SQL Phenomena for Developers
These phenomena represent a set of data integrity anomalies that may occur when a developer tries to squeeze performance from transaction concurrency.
Join the DZone community and get the full member experience.
Join For FreeThe SQL phenomena (or anomalies) are:
- Dirty reads
- Non-repeatable reads
- Phantom reads
- Dirty writes
- Read skews
- Write skews
- Lost updates
As their names suggest, these phenomena represent a set of data integrity anomalies that may occur when a developer tries to squeeze performance from transaction concurrency by relaxing the SERIALIZABLE isolation level in favor of another transaction isolation level.
There is always a trade-off between choosing the transaction isolation level and the performance of transaction concurrency.
Dirty Writes
A dirty write is a lost update. In a dirty write case, a transaction overwrites another concurrent transaction, which means that both transactions are allowed to affect the same row at the same moment. The following figure depicts a scenario that folds in under the dirty write umbrella:
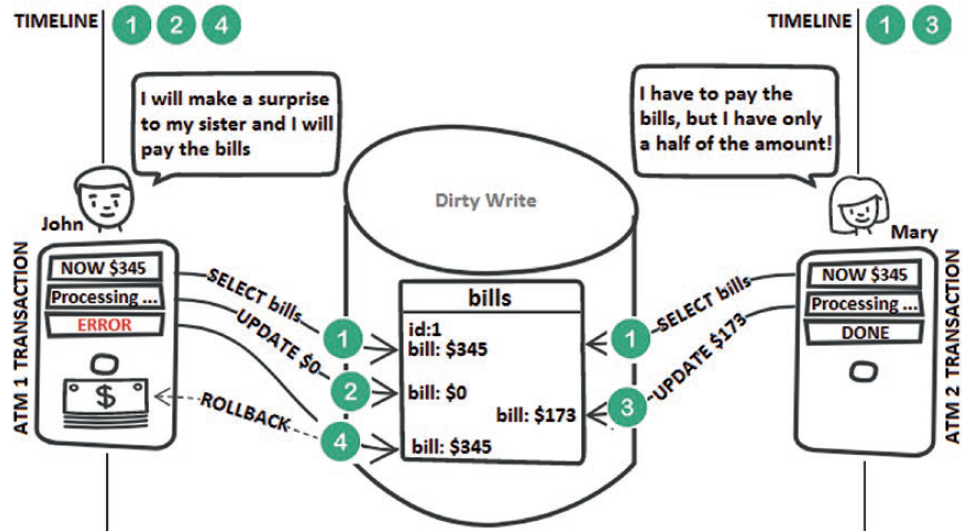
Step 1: John tries to pay Mary’s bills. First, his transaction triggers a SELECT to query the amount owed. Mary tries to pay these bills at the same time. Therefore, she triggers the exact same query and gets the same result as John ($345).
Step 2: John’s transaction attempts to pay the entire amount owed. Consequently, the amount to pay is updated to $0.
Step 3: Mary’s transaction is not aware of this update, and it attempts and succeeds to pay half of the amount owed (her transaction commits). The triggered UPDATEsets the amount to pay to $173.
Step 4: Unfortunately, John’s transaction doesn’t manage to commit and it must be rolled back. Therefore, the amount to pay is restored to $345. This means that Mary has just lost $172.
Making business decisions in such a context is very risky. The good news is that, by default, all database systems prevent dirty writes (even at the Read Uncommitted isolation level).
Dirty Reads
A dirty read is commonly associated with the Read Uncommitted isolation level. In a dirty read case, a transaction reads the uncommitted modifications of another concurrent transaction that rolls back in the end. The following figure depicts a scenario that folds in under the dirty read umbrella.
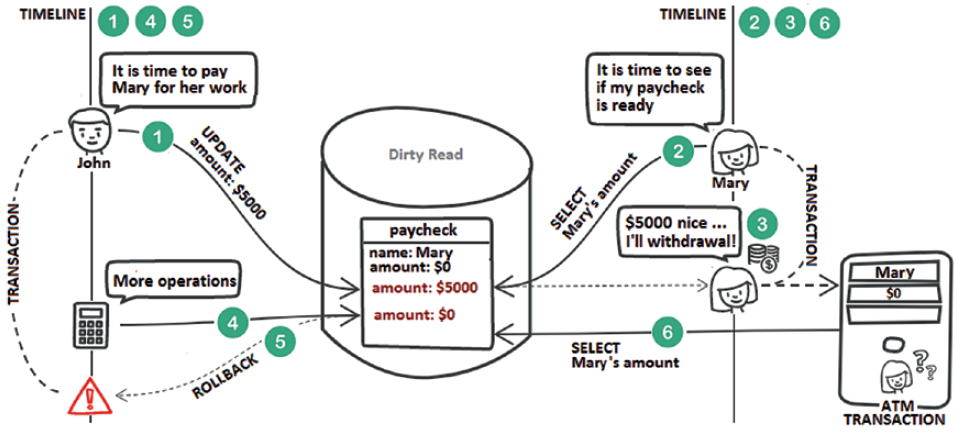
Step 1: John tries to pay Mary for her job. His transaction triggers an UPDATEthat sets the paycheck amount to $5,000.
