Internal Components of Apache ZooKeeper and Their Importance
In this article, readers will learn about the internal components of Apache ZooKeeper. The key concept is the zNode, which be acted as files or directories.
Join the DZone community and get the full member experience.
Join For FreeAs a bird’s eye view, Apache ZooKeeper has been leveraged to get coordination services for managing distributed applications. It holds responsibility for providing configuration information, naming, synchronization, and group services over large clusters in distributed systems. To consider as an example, Apache Kafka uses ZooKeeper for choosing their leader node for the topic partitions.
zNodes
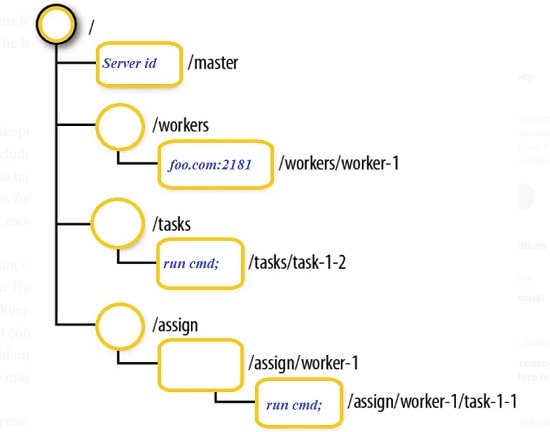
The key concept of ZooKeeper is the zNode, which can be acted either as files or directories. ZNodes can be replicated between servers as they are working in a distributed file system. Znode can be described by a data structure called stats and it consolidates information about zNode context like creation time, number of changes (as version), number of children, length of stored data or zxid (ZooKeeper transaction ID) of creation, and last change. For every modification of zNodes, its version increases.
The zNodes are classified into three categories:
- Persistence
- Ephemeral
- Sequential
Persistence zNode
Persistence zNode is alive even after the client, which created that particular zNode, is disconnected. Also, they survive after ZooKeeper restarted.
Ephemeral zNode
Ephemeral zNodes are active until the client is alive. As soon as the client gets disconnected from the ZooKeeper ensemble, then the ephemeral zNodes also get deleted automatically.
Sequential zNode
Sequential zNodes can be either persistent or ephemeral. Once a new zNode is created as a sequential zNode, then ZooKeeper sets the path of the zNode by attaching a 10-digit sequence number to the original name. The sequential zNode can be easily differentiated from the normal zNode with the help of different suffixes. The zNodes can have public or more restricted access. The access rights can be managed by special ACL permissions.
Sessions
Apache ZooKeeper’s operation relies heavily on sessions. The session will be established and the client will be given a session ID (a 64-bit number) when the client connects to the ZooKeeper server. A session has a timeout period, which is specified in milliseconds. The session might expire when the connection remains idle for more than the timeout period. The sessions are kept alive by the client sending a ping request (heartbeat) to the ZooKeeper service. By using a TCP connection, a client maintains the sessions with the ZooKeeper server. When a session ends, for any reason, the ephemeral zNodes created during that session will also get deleted. The right session timeout is determined by several factors, including the size of the ZooKeeper ensemble, application logic complexity, and network congestion.
Watches
The client can easily receive notifications about changes to the ZooKeeper ensemble through watches. The clients are able to set watches while reading a specific zNode. Any time a zNode (on which the client registers) changes, watches notify the registered client. Data associated with the zNode or changes in the zNode’s children are referred to as “zNode changes.” Watches are only activated once. A client must perform a second read operation if they want a notification again. The client will be disconnected from the server and the associated watches will also be removed when a connection session expires. The watches registered on a zNode can be removed with a call to removeWatches. Also, a ZooKeeper client can remove watches locally even if there is no server connection by setting the local flag to true.
ZooKeeper Quorum
It refers to the bare minimum of server nodes that must be operational and accessible to client requests. For a transaction to be successful, any client-generated updates to the ZooKeeper tree must be persistently stored in this quorum of nodes. Using the formula Q=2N+1, where Q is the number of nodes required to form a healthy ensemble and N is the maximum number of failure nodes, quorum specifies the rule for forming a healthy ensemble. The above formula can be considered to decide what is the safest and optimal size of a quorum. The ensemble can be defined simply as a group of ZooKeeper servers. The minimum number of nodes that are required to form an ensemble is three. A five-node ZooKeeper ensemble can handle two node failures because a quorum can be established from the remaining three nodes as per the formula Q=2N+1.
The following entries can be defined as the quorum of ZooKeeper servers and must be available in the zoo.cfg file located under “conf directory.”
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
And they follow the pattern as:
server.X=server_name:port1:port2
server.X, where X is the server number in ASCII. Prior to that, we will have to create a file named as “myid” under the ZooKeeper data directory in each ZooKeeper server. This file should contain the server number X as an entry in it. server_name is the hostname of the node where the ZooKeeper service is started.
- port1: the ZooKeeper server uses this port to connect followers to the leader.
- port2: this port is used for leader election.
Transactions
Transaction in Apache ZooKeeper is atomic and idempotent and involves two steps namely leader election and atomic broadcast. ZooKeeper uses ZooKeeper Atomic Broadcast (ZAB), a unique atomic messaging protocol. Because it is atomic, the ZAB protocol ensures that updates will either succeed or fail.
Local Storage and Snapshots
Transactions are stored in local storage on ZooKeeper servers. The ZooKeeper Data Directory contains snapshots and transactional log files, which are persistent copy of the zNodes stored by an ensemble. The transactions are logged to transaction logs. Any changes to zNodes are appended to the transaction log and when the log file size increases, a snapshot of the current state of zNodes is written to the file system.
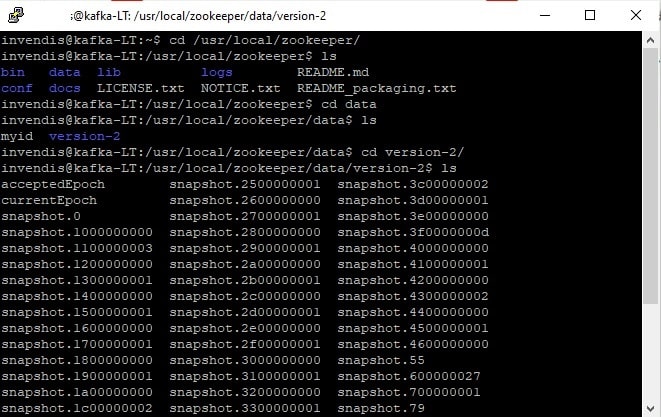
The ZooKeeper tracks a fuzzy state of its own data tree within the snapshot files. Because ZooKeeper transaction logs are written at a rapid rate, it is critical that they be configured on a disk separate from the server’s boot device. In the event of a catastrophic failure or user error, the transactional logs and snapshot files in Apache ZooKeeper make it possible to recover data. Inside the zoo.cfg file available under the “conf directory” of the ZooKeeper server, the data directory is specified by the dataDir parameter and the data log directory is specified by the dataLogDir parameter.
Conclusion
In this article, you have learned about the internal components of Apache ZooKeeper, which included three types of zNodes, sessions, watches, ZooKeeper quorum, and transactions. At this point, you should have a clearer understanding of Apache ZooKeeper’s internal components and their uses.
Hope you have enjoyed this read. Please like and share if you feel this composition is valuable.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments