Inserting Data Into a Database Using Batch Job
Learn how batch processing can be used with the MuleSoft database connector to insert data into a database in Mule using a batch job.
Join the DZone community and get the full member experience.
Join For FreeTo insert data into a database using a batch job, let’s first understand what batch processing and the database connector are in Mule.
Batch Processing
We can process messages in Mule with the help of batches. Batch Job is a block of code that splits messages into individual records, performs actions upon each record, then reports on the results and potentially pushes the processed output to other systems or queues. This functionality is particularly useful when working with streaming input or when engineering "near real-time" data integration between SaaS applications.
A batch job contains one or more batch steps which, in turn, contain any number of message processors that act upon records as they move through the batch job. During batch processing, you can use record-level variables (recordVars) and MEL expressions to enrich, route or otherwise act upon records.
A batch job executes when triggered by either a batch executor in a Mule flow or a message source in a batch-accepting input; when triggered, Mule creates a new batch job instance. When all records have passed through all batch steps, the batch job instance ends and the batch job result can be summarized in a report to indicate which records succeeded and which failed during processing.
Batch Processing Phases
There are 4 phases in Batch Processing:
Input (Optional):
Triggers the processing via an inbound endpoint.
Modifies the payload as needed before batch processing.
Load and Dispatch (Implicit):
Performs "behind the scenes" work.
Splits payload into a collection of records and creates a queue.
Process (Required):
Asynchronously processes the records.
Contains one or more batch steps.
On Complete (Optional):
Reports the summary of records processed.
Get insight into which records failed so can address issues.
Database Connector
The database connector allows you to connect with almost any Java Database Connectivity (JDBC) relational database using a single interface for every case. The database connector allows you to run diverse SQL operations on your database, including Select, Insert, Update, Delete, and even Stored Procedures.
To use a database connector in your Mule application:
Check that your database engine is Database Engines Supported Out of the Box; if it is not, then add the database driver for your database engine.
Configure a Database Global Element where you define
Your database’s location and connection details.
Whether DataSense is enabled.
Advanced connection parameters such as connection pooling.
Configure the Database connector element that you embed in your Mule flow, which
Contains the query to perform on the database.
References the Database Global Element.
Supported Operations
The database connector supports the following operations:
Select
Insert
Update
Delete
Stored Procedure
Bulk Execute
DDL operations such as CREATE, ALTER, etc.
Additionally, you can run a TRUNCATE query on the database by selecting Update as the operation.
Example:
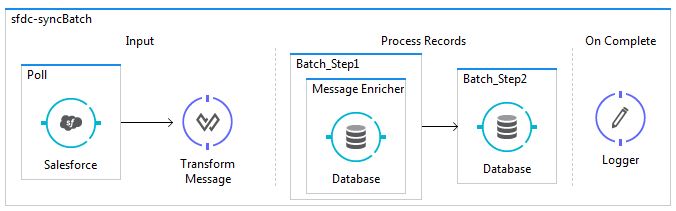
In this example, we are going to take data from a SaaS application like Salesforce using Poll, then filter the data for any duplicate values in the database, and then finally save the non-duplicate data to the database.
Steps:
Create a batch job to poll the Salesforce at a specific interval of time with a specific condition (eg. lastModifiedDate).
Add a DataWeave Transformer to map data.
Add a batch step and use a message enricher to check if the record exists in the database (an account with the same name), store the result in the record variable, and retain the original payload.
Add a second batch step with a filter that allows only new records to be added into the database.
Flow:
Code:
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:schedulers="http://www.mulesoft.org/schema/mule/schedulers" xmlns:dw="http://www.mulesoft.org/schema/mule/ee/dw" xmlns:db="http://www.mulesoft.org/schema/mule/db" xmlns:batch="http://www.mulesoft.org/schema/mule/batch" xmlns:sfdc="http://www.mulesoft.org/schema/mule/sfdc" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:spring="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-current.xsd
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/sfdc http://www.mulesoft.org/schema/mule/sfdc/current/mule-sfdc.xsd
http://www.mulesoft.org/schema/mule/batch http://www.mulesoft.org/schema/mule/batch/current/mule-batch.xsd
http://www.mulesoft.org/schema/mule/db http://www.mulesoft.org/schema/mule/db/current/mule-db.xsd
http://www.mulesoft.org/schema/mule/ee/dw http://www.mulesoft.org/schema/mule/ee/dw/current/dw.xsd
http://www.mulesoft.org/schema/mule/schedulers http://www.mulesoft.org/schema/mule/schedulers/current/mule-schedulers.xsd">
<sfdc:config name="Salesforce__Basic_Authentication" username="${sfdc.username}" password="${sfdc.password}" securityToken="${sfdc.token}" doc:name="Salesforce: Basic Authentication"/>
<batch:job name="sfdc-syncBatch">
<batch:input>
<poll doc:name="Poll">
<schedulers:cron-scheduler expression="0 15 19 * * ?"/>
<watermark variable="timestamp" default-expression="#['1900-12-11T14:16:00.000Z']" selector="MAX" selector-expression="#[payload.LastModifiedDate]"/>
<sfdc:query config-ref="Salesforce__Basic_Authentication" query="dsql:SELECT BillingCity,BillingCountry,BillingPostalCode,BillingState,BillingStreet,LastModifiedDate,Name FROM Account WHERE LastModifiedDate > #[flowVars['timestamp']]" doc:name="Salesforce"/>
</poll>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
payload map ((payload01 , indexOfPayload01) -> {
NAME: payload01.Name,
STREET: payload01.BillingStreet,
CITY: payload01.BillingCity,
STATE: payload01.BillingState,
POSTAL: payload01.BillingPostalCode,
COUNTRY: payload01.BillingCountry
})]]></dw:set-payload>
</dw:transform-message>
</batch:input>
<batch:process-records>
<batch:step name="Batch_Step1">
<enricher source="#[payload.size() >0]" target="#[recordVars.exists]" doc:name="Message Enricher">
<db:select config-ref="Derby_Configuration" doc:name="Database">
<db:parameterized-query><![CDATA[select NAME,STREET,CITY,STATE,POSTAL,COUNTRY from accounts where NAME = #[payload.NAME]]]></db:parameterized-query>
</db:select>
</enricher>
</batch:step>
<batch:step name="Batch_Step2" accept-expression="#[!recordVars.exists]">
<db:insert config-ref="Derby_Configuration" doc:name="Database">
<db:parameterized-query><![CDATA[Insert into Accounts (name,street,city,state,postal,country ) values (#[message.payload.NAME],#[message.payload.STREET],#[message.payload.CITY],#[message.payload.STATE],#[message.payload.POSTAL],#[message.payload.COUNTRY])]]></db:parameterized-query>
</db:insert>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger message="#[payload]" level="INFO" doc:name="Logger"/>
</batch:on-complete>
</batch:job>
</mule>Opinions expressed by DZone contributors are their own.
Comments