A Brief History of Logical Replication in Postgres
Learn how the Postgres logical replication feature has evolved over the years, what the recent improvements are, and how the feature will likely change.
Join the DZone community and get the full member experience.
Join For FreeThis blog is divided into two parts. In this section, we walk through how the Postgres logical replication feature has evolved over the years, what the recent improvements for logical replication are, and how the feature will likely change in the future. The second blog of the series will discuss the multi-master (active-active), multi-region, and highly available PostgreSQL cluster created by pgEdge that is built on top of logical replication and pgLogical.
Postgres replication is the process of copying data between systems. PostgreSQL supports two main methods of replication: logical replication and physical replication. Physical replication copies the data exactly as it appears on the disk to each node in the cluster. Physical replication requires all nodes to use the same major version to accommodate on-disk changes between the major versions of PostgreSQL.
Logical replication, on the other hand, is the method of replicating data based on data changes. The building blocks of the logical replication feature were introduced in PostgreSQL 9.4. However, the feature was completed in PostgreSQL 10. Logical replication provides fine-grained control over the replication set via a publisher/subscriber model where multiple subscribers can subscribe to one or more publishers. Logical replication uses logical decoding plugins that format the data so it can be interpreted by other systems. This makes replication possible among heterogeneous systems and across major PostgreSQL releases; this means it requires zero downtime for major version upgrades. Logical replication also provides fine-grained control over the replication set so you can decide whether to replicate an entire table, only certain columns from a table, or all of the tables within a schema.
Postgres Logical Replication Evolution in Chronological Order
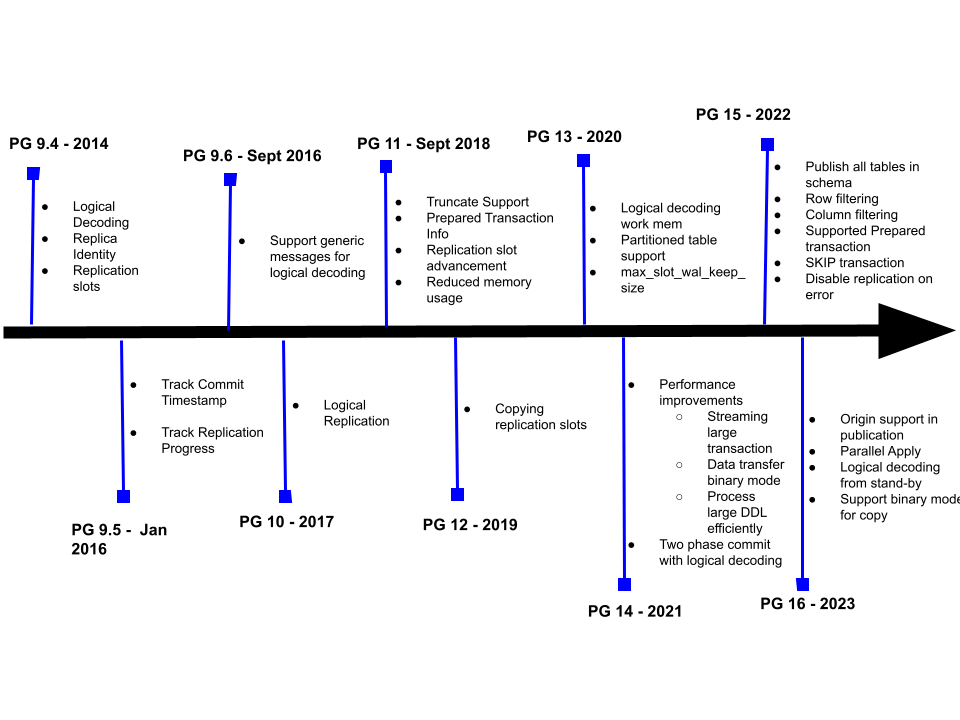
As mentioned above, the community began developing the underlying technology that made logical replication possible in PostgreSQL 9.4. These features are the core building blocks for the logical replication feature.
This section describes the main features for logical replication that were added in each release. To review a complete list of logical replication features for each release, please refer to the Replication and Recovery section of each version of the release notes.
This blog provides some context to the life cycle involved when building a major feature for PostgreSQL and allows you to see how a feature matures over time. The basic logical replication feature was committed to PostgreSQL 10; however, it required important patches in subsequent releases to make the feature performance feasible and usable. Logical replication is not finished yet; please read my thoughts in the final section on what might be on the roadmap for replication in the next set of releases.
PostgreSQL 9.4 - 2014
Logical Decoding
The basic idea behind logical decoding is to stream database changes out in a format that is understandable by other systems. Logical decoding is implemented by decoding the contents of WAL logs and streaming the changes in a customizable format. This decoding enables the logical replication to replicate changes to other heterogeneous systems.
Replica Identity
Replica identity is a new table-level parameter added to PostgreSQL 9.4 that can be used to control the information that is written to the WAL files. It can be used to identify if the tuple data that is being added or deleted. The replica identity is set to default and can only be changed with an ALTER TABLE statement. The other options are FULL (i.e., write maximum data, which is an expensive option) or NOTHING (which means write nothing).
Replication Slot
In the context of logical replication, the replication slot represents the persistent stream of changes that can be replayed on a client in the order they were made on the original server. We can have multiple replication slots for a single database; each slot has its own state, allowing different consumers to receive changes from different points in the database change stream. You can configure multiple receivers for a replication slot since the slots are unaware of the state of the receiver. Multiple receivers can be streaming data from a single slot at different points in time, receiving the changes after the last receiver stopped consuming them. Only one receiver may consume changes from a slot at any given time. Logical replication uses a publisher/subscriber model where multiple subscribers can receive data from a single publisher. The functionality of replication slots comes into play when providing this functionality.
PostgreSQL 9.5 - 2016 Jan
Track Commit Timestamp
track_commit_timestamp is a server level parameter that is configured in the postgresql.conf file. It can be set on any master node that sends replication data to one or more standby servers. The role and meaning of the parameter doesn’t change if the stand-by node becomes the master (the server that is sending the replication data). This is a boolean parameter that is set to off by default. The purpose of this parameter is to record the commit time of the transactions.
Track Replication Progress
Replication origins are added in PostgreSQL 9.5 to allow the implementation of a logical replication solution on top of logical decoding. Recording replication origin helps solve two problems with logical replication:
- How to safely keep track of replication progress.
- How to change replication behavior based on the origin of the row. This is particularly crucial for bi-directional replication to avoid getting stuck in a loop.
PostgreSQL 9.6 - 2016 Sept
Generic Messages for Logical Decoding
This feature allows an extension to insert data into WAL streams that can be read by the logical decoding plugin. These messages are either transactional (decoded on commit) or non-transactional (decoded immediately). For a standard WAL reply, these messages are NOOP, created with arbitrary data (user-specified). The messages are decoded in a logical decoding plugin with special callbacks of output plugins called.
Three main use cases for this feature are:
- Reliable communication between nodes in a multi-node replication setup.
- Out-of-order messaging in a logical replication scenario (allows sending a message immediately to a node).
- Support for queue tables. This is kind of the opposite of unlogged tables. A queue creates tables with the data itself, and all inserts go into the WAL without having to store the data.
PostgreSQL 10 - 2017
Logical Replication
The logical replication feature was added to PostgreSQL in version 10. Logical replication is a method of replicating data objects and changes to those objects based on replication identity. The logical replication feature provides security and fine-grained access control over a replication set. The term logical replication is used in contrast to physical