Step 2: Later, Mary is using her computer to query her paycheck and notices that John has transferred the money. Mary’s transaction is committed.
Step 3: Mary decides to go to an ATM to withdraw the money.
Step 4: Meanwhile, John’s transaction is enriched with more queries.
Step 5: John’s transaction fails and is rolled back. Therefore, Mary’s paycheck amount is restored to $0.
Step 6: Finally, Mary reaches the ATM and attempts to withdraw her paycheck. Unfortunately, this is not possible since the ATM reveals a paycheck of $0.
As you can see in this figure, making business decisions based on uncommitted values can be very frustrating and can affect data integrity. As a quick solution, you can simply use a higher isolation level. As a rule of thumb, always check the default isolation level of your database system. Most probably, the default will not be Read Uncommitted but check it anyway since you must be aware of it.
Non-Repeatable Reads
A non-repeatable read is commonly associated with the Read Committed isolation level. A transaction reads some record while a concurrent transaction writes to the same record (a field or column) and commits. Later, the first transaction reads that same record again and gets a different value (the value that reflects the second transaction’s changes). The following figure depicts a possible scenario in this context.
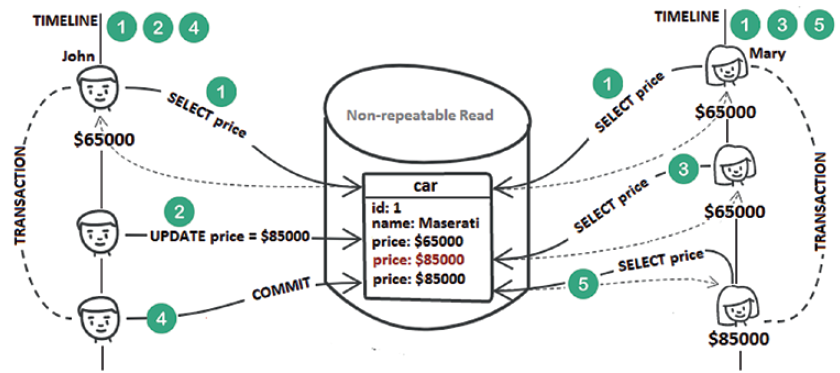
Step 1: John’s transaction triggers a SELECTand fetches the amount of $65,000. At the same time, Mary’s transaction does exactly the same thing.
Step 2: John’s transaction updates the price from $65,000 to $85,000.
Step 3: Mary’s transaction reads the price again. The value is still $65,000 (therefore, a dirty read is prevented).
Step 4: John’s transaction commits.
Step 5: Mary’s transaction reads the price again. This time, she gets a price of $85,000. The price was updated due to John’s transaction. This is a non-repeatable read.
Non-repeatable reads become problematic when the current transaction (e.g., Mary’s transaction) makes a business decision based on the first read value. One solution is to set the isolation level as Repeatable Read or Serializable (both of them prevent this anomaly by default). Or, you can keep Read Committed, but acquire shared locks via
SELECT FOR SHAREin an explicit way. Moreover, databases that use MVCC (Multi-Version Concurrency Control), which is most of them, prevent non-repeatable reads by checking the row version to see if it was modified by a transaction that is concurrent to the current one. If it has been modified, the current transaction can be aborted.
Hibernate guarantees session-level repeatable reads (see Item 21 in Spring Boot Persistence Best Practices). This means that the fetched entities (via direct fetching or entity queries) are cached in the Persistence Context. Subsequent fetches (via direct fetching or entity queries) of the same entities are done from the Persistence Context. Nevertheless, this will not work for conversations that span over several (HTTP) requests. In such cases, a solution will rely on the Extended Persistence Context or, the recommended way, on detached entities (in web applications, the detached entities can be stored in an HTTP session). You also need an application-level concurrency control strategy such as Optimistic Locking to prevent lost updates (see Item 131 in Spring Boot Persistence Best Practices).
Phantom Reads
A phantom read is commonly associated with the Repeatable Read isolation level. A transaction reads a range of records (e.g., based on a condition). Meanwhile, a concurrent transaction inserts a new record in the same range of records and commits (e.g., inserts a new record that passes the same condition). Later, the first transaction reads the same range again and it sees the new record. The following figure depicts a possible scenario in this context.
