Manual Sharding in PostgreSQL: A Step-by-Step Implementation Guide
Implement manual PostgreSQL sharding with simple SQL routing functions and measure performance gains through benchmarking.
Join the DZone community and get the full member experience.
Join For FreeLearn how to implement manual sharding in native PostgreSQL using Foreign Data Wrappers. This tutorial walks through creating distributed tables without additional extensions like Citus.
The Challenge With Database Scaling
As applications grow, single-node databases face several challenges:
- Limited storage capacity on a single machine
- Query performance degradation with growing datasets
- Higher concurrency demands exceeding CPU capabilities
- Difficulty maintaining acceptable latency for global users
Sharding — horizontally partitioning data across multiple database nodes — offers a solution to these scaling problems.
Why Manual Sharding in PostgreSQL?
While solutions like Citus and other distributed database systems exist, there are compelling reasons to implement manual sharding:
- More control: Customize the sharding logic to your specific application needs.
- No additional dependencies: Utilize only native PostgreSQL features.
- Learning opportunity: Gain a deeper understanding of distributed database concepts.
- Incremental adoption: Apply sharding only to specific high-volume tables.
- Cloud-agnostic: Implement your solution on any infrastructure.
Setting Up Our Sharded Architecture
Let's implement a simplified manual sharding approach that works with a single PostgreSQL instance. This makes it easier to test and understand the concept before potentially scaling to multiple instances.
Step 1: Create Sharded Tables
First, let's create our sharded tables in a single PostgreSQL database:
CREATE TABLE users_shard1 (
id BIGINT PRIMARY KEY,
name TEXT
);
CREATE TABLE users_shard2 (
id BIGINT PRIMARY KEY,
name TEXT
);Note that we're using the BIGINT type for IDs to better handle large data volumes.
Step 2: Index the Shards for Better Performance
Adding indexes improves query performance, especially for our routing functions:
CREATE INDEX idx_user_id_shard1 ON users_shard1(id);Step 3: Implement Insert Function With Routing Logic
This function routes data to the appropriate shard based on a simple modulo algorithm:
CREATE OR REPLACE FUNCTION insert_user(p_id BIGINT, p_name TEXT)
RETURNS VOID AS $
BEGIN
IF p_id % 2 = 0 THEN
INSERT INTO users_shard2 VALUES (p_id, p_name);
ELSE
INSERT INTO users_shard1 VALUES (p_id, p_name);
END IF;
END;
$ LANGUAGE plpgsql;Step 4: Create Read Function With Routing Logic
For reading data, we'll create a function that routes queries to the appropriate shard:
CREATE OR REPLACE FUNCTION read_user(p_id BIGINT)
RETURNS TABLE(id BIGINT, name TEXT) AS $
BEGIN
IF p_id % 2 = 0 THEN
RETURN QUERY SELECT u.id::BIGINT, u.name FROM users_shard2 u WHERE u.id = p_id;
ELSE
RETURN QUERY SELECT u.id::BIGINT, u.name FROM users_shard1 u WHERE u.id = p_id;
END IF;
END;
$ LANGUAGE plpgsql;Notice we use aliasing and explicit casting to handle any potential type mismatches.
Step 5: Create a Unified View (Optional)
To make queries transparent, create a view that unions the sharded tables:
CREATE VIEW users AS
SELECT * FROM users_shard1
UNION ALL
SELECT * FROM users_shard2;Step 6: Testing Our Sharded System
Let's test our system with a few simple inserts:
SELECT insert_user(1, 'Alice');
SELECT insert_user(2, 'Bob');
SELECT insert_user(3, 'Carol');
SELECT insert_user(4, 'Dave');Now, read the data using our routing function:
SELECT * FROM read_user(1);
SELECT * FROM read_user(2);Or query all data using the unified view:
SELECT * FROM users ORDER BY id;Benchmarking Our Sharding Implementation
Let's benchmark our implementation to understand the performance characteristics. We'll use Python scripts to test both insertion and read performance.
