Integration Architecture Guiding Principles, A Reference
The Integration Architecture guiding principles are guidelines to increase the consistency and quality of technology decision-making for the integration solutions.
Join the DZone community and get the full member experience.
Join For FreeThe Integration Architecture guiding principles are guidelines to increase the consistency and quality of technology decision-making for the integration solutions. They describe the big picture of the enterprise within the context of its technology intent and impact on the organization. In the context of Integration Architecture, the guiding principles drive the definition of the target state of the integration landscape. Each principle will contain a description, rationale, and implications.
1. Centralized Governance
Statement
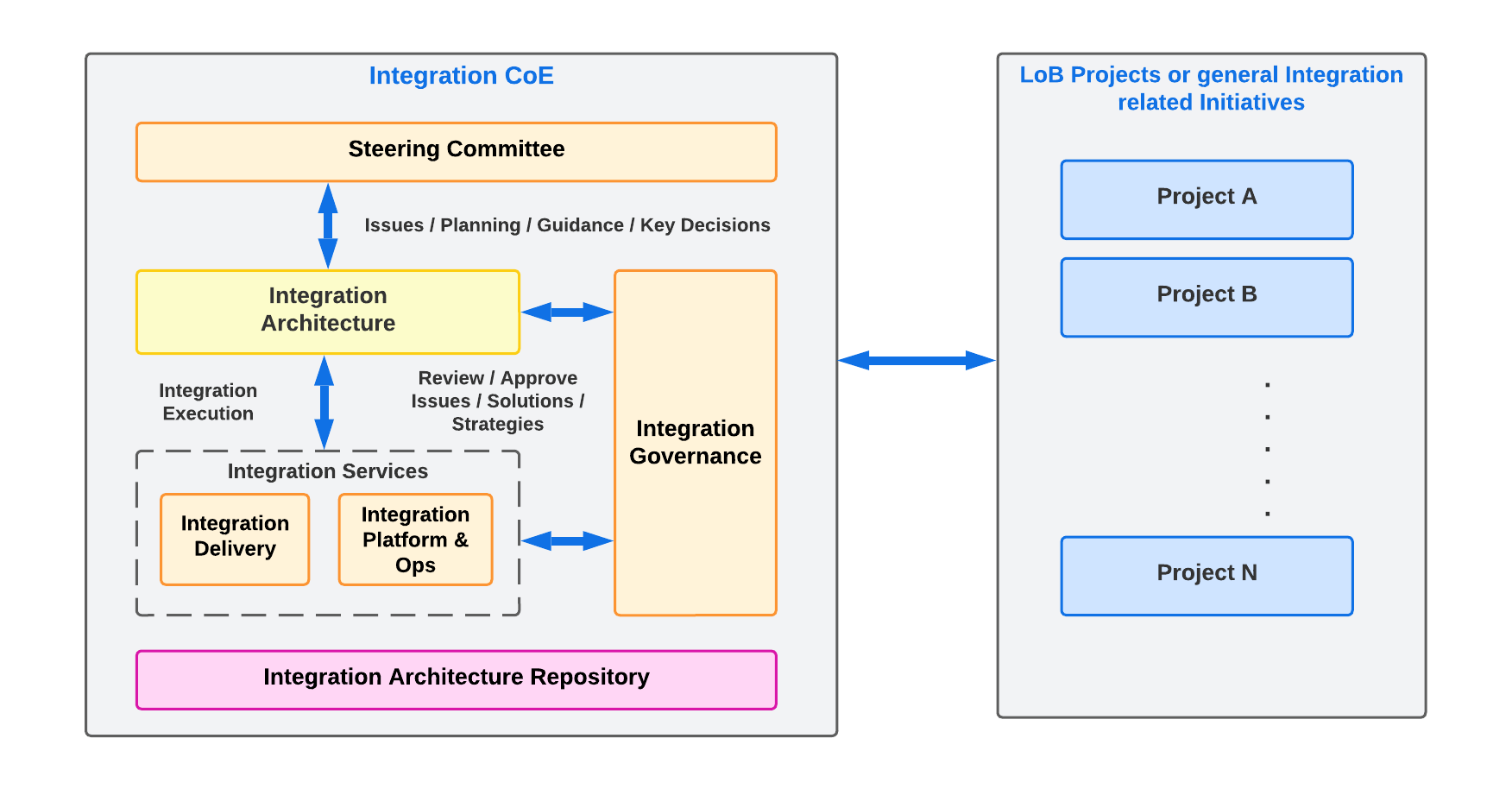
Any integration-related initiative should conform to the standards and recommendations of a centralized Integration Centre of Excellence (CoE); any design decision or strategy related to integrations needs to be driven, reviewed, and approved by the Integration CoE.
