Introducing the MERGE Command in PostgreSQL 15
This article explores the advantages of the MERGE command in PostgreSQL, with real-world use cases, automation techniques, and performance benchmarking results.
Join the DZone community and get the full member experience.
Join For FreeDevelopers often need to merge data from external sources to the base table. The expectation of this merge operation is that data from external sources refresh data at the main table. Refresh means inserting new records, updating existing records, and deleting if a record is not found.
Since the 9.4 version release, PostgreSQL has supported the INSERT command with the ‘ON CONFLICT’ clause. While this proved to be a workaround for the MERGE command, many features, such as conditional delete and simplicity of query, were missing. Other databases, such as Oracle and SQL Server, already support MERGE commands. Until PostgreSQL 15, it was still one of the long-awaited features for PostgreSQL users.
This article discusses the advantages, use cases, and benchmarking of the MERGE command, which is newly supported by PostgreSQL 15.
How the MERGE Command Works in PostgreSQL
The MERGE command selects rows from one or more external data sources to UPDATE, DELETE, or INSERT on the target table. Depending on the condition used in the MERGE command, the user running the MERGE command should have UPDATE, DELETE, and INSERT privileges on the target table. The user should also have SELECT privileges on the source table(s).
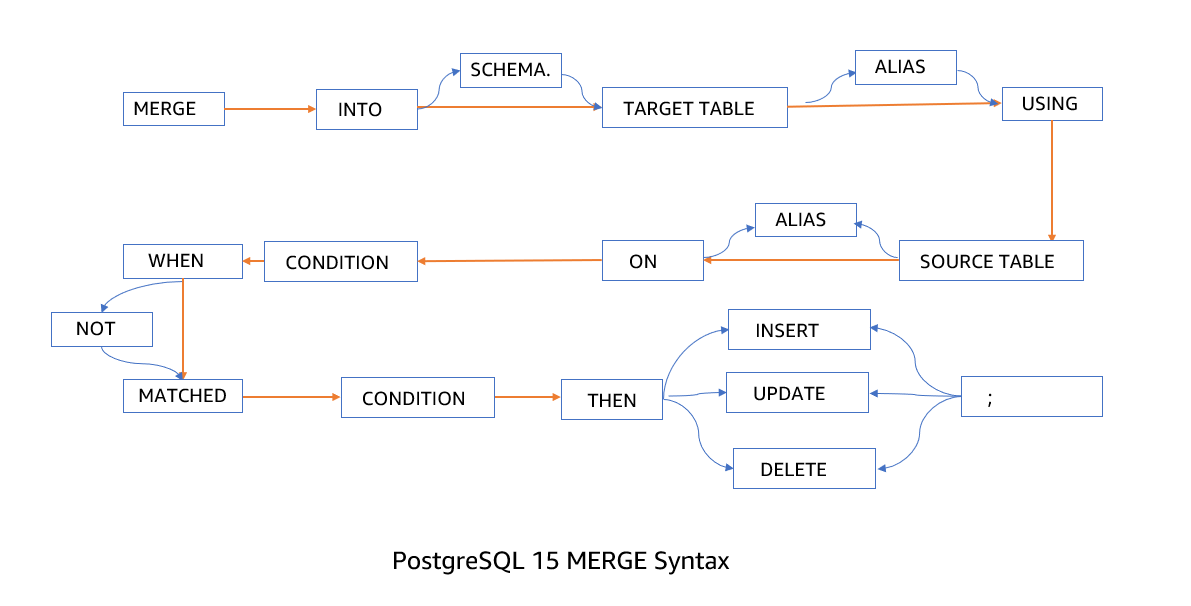
A typical PostgreSQL MERGE command looks like as below:
MERGE INTO target_table t1
USING source_table t2
ON t2.col1 = t2.col1
WHEN MATCHED THEN
UPDATE/INSERT/DELETE ...
WHEN NOT MATCHED THEN
UPDATE/INSERT/DELETE;Example of a MERGE Command
The image below explains a typical use case of the MERGE command in PostgreSQL. The source data that matches the target data can be updated or deleted, and the source data that does not match can be inserted into the target data.
