tail and continues building the tree down from there, splitting the tail up in the way just described. If the first split does not match, the algorithm moves the split point to the left and continues. - Although this algorithm should work in most cases, it is possible for the algorithm to select the wrong property. Suppose the
Authorclass has anbooksReviewproperty as well. The algorithm would match in the first split round already, choose the wrong property, and fail (as the type ofbooksReviewprobably has no code property). To resolve this ambiguity you can use _ inside your method name to manually define traversal points. So our method name would be as follows:Author findByBooks_Reviews(Review review); - More examples (including DTOs) are available in the application
Source code can be found here.
Item 117: The Best Way to Fetch Parent and Children in Different Queries
Note: Fetching read-only data should be done via DTO, not managed entities. But, there is no tragedy to fetch read-only entities in a context as follows:
- we need all attributes of the entity (so, a DTO just mirrors an entity)
- we manipulate a small number of entities (e.g., an author with several books)
- we use
@Transactional(readOnly = true)
Under these circumstances, let's tackle a common case that I saw quite a lot. There is even an SO answer about it (don't do this):

Description: Let's assume that Author and Book are involved in a bidirectional-lazy @OneToMany association. Imagine a user that loads a certain Author (without the associated Book). The user may be interested or not in the Book, therefore, we don't load them with the Author. If the user is interested in the Book, then he will click a button of type, View books. Now, we have to return the List<Book> associated with this Author.
So, at first request (query), we fetch an Author. The Author is detached. At the second request (query), we want to load the Book associated with this Author. But, we don't want to load the Author again (for example, we don't care about lost updates of Author), we just want to load the associated Book in a single SELECT.
A common (not recommended) approach is to load the Author again (e.g., via findById(author.getId())) and call the author.getBooks(). But, this ends up in two SELECT statements. One SELECT for loading the Author, and another SELECT after we force the collection initialization. We force collection initialization because it will not be initialized if we simply return it. In order to trigger the collection initialization, the developer call books.size(), or he relies on Hibernate.initialize(books);.
But, we can avoid such a solution by relying on explicit JPQL or Query Builder property expressions. This way, there will be a single SELECT and no need to call size() or Hibernate.initialize();
Key points:
- use an explicit JPQL
- use Query Builder property expressions
Source code can be found here.
Item 118: How to Optimize the Merge Operation Using Update
Description: Behind the built-in Spring Data save(), there is a call of EntityManager#persist() or EntityManager#merge(). It is important to know this aspect in several cases. Among these cases, we have the entity update case (simple update or update batching).
Consider Author and Book involved in a bidirectional-lazy @OneToMany association. And, we load an Author, detach it, update it in the detached state, and save it to the database via save() method. Calling save() will come with the following two issues resulting from calling merge() behind the scene:
- there will be two SQL statements, one
SELECT(merge) and oneUPDATE - the
SELECTwill contain aLEFT OUTER JOINto fetch the associatedBookas well (we don't need the books!)
How about triggering only the UPDATE instead of this? The solution relies on calling Session#update(). Calling Session.update() requires to unwrap the Session via entityManager.unwrap(Session.class).
Key points:
- calling
Session.update()will trigger only theUPDATE(there is noSELECT) Session.update()works with the versioned optimistic locking mechanism as well (so, lost updates are prevented)
Source code can be found here.
Item 119: How uo NOT Use Spring Data Streamable
Description: This application is a sample of fetching Streamable<entity> and Streamable<dto>. But, more importantly, this application contains three examples of how to not use Streamable. It is very tempting and comfortable to fetch a Streamable result set and chop it via filter(), map(), flatMap(), and so on until we obtain only the needed data instead of writing a query (e.g., JPQL) that fetches exactly the needed result set from the database. Mainly, we just throw away some of the fetched data to keep only the needed data. But, is not advisable to follow such practices because fetching more data than needed can cause significant performance penalties.
Moreover, pay attention to combining two or more Streamable via the and() method. The returned result may be different from what you are expecting to see. Each Streamable produces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values).
Key points:
- don't fetch more columns than needed just to drop a part of them (e.g., via
map()) - don't fetch more rows than needed just to throw away a part of it (e.g., via
filter()) - pay attention to combining
Streamableviaand(); eachStreamableproduces a separate SQL statement and the final result set is a concatenation of the intermediate results sets (prone to duplicate values)
Source code can be found here.
Item 120: How to Return Custom Streamable Wrapper Types
Description: A common practice consists of exposing dedicated wrappers types for collections resulted after mapping a query result set. This way, on single query execution, the API can return multiple results. After we call a query-method that returns a collection, we can pass it to a wrapper class by manual instantiation of that wrapper-class. But, we can avoid the manual instantiation if the code respects the following key points.