Rationale
• The Integration CoE will:
- Support all the Lines of Businesses (LoBs) to provide centralized governance by assessing all the integration-related initiatives.
- Ensure their compliance with any Enterprise Architecture (EA) principles.
- Help ensure consistency, which reduces the complexity of managing different integration solutions, improves business satisfaction and enables reusability of the existing integration capabilities and services. This maximizes Return on Investment (ROI) and reduces costs. In addition, adhering to the Integration CoE governance model will allow for support from multiple vendors, technical SMEs, and delivery teams, reducing the cost associated with vendor lock-in or overhead of hiring resources.
- Leverage a shared services model to ensure optimum resource use. It will involve staff members who understand the business, applications, data models, and underlying technologies. The following diagram describes the evolution model for the Integration CoE to address any initiatives and support continuous improvement.
Implications
- The Integration CoE is expected to provide the following core service offerings:
- Integration Architecture roadmap
- Opportunistic interface/service identification
- Relevant training
- Guidance on applicable standards, reusable services
- Patterns, standards, and templates
- Registry/repository services
- Project support
- Integration design, build, and test expertise
- Stakeholder involvement and communications
- Governance
- Retrospectives and continuous improvement
- Development teams should be able to deploy rapid changes for new or changed business requirements and functionality.
- The deployments should be measured and evaluated to help create continuous improvement.
- Businesses should be provided with reasonable costs for the service offerings, which will result in continuous improvement by eliminating wasteful practices and technical debts and promoting reusability.
- Each deployment should be measured, and the costs should be analyzed, including hardware, software, design, development, testing, administration, and deployment. Total Cost of Ownership (TCO) analysis for ongoing support and maintenance factored into these analyses.
- The Integration CoE should enforce controls and processes to maintain the integrity of the integration platform and application components, and underlying information.
- The Integration CoE should provide a culturally inclusive approach to the systems’ environment and focuses on discipline, agility, and simplification. As a result, it should be easy to demonstrate that a utility within The Integration CoE will experience a much lower TCO.
![Diagram 1 - A Reference Integration CoE Governance Model]()
2. Application Decoupling
Statement
Achieve technological application independence through Middleware, Reusable Microservices/APIs (Application Programming Interfaces), and Asynchronous Message-oriented integrations.
Rationale
- Integration architecture must be planned to reduce the impact of technology changes and vendor dependence on the business through decoupling. Decoupling should involve seamless integrations between information systems through Middleware, Microservices/APIs (Application Programming Interfaces), and Asynchronous Messaging systems.
- Every decision made concerning the technologies that enable the integration of information systems will put more dependency on those technologies. Therefore, this principle intends to ensure that the information systems are not dependent on specific technologies to integrate. The independence of applications from the supporting technology allows applications to be developed, upgraded, and operated under the best cost-to-benefit ratio. Otherwise, technology, subject to continual obsolescence and vendor dependence, becomes the driver rather than the user requirements.
- Avoid point-to-point integration, as it involves technological dependence on the respective information systems and tight coupling between the systems involved.