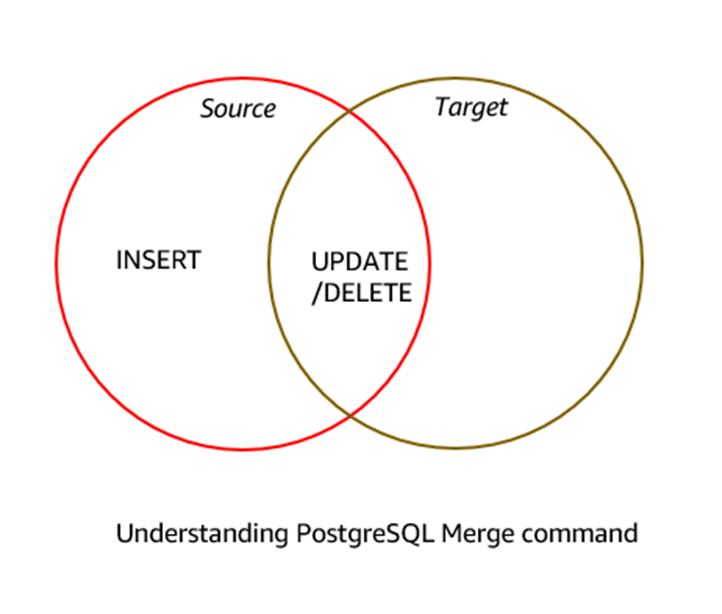
For example, the image below shows a classic data warehouse populated with data from various data marts.

Assume the data warehouse hosts data from IOT sensor stations. These stations host data marts 1, 2, 3, and so forth at respective stations. These data marts are hosted locally on the stations. In the steps below, we’ll merge data from different stations to the main stations.
Step-by-Step
Step 1: Create the Data Warehouse Table (Target Station Table)
Create the data warehouse table, the target station table that is loaded by other stations:
Postgres=> CREATE table station_main (
station_id integer primary key
, data text
, create_time timestamp default current_timestamp
, update_time timestamp default current_timestamp
);
CREATE TABLEStep 2: Insert Sample Data into the Target Table
Load some sample records into the target table:
postgres=> INSERT into station_main VALUES (1, 'data11'), (2, 'data22'), (3, 'data44'), (4, 'data44'), (5, 'data55');
INSERT 0 5Step 3: Verify Data Insertion
Check the data to ensure it's inserted correctly:
postgres=> SELECT * from station_main;
station_id | data | create_time | update_time
------------+--------+---------------------------+---------------------------
1 | data11 | 2023-08-11 21:21:30.19364 | 2023-08-11 21:21:30.19364
2 | data22 | 2023-08-11 21:21:30.19364 | 2023-08-11 21:21:30.19364
3 | data44 | 2023-08-11 21:21:30.19364 | 2023-08-11 21:21:30.19364
4 | data44 | 2023-08-11 21:21:30.19364 | 2023-08-11 21:21:30.19364
5 | data55 | 2023-08-11 21:21:30.19364 | 2023-08-11 21:21:30.19364
(5 rows)Step 4: Create a Table for Various Stations
Create a table for data from other stations:
postgres=> create table station_1 (
station_id integer
, data text
);
CREATE TABLE
Time: 4.288 msStep 5: Insert Sample Data into the Station Table
Insert sample records into the newly created station table:
postgres=> INSERT INTO station_1 VALUES (1, 'data11'), (2, 'data22'), (3, 'data44'), (4, 'data44'), (5, 'data55');
INSERT 0 5
Time: 2.221 msStep 6: Verify Data in Station 1
Check the inserted data in station_1:
postgres=> SELECT * from station_1;
station_id | data
------------+--------
1 | data11
2 | data22
3 | data44
4 | data44
5 | data55
(5 rows)Step 7: Insert New Data and Update Existing Data in Station 1
Assuming station_1 updates some base values and inserts new values, insert new data and update existing data:
postgres=> INSERT INTO station_1 VALUES (6, 'data66');
INSERT 0 1
postgres=>
postgres=> UPDATE station_1 set data='data10' where station_id=1;
UPDATE 1
postgres=>
postgres=> SELECT * from station_1;
station_id | data
------------+---------
2 | data22
3 | data44
4 | data44
5 | data55
6 | data66
1 | data10
(6 rows)Step 8: Merge Data from Station 1 to Station Main
If station_1 only inserts new data, we could have used INSERT INTO SELECT FROM command. But, in this scenario, few data have been modified, so we need to merge the data:
postgres=> MERGE INTO station_main sm
USING station_1 s
ON sm.station_id=s.station_id
when matched then
update set data=s.data
WHEN NOT MATCHED THEN
INSERT (station_id, data)
VALUES (s.station_id, s.data);
MERGE 6Verify data after the merge:
postgres=> SELECT * from station_main ;
postgres=> SELECT * from station_main ;
station_id | data | create_time | update_time
------------+--------+----------------------------+----------------------------
2 | data22 | 2023-08-11 21:27:23.076226 | 2023-08-11 21:27:23.076226
3 | data44 | 2023-08-11 21:27:23.076226 | 2023-08-11 21:27:23.076226
4 | data44 | 2023-08-11 21:27:23.076226 | 2023-08-11 21:27:23.076226
5 | data55 | 2023-08-11 21:27:23.076226 | 2023-08-11 21:27:23.076226
6 | data66 | 2023-08-11 21:29:13.354859 | 2023-08-11 21:29:13.354859
1 | data10 | 2023-08-11 21:27:23.076226 | 2023-08-11 21:27:23.076226
(6 rows)Advantages of the Merge Command
MERGE command helps easily manage a set of external data files such as application log files. For example, you can host data and log files into separate tablespaces hosted at cheaper storage disks and then create a MERGE table to use them as one.