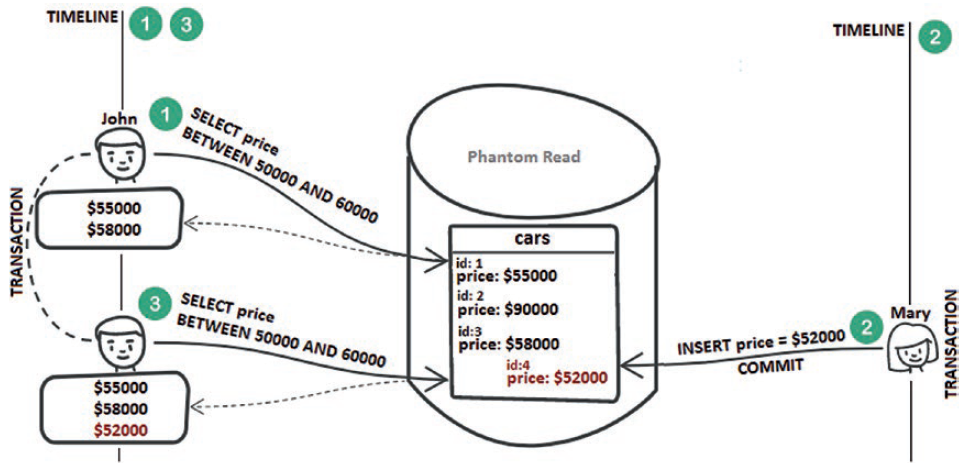
Step 1: John fetches car prices between $50,000 and $60,000. He gets two records.
Step 2: Mary inserts a new price of $52,000 (so a new record in the price range used by John). Mary’s transaction commits.
Step 3: John fetches the prices between $50,000 and $60,000 again. This time, he gets three records, including the one inserted by Mary. This is called a phantom read.
This anomaly can be prevented via the SERIALIZABLE isolation level or via MVCC consistent snapshots.
Read Skews
A read skew is an anomaly that involves at least two tables (e.g., car and engine). A transaction reads from the first table (e.g., reads a record from the cartable). Further, a concurrent transaction updates the two tables in sync (e.g., updates the car fetched by the first transaction and its corresponding engine). After both tables are updated, the first transaction reads from the second table (e.g., reads the engine corresponding to the car fetched earlier). The first transaction sees an older version of the car record (without being aware of the update) and the latest version of the associated engine. The following figure depicts a possible scenario in this context.
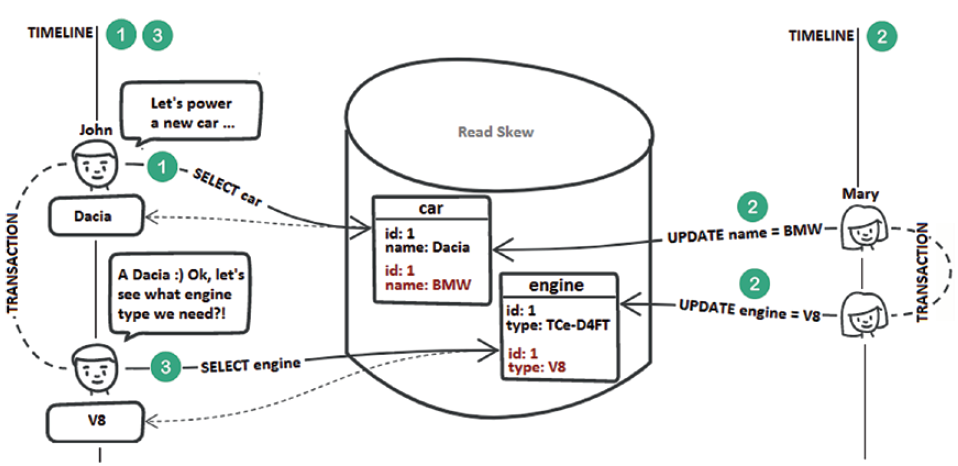
Step 1: John selects the car called Dacia from the car table.
Step 2: Mary updates in sync the car and engine tables. Note that Mary’s transaction modified the engine corresponding to the Dacia car from TCe-D4FT to V8.
Step 3: John selects the engine corresponding to the Dacia car, and he gets V8. This is a read skew.
You can prevent a read skew by acquiring shared locks on every read or by MVCC implementation of the Repeatable Read isolation level (or Serializable).
Write Skews
A write skew is an anomaly that involves at least two tables (e.g., car and engine). Both tables should be updated in sync, but a write skew allows two concurrent transactions to break this constraint. Let’s clarify this via the scenario shown in the following figure.