Implications
- Reusable Microservices/APIs will be developed to enable legacy applications to interoperate with applications and operating environments developed under the enterprise architecture.
- The microservices should be developed and deployed independently, thus enabling agility
- Middleware should be used to de-couple applications from specific software solutions.
- Problematic parts of the application should be isolated, fixed, and maintained, while the larger part can continue without any change.
- One should be able to add more infrastructure resources to the specific microservice to perform better without adding servers to the whole application.
- This principle also implies documenting technology standards and API specifications and metrics to better understand the operational cost.
- Industry benchmarks should be adopted to provide comparator metrics for efficiency and ROI.
- Specific microservice should be implemented with higher availability than the other components, for instance, 24 hours x 7 days. In comparison, the remaining part of the application is less available to save on resources. As it can run autonomously, it can be architected to have its level of availability.
3. Data and Application Integration
Statement
Categorize integration use cases as either data integration or application integration and follow the respective integration lifecycle processes involved for each category.
Rationale
- Data Integration is focused on reconciling disparate data sources, and data sets into a single view of data shared across the company. It is often a prerequisite to other processes, including analysis, reporting, and forecasting.
- Application Integration is focused on achieving operational efficiency to provide (near) real-time data to the applications and keep business processes running. It doesn’t involve reconciling different data sources into a coherent and shared data model to get a holistic view of all datasets (for example, finance, sales, etc.).
- Both Data Integration and Application Integration may use an Extract, Transform, and Load (ETL), a tripartite process in which data is extracted (collected), generally in bulk, from the raw sources, transformed (cleaned), and loaded (or saved) to a data destination.
- The ETL data pipeline, an umbrella term for all data movement and cleaning, enables piping data into non-unified data sources.
Implications
- Data Integration should provide the following capabilities to an enterprise:
- Customer 360 view and streamlined operations
- Centralized Data Warehouse
- Data Quality Management
- Cross-departmental collaboration
- Big Data Integration
- For data integration use cases, standard tools available within the enterprise should be used to perform ETL and data analysis for large volumes of data. Ex: Azure Data Factory, Informatica, etc.
- The data storage services should be made available for data integration processes, persisting data for analysis, and reporting. Ex - Databases (SQL/NoSQL), Data Warehouse, Data Lake, etc.
- Application Integration should provide the following capabilities to an enterprise:
- Real-time or near real-time data exchange between the applications.
- Keeping data up to date across different applications
- Providing reusable interfaces for exchanging data with different applications
- Recovery of failed transactions in (near) real-time through retry mechanisms or reliable messaging flows.
- For application integration, consider using APIs/microservices, message-based middleware, or workflow services for (near) real-time data exchange patterns. Technologies that enable these services are MuleSoft, AWS, IBM MQ, etc.
- ETLs may be used for application integration; however, considerations should be made to process small volumes of data with high frequency for exchanging data between the applications to achieve a near real-time data transfer.
4. Event-Driven Architecture
Statement
Design systems to transmit and/or consume events to facilitate responsiveness.
Rationale
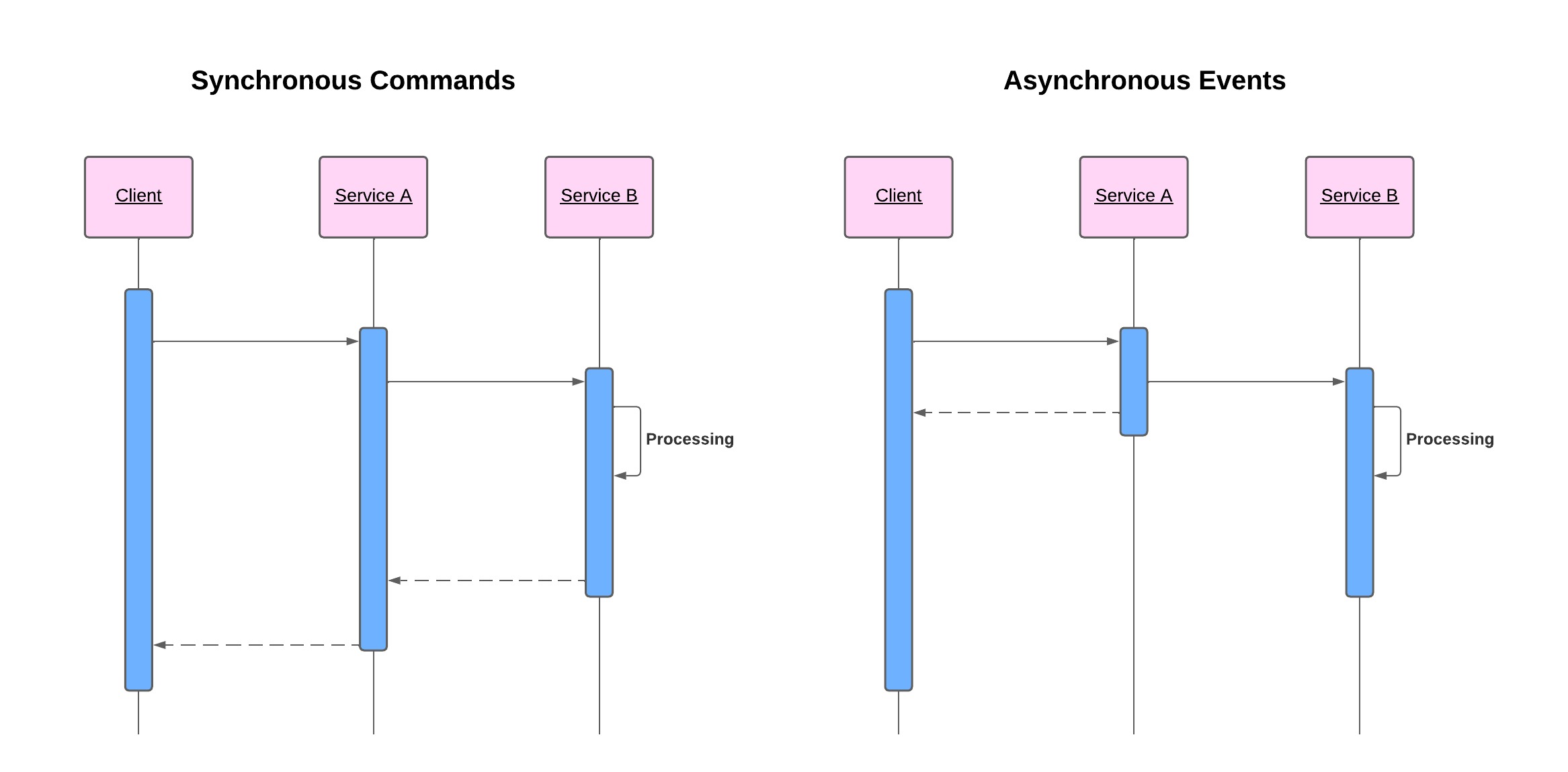
- In an event-driven architecture, the client generates an event and can immediately move on to its next task. Different parts of the application then respond to the event as needed, which improves the responsiveness of the application.