Python Benchmark Script for Inserts (Sharded)
Here's the script for benchmarking inserts into our sharded tables (seed_pg_sharded.py):
import psycopg2
from time import time
conn = psycopg2.connect("dbname=postgres user=postgres password=secret host=localhost port=5432")
cur = conn.cursor()
start = time()
for i in range(4, 100_001):
cur.execute("SELECT insert_user(%s, %s)", (i, f'user_{i}'))
conn.commit()
end = time()
print("Sharded insert time:", end - start)Python Benchmark Script for Inserts (Single Table)
For comparison, we'll also test insertion performance on a single table (seed_pg_single.py):
import psycopg2
from time import time
conn = psycopg2.connect("dbname=postgres user=postgres password=secret host=localhost port=5432")
cur = conn.cursor()
start = time()
for i in range(100_001, 100_001 + 500_000):
cur.execute("INSERT INTO users_base VALUES (%s, %s)", (i, f'user_{i}'))
conn.commit()
end = time()
print("Single-node insert time:", end - start)Python Benchmark Script for Reads
Finally, we'll compare read performance between the single table and our sharded implementation (read_bench.py):
import psycopg2
from time import time
# Configs
conn = psycopg2.connect("dbname=postgres user=postgres password=secret host=localhost port=5432")
def time_reads(cur, query, param_fn, label):
start = time()
for i in range(1000, 2000): # Run 1000 point queries
cur.execute(query, (param_fn(i),))
cur.fetchall()
end = time()
print(f"{label}: {end - start:.3f} sec for 1000 point reads")
# Benchmark single table
with conn.cursor() as cur:
print("Benchmarking Point Reads on Single Table")
time_reads(cur, "SELECT * FROM users WHERE id = %s", lambda x: x, "Single Table")
# Benchmark sharded read_user function
with conn.cursor() as cur:
print("\nBenchmarking Point Reads via read_user() Function")
time_reads(cur, "SELECT * FROM read_user(%s)", lambda x: x, "Sharded Function")
conn.close()Adding Range Read Functionality
For more complex queries, we can add a function to read a range of IDs:
CREATE OR REPLACE FUNCTION read_user_range(start_id BIGINT, end_id BIGINT)
RETURNS TABLE(id BIGINT, name TEXT) AS $
BEGIN
-- Query from both shards and union the results
RETURN QUERY
(SELECT u.id::BIGINT, u.name
FROM users_shard1 u
WHERE u.id BETWEEN start_id AND end_id)
UNION ALL
(SELECT u.id::BIGINT, u.name
FROM users_shard2 u
WHERE u.id BETWEEN start_id AND end_id)
ORDER BY id;
END;This function allows us to read a range of users across both shards in a single query.
Performance Observations
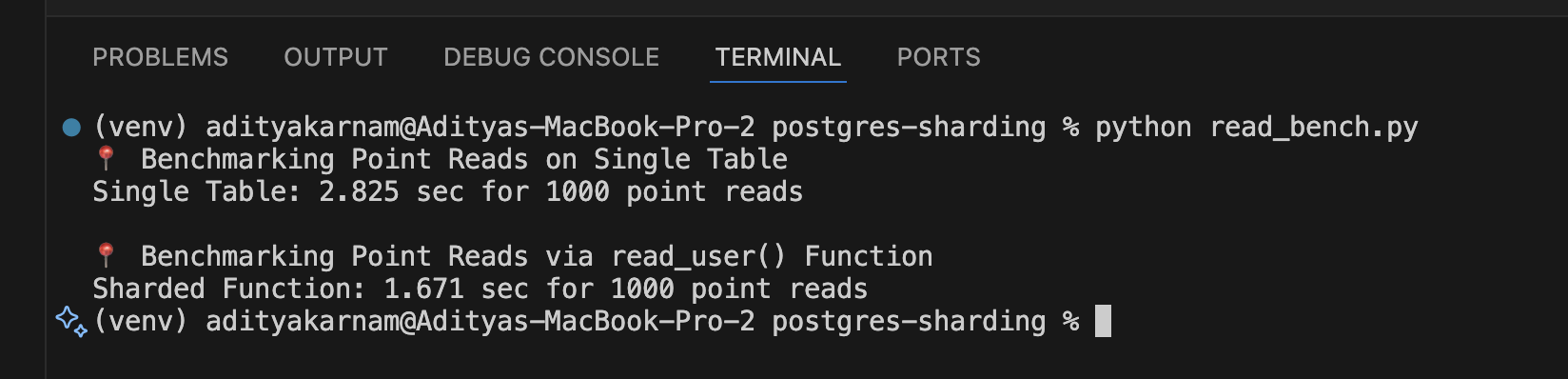
Based on benchmarking results, we can observe several key patterns with manual sharding:

Conclusion
Manual sharding in PostgreSQL offers a powerful approach to horizontal scalability without requiring third-party extensions like Citus. Using a combination of function-based routing and separate tables, we can distribute data efficiently while maintaining a unified interface for our application.
Opinions expressed by DZone contributors are their own.
Comments