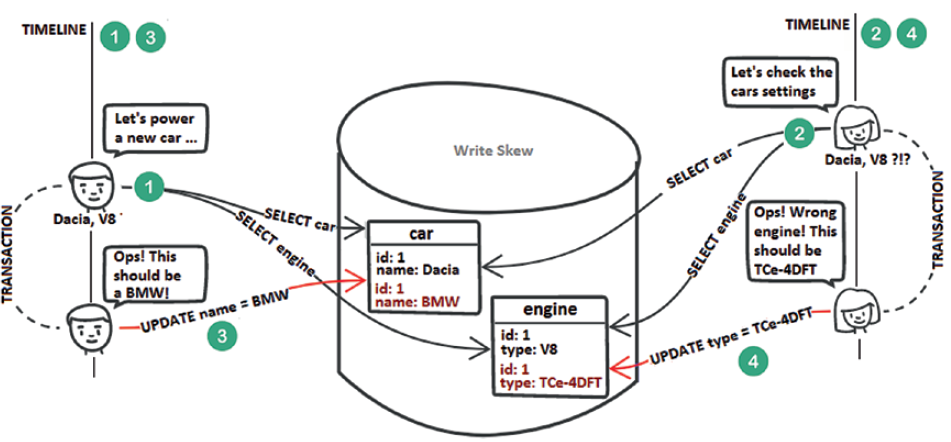
Step 1: John selects the car Dacia and its associated engine, V8.
Step 2: Mary performs the same queries as John and gets the same results (both of them are aware that Dacia and V8 are not compatible configuration and either the name of the car or the engine type is wrong).
Step 3: John decides to update the car name from Dacia to BMW.
Step 4: Mary decides to update the engine type from V8 to TCe-4DFT. This is a write skew.
You can prevent write skews by acquiring shared locks on every read or by MVCC implementation of the Repeatable Read isolation level (or Serializable).
Lost Updates
A lost update is a popular anomaly that can seriously affect data integrity. A transaction reads a record and uses this information to make business decisions (e.g., decisions that may lead to modification of that record) without being aware that, in the meantime, a concurrent transaction has modified that record and committed. When the first transaction commits, it is totally unaware of the lost update. This causes data integrity issues (e.g., inventory can report a negative quantity). Consider the possible scenario shown in the following figure.
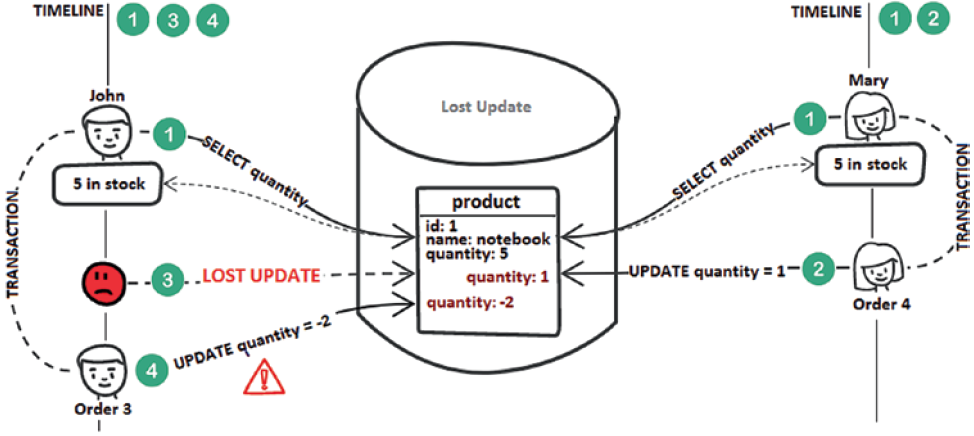
Step 1: John and Mary fetch the number of notebooks (there are five in stock).
Step 2: Mary decides to buy four notebooks. Therefore, the quantity is reduced from 5 to 1.
Step 3: John’s transaction is not aware of Mary’s update.
Step 4: John decides to buy three notebooks. Therefore, the quantity becomes -2 (by definition, the quantity should be a positive integer).
This anomaly affects Read Committed isolation level and can be avoided by setting the Repeatable Read or Serializable isolation level. For the Repeatable Read isolation level without MVCC, the database uses shared locks to reject other transactions’ attempts to modify an already fetched record. In the presence of MVCC, you can rely on application-level Optimistic Locking mechanism.
If you liked this article, then you'll my book containing 150+ performance items - Spring Boot Persistence Best Practices.

This book helps every Spring Boot developer to squeeze the performances of the persistence layer.
Opinions expressed by DZone contributors are their own.
Comments