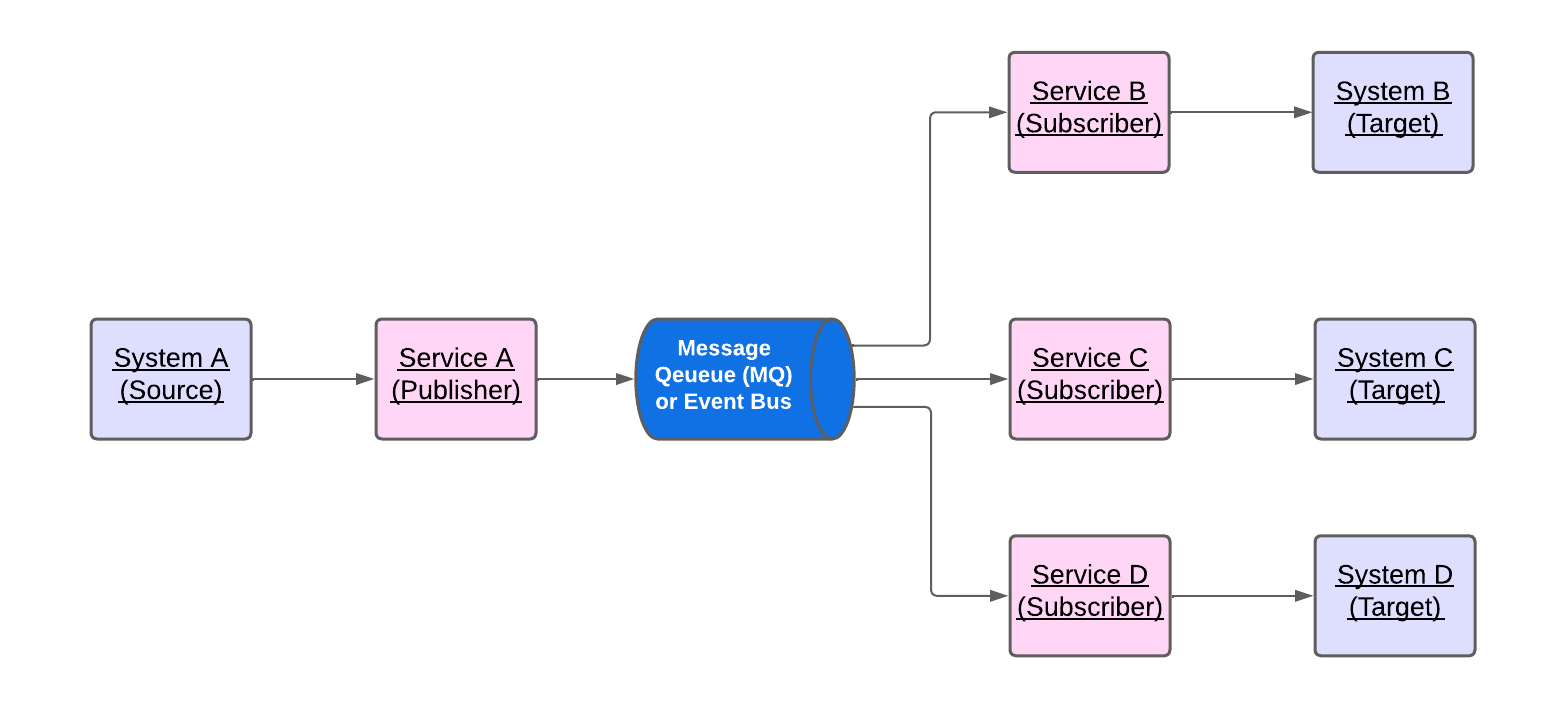
- In an event-driven architecture, the publisher emits an event, which the event bus or message queues (MQ) acknowledge. The event bus or MQ routes events to subscribers, which process events with self-contained business logic. There is no direct communication between publishers and subscribers. This is called a Publish-Subscribe model, as described in the following diagram.
- The publish-subscribe model used in the event-driven architecture allows multiple subscribers for the same event; thus, different subscribers may execute other business logic or involve different systems. In the MQ terminology, the MQ component that supports multiple subscribers is called an MQ Topic.
- Migrating to event-driven architecture allows the handling of unpredictable traffic as the processes involved can all run at different rates independently.
- Event-driven architectures enable processes to perform error handling and retries efficiently as the events are persistent across different processes.
- Event-driven architectures promote development team independence due to loose coupling between publishers and subscribers. Applications can subscribe to events with routing requirements and business logic separate from the publisher and other subscribers. This allows publishers and subscribers to change independently, providing more flexibility to the overall architecture.