Other advantages include:
- Better speed: Small source tables perform better than a single large table. You can split a large source table based on some clause and then use individual tables to merge into the target table.
- More efficient searches: Searching in underlying smaller tables is quicker than searching in one large table.
- Easier table repair: Repairing individual smaller tables is easier than a large table. Here, repairing tables means removing data anomalies.
- Instant mapping: A MERGE table does not need to maintain an index of its own, making it fast to create or remap. As a result, MERGE table collections are very fast to create or remap. (You must still specify the index definitions when you create a MERGE table, even though no indexes are created.)
If you have a set of tables from which you create a large table on demand, you can instead create a MERGE table from them on demand. This is much faster and saves a lot of disk space.
Use Cases of MERGE Command in PostgreSQL 15
Below are the common use cases of MERGE commands:
- IoT data collecting from various machines: Data coming from various machines can be saved in smaller temporary tables and can be merged with target data at certain intervals.
- E-commerce data: Product availability data coming from various fulfillment centers can be merge with central repository of target product table.
- Customer data: Customer transaction data coming from different sources can be merged with main customer data.
Automation of MERGE Command in PostgreSQL Using pg_cron
Automating MERGE is important for error-prone MERGE execution and reducing maintenance hassle. PostgreSQL supports pg_cron extension. This extension is used to configure scheduled tasks for a PostgreSQL database. A typical pg_cron command mentioned below shows the scheduling options:
SELECT cron.schedule('Minute Hour Date Month Day of the week', 'Task');
The pg_cron job below schedules MERGE command every minute:
SELECT cron.schedule('30 * * * *', $$MERGE INTO station_main sm
USING station_1 s
ON sm.station_id=s.station_id
when matched then
update set data=s.data
WHEN NOT MATCHED THEN
INSERT (station_id, data)
VALUES (s.station_id, s.data);$$);
Benchmarking: MERGE vs. UPSERT
In this section, we will benchmark and compare traditional UPSERT (i.e., INSERT with ‘ON CONFLICT’ clause) and the MERGE command.
Setup
Step 1: Create a target table with 1,000,000 records, with id column as primary key:
CREATE table target_table as
(SELECT
generate_series(1,1000000) AS id,
floor(random() * 1000) AS data);
ALTER TABLE target_table ADD PRIMARY KEY (id);
Step 2: Create a source data table with all the contents of the target table and id column as a primary key:
CREATE table source_table as SELECT * from target_table;
ALTER TABLE source_table ADD PRIMARY KEY (id); 
Step 3: Create a temporary table with additional data:
CREATE table source_table_temp as
(SELECT
generate_series(1000001,1200000) AS id,
floor(random() * 1000) AS data); 
Step 4: Insert data from the temporary table to the source table and update 400,000 rows:

Step 5: Turn timing on and run the UPSERT command. The total time taken for the UPSERT operation is 5904 ms.
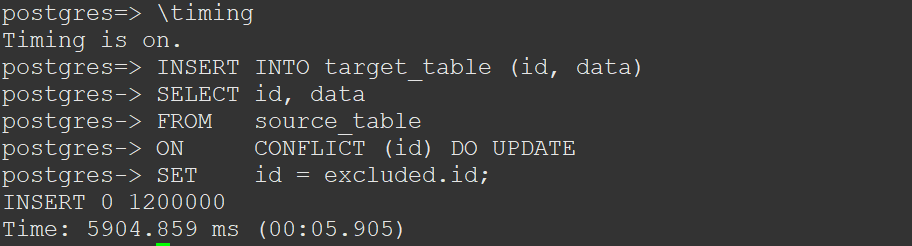
Now, we repeat the above steps and run the MERGE command. The total time it takes for the MERGE operation is 4,484 ms.

For our specific use case, we'll find that the MERGE command performed 30% better compared to the UPSERT operation.
Conclusion
MERGE command has been one of the most popular features added to PostgreSQL 15. It improved the performance of table refresh and makes table maintenance easier. Further, newly supported extensions, such as pg_cron can be used to automate MERGE operation.
Opinions expressed by DZone contributors are their own.
Comments