Key points:
- the type implements
Streamable - the type exposes a constructor (used in this example) or a
staticfactory method namedof(…)orvalueOf(…)takingStreamableas argument
Source code can be found here.
Item 121: How to Use in Spring Boot JPA 2.1 Schema Generation and Data Loading
Description: JPA 2.1 come with schema generation features. This feature can setup the database or export the generated commands to a file. The parameters that we should set are:
spring.jpa.properties.javax.persistence.schema-generation.database.action: Instructs the persistence provider on how to set up the database. Possible values include:none,create,drop-and-create,dropjavax.persistence.schema-generation.scripts.action: Instruct the persistence provider which scripts to create. Possible values include:none,create,drop-and-create,drop.javax.persistence.schema-generation.scripts.create-target: Indicate the target location of the create script generated by the persistence provider. This can be as a file URL or ajava.IO.Writer.javax.persistence.schema-generation.scripts.drop-target: Indicate the target location of the drop script generated by the persistence provider. This can be as a file URL or ajava.IO.Writer.
Moreover, we can instruct the persistence provider to load data from a file into the database via: spring.jpa.properties.javax.persistence.sql-load-script-source. The value of this property represents the file location and it can be a file URL or a java.IO.Writer.
Key points:
- the settings are available in
application.properties
Source code can be found here.
Item 122: How to Return a Map Result From a Spring Data Query Method
Description: Sometimes, we need to write in repositories certain query-methods that return a Map instead of a List or a Set. For example, when we need a Map<Id, Entity> or we use GROUP BY and we need a Map<Group, Count>. This application shows you how to do it via default methods directly in the repository.
Key points:
- rely on
defaultmethods andCollectors.toMap()
Source code can be found here.
Item 123: How to Handle Entities Inheritance With Spring Data Repositories
Description: Consider one of the JPA inheritance strategies (e.g., JOINED). Handling entities inheritance With Spring Data repositories can be done as follows:
Item 124: Log Slow Queries via Hibernate 5.4.5
Description: This application is a sample of logging only slow queries via Hibernate 5.4.5, hibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS property. A slow query is a query that has an execution time bigger than a specified threshold in milliseconds.
Key points:
- in
application.propertiesaddhibernate.session.events.log.LOG_QUERIES_SLOWER_THAN_MS
Output example: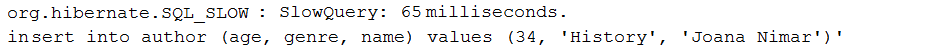
Source code can be found here.
Item 125: DTO via JDK14 Records and Spring Data Query Builder Mechanism
Description: Fetching more data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. In this application, we rely on JDK14 Records feature and Spring Data Query Builder Mechanism.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points: Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
Source code can be found here.
Item 126: How to Fetch DTO via JDK14 Records, Constructor Expression and JPQL
Description: Fetching more data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. In this application, we rely on JDK 14 Records, Constructor Expression, and JPQL.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
Define the AuthorDto as:
public record AuthorDto(String name, int age) implements Serializable {}
Source code can be found here.
Item 127: How to Fetch DTO via JDK14 Records and a Custom ResultTransformer
Description: Fetching more read-only data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. Sometimes, we need to fetch a DTO made of a subset of properties (columns) from a parent-child association. For such cases, we can use SQL JOIN that can pick up the desired columns from the involved tables. But, JOIN returns an List<Object[]> and most probably you will need to represent it as a List<ParentDto>, where a ParentDto instance has a List<ChildDto>. For such cases, we can rely on a custom Hibernate ResultTransformer. This application is a sample of writing a custom ResultTransformer.
As DTO, we rely on JDK 14 Records. From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
- define Java Records as
AuthorDtoandBookDto - implement the
ResultTransformerinterface
Source code can be found here.
Item 128: DTO via JDK14 Records, JdbcTemplate, and ResultSetExtractor
Description: Fetching more data than needed is prone to performance penalties. Using DTO allows us to extract only the needed data. In this application, we rely on JDK14 Records feature, JdbcTemplate and ResultSetExtractor.
From Openjdk JEP359:
Records provide a compact syntax for declaring classes which are transparent holders for shallowly immutable data.
Key points:
- define Java Records as
AuthorDtoandBookDto - use
JdbcTemplateandResultSetExtractor
Source code can be found here.
Done! If you liked this article then I'm sure that you'll love my book, Spring Boot Persistence Best Practices as well. This book is dedicated to any Spring and Spring Boot developer that wants to squeeze the persistence layer performances.
Opinions expressed by DZone contributors are their own.
Comments