Implications
- Applications that do not need immediate responses from the services and can allow asynchronous processing should opt for event-driven architectures.
- Events should be persisted in the messaging queues (MQ), which should act as the temporary stores for the events so that those can be processed as per the configured rates of the consumer services and to ensure there is no event loss. Once the events are processed, those may be purged from the MQ accordingly.
- Services involved should be configured to reprocess and retry the events in case of a recoverable technical issue. For example, when a downstream system goes down, the events will fail to get delivered; however, the system comes back, the failed events can be reprocessed automatically. The services should retry periodically to process the events until they are successful.
- Services involved may not reprocess or retry the events in case of a business or functional error. For example, if the data format is wrong, in that case, however many times the events are reprocessed, those will keep failing, creating poison events that will block the entire process. To avoid the scenario, business or functional errors should be identified, and failed events should be routed to a failed event queue. A queue is generally a component that stores the events temporarily for processing.
- Adoption of event-streaming systems that can handle a continuous stream of events (e.g., Kafka or Microsoft Azure Event Hub). Event Streaming is the process of capturing data in the form of streams of events in real-time from event sources such as databases, IoT devices, or others.
5. Real-Time or Near Real-Time Integration
Statement
Streamline processes to send data frequently through message-based integrations.
Rationale
- Messages form a well-defined technology-neutral interface between the applications.
- It enables loose coupling of applications. An enterprise may have multiple applications with different languages and platforms built independently.
- It provides a lot of options for performance, tuning, and scaling. For example:
- Deployment of requester and processing service on different infrastructures.
- Multiple requesters may share a single server.
- Multiple requesters may share multiple servers.
- The various messaging middleware independently implements the common messaging patterns from the applications.
- Request/Reply
- Fire and Forget
- Publish/Subscribe
- Middleware solutions handle message transformations. Example:: JSON to XML, XML to JSON, etc.
- Middleware solutions can decompose a single large request into several smaller requests.
- Asynchronous messaging is fundamentally a pragmatic reaction to the problems of distributed systems. A message can be sent without both systems being up and ready simultaneously.
- Communicating asynchronously forces developers to recognize that working with a remote application is slower, which encourages the design of components with high cohesion (lots of work locally) and low adhesion (selective work remotely).
Implications
- The enterprise should responsively share data and processes via message-based integrations.
- Applications should be informed when shared data is ready for consumption. Latency in data sharing must be factored into the integration design; the longer sharing can take, the more opportunity for shared data to become stale and the more complex integration becomes.
- Messaging patterns should be used to transfer data packets frequently, immediately, reliably, and asynchronously using customizable formats.
- Applications should be integrated using messaging channels (Enterprise Service Bus, Message Queues, etc.) to work together and exchange information in real-time or near real-time.
6. Microservices
Statement
Publish and promote enterprise APIs / microservices to facilitate a scalable, extensible, reusable, and secure integration architecture.
Rationale
- Monolithic architectures add risk for application availability because many dependent and tightly coupled processes increase the impact of a single process failure. With a microservices architecture, an application is built as independent components that run each application process as a service. These services communicate via a well-defined interface using lightweight APIs.
- Microservices architectures make applications easier to scale and faster to develop, enabling innovation and accelerating time-to-market for new features.
- Microservices allow each service to be independently scaled to meet the demand for the application feature it supports. This enables teams to right-size infrastructure needs, accurately measure the cost of a feature, and maintain availability if a service experiences a spike in demand.
- Microservices enable continuous integration and delivery, making trying out new ideas easy and rolling back if something doesn’t work. The low cost of failure encourages experimentation, makes it easier to update code, and accelerates time-to-market for new features.
- Microservices architectures don’t follow a “one size fits all” approach, thus enabling technological freedom. Teams have the freedom to choose the best tool to solve their specific problems. Therefore, teams building microservices can choose the best tool for each job.
- Dividing software into small, well-defined modules enables teams to use functions for multiple purposes. A service written for a specific function can be used as a building block for another feature. This allows an application to bootstrap, as developers can create new capabilities without writing code from scratch.
- Service independence increases an application’s resistance to failure. In a monolithic architecture, if a single component fails, it can cause the entire application to fail. With microservices, applications handle total service failure by degrading functionality and not crashing the entire application.
- This will support agencies to meet intra-agency commitments, enable inter-agency collaboration and integration, and secure the network to meet the digital, cyber, and citizen commitments fundamental to trust.
Implication
- Technologies like MuleSoft, Amazon Web Services (AWS), Microsoft Azure, etc. that provide the capability to build APIs should be fully leveraged to implement the microservices architecture pattern.
- APIs should be documented following documentation standards like RESTful API Modelling Language (RAML) or Swagger so that the consumer can understand the APIs' methods, operations, and functionality. APIs should also follow naming and versioning standards, which should reflect in the API documentation.
- APIs should be published into API catalogs/repositories/portals and made discoverable so that the project teams involving developers, architects, and business analysts can discover those and promote their reusability.
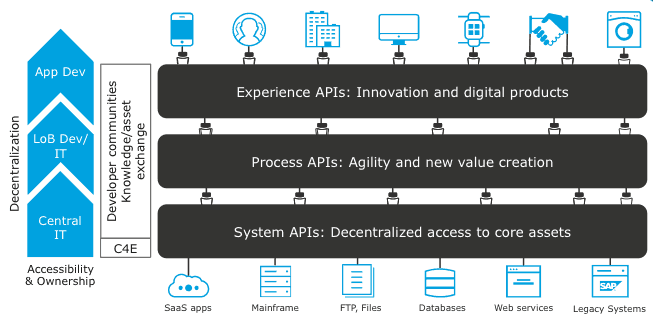
- A multi-layered API architecturemay be followed that leverages APIs at different levels with separation of concern, providing building blocks within different business domains or across LoBs. This architecture pattern is popularly known through the concept of API-led Connectivity recommended by MuleSoft. Below are the descriptions of the three layers of the API-led connectivity pattern:
- System Layer
System APIs provide a means of accessing underlying systems of record and exposing that data, often in a canonical format, while providing downstream insulation from any interface changes or rationalization of those systems. These APIs will also change more infrequently and will be governed by central IT, given the importance of the underlying systems. - Process Layer
The underlying processes that interact and shape this data should be strictly independent of the source systems from which that data originates. For example, in a purchase order process, some logic is common across products, geographies, and channels that should be distilled into a single service that can then be called by product-, geography-, or channel-specific parent services. These APIs perform specific functions, provide access to non-central data, and may be built by central IT or project teams. - Experience Layer
Experience APIs are how data can be reconfigured so that it is most easily consumed by its intended audience, all from a shared data source, rather than setting up separate point-to-point integrations for each channel.
- System Layer
- For the API-led approach vision to be successful, it must be realized across the whole enterprise.
- APIs should be secured as per the Information Security standards to ensure the API security standards are adhered to during the whole lifecycle of the APIs, from designing to development to publishing for consumption.
- Point-to-point integrations bypassing an API-led approach should be avoided as it creates technological dependencies on end systems and technical debts, which are hard to manage in the long term.
7. Cloud Enablement
Statement
Always consider cloud-based services for integration platform and application architecture solutions to ensure a proper balance of service, security, and costs.
Rationale
- Technology services can be delivered effectively via the cloud, a viable option compared to on-premises services.
- Cloud services are designed to support dynamic, agile, and scalable processing environments.
- The timing for implementation can be significantly different for on-premises versus cloud services.
- Operational costs can be significantly different for on-premises versus cloud services.
- Serverless architecture allows building and running applications in the cloud without the overhead of managing infrastructure. It provides a way to remove architecture responsibilities from the workload, including provisioning, scaling, and maintenance. Scaling can be automatic, and payment is made for what is used.
Implications
- An evaluation of on-premise versus cloud services should be conducted for each integration platform and application architecture solution. This includes Software as a Service (SaaS) as the first preferred option, Platform as a Service (PaaS) as the second, and Infrastructure as a Service (IaaS) as the least preferred option.
- The management of a Cloud Service Provider will be different from managing a vendor whose product is hosted on-premise. The agreement should capture specific support parameters, response times, and SLAs.
- The security policies and services for the network, data, and hosting premises should be clearly defined and disclosed by the Cloud Service Provider.
- The Cloud Service Provider should clearly define data ownership and access to information assets.
- Cloud Service Providers offer assurances that they provide secure isolation between the assets of each of their clients.
- Cloud services should provide mechanisms to capture resource allocation and consumption and produce measurement data.
- Cloud services should seamlessly handle infrastructure failures and address how to meet performance-related SLAs.
- Business continuity and disaster recovery plans, services, and testing of Cloud Service Providers should be analyzed and reviewed in detail.
- The fitment of serverless architectures should be evaluated for every integration use case to optimize costs, achieve scalability and remove the overhead of maintaining any infrastructure.
8. Operations Management
Statement
Integrate with the organization's operations architecture for audit, logging, error handling, monitoring, and scheduling.
Rationale
- Operations architecture is developed to provide ongoing support and management of the IT services infrastructure of an enterprise.
- Operations architecture ensures that the systems within the enterprise perform as expected by centrally unifying the control of operational procedures and automating the execution of operational tasks.
- It also reports the performance of the IT infrastructure and applications.
- The implementation of an operations architecture consists of a dedicated set of tools and processes which are designed to provide centralization and automation.
- Operations architecture within an enterprise generally provides the following capabilities:
- Scheduling
- Performance Monitoring
- Network Monitoring
- Event Management
- Auditing
- Logging
- Error Handling
- Service Level Agreements (SLAs)
- Operating Level Agreements (OLAs)
Implications
- The operations architecture should provide the ability to perform critical operational tasks like auditing, logging, error handling, monitoring, and scheduling.
- It should provide the ability to provide reports and statistics to identify anomalies, enabling the support team to take proactive actions before any major failure.
- It should provide visibility across the on-premises, cloud, and serverless infrastructures and platforms.
- There should be SLAs agreed upon between the support group and the customer regarding the different aspects of the services, like quality, availability, and responsibilities. SLAs will ensure that the services are provided to the customer as agreed upon in the contract.
- OLAs should agree to describe the responsibilities of each internal support group toward other support groups, including the process and timeframe for delivery of their services.
9. End-to-End Security
Statement
All technologies, solutions, tools, designs, applications, and methods used within the end-to-end target integration architecture must adhere to the organization's security and privacy policies, procedures, guidelines, and standards.
Rationale
- It will help maintain the integrity of data and systems as well as data transport and transmission methods.
- Failure to secure the information exchanged through the integration layer may lead to direct financial costs and damage the organization's reputation.
- It will help prevent unauthorized access to sensitive information.
- It will help prevent disruption of integration services/APIs, e.g., denial-of-service (DDoS) attacks.
- It will protect the integration platform and application components from exploitation by outsiders.
- It will keep downtime to a minimum, ensuring business continuity.
Implications
- Security controls for all aspects of the target-state integration architecture should be considered to ensure compliance with the organization's security regulations
- Security policies should be created, expanded, and/or reviewed for each integration solution to cover all items within the scope of this principle.
- Periodic auditing of the integration platform and application components should be performed to confirm compliance with this principle.
- Proper controls around authorization and access should be enforced upon the interfaces / APIs exposed on the integration layer to mitigate risk and ensure trust.
- Monitoring and auditing tools should be implemented regularly on the integration platforms and application components. The respective platform owners should evaluate the outcome.
Opinions expressed by DZone contributors are their own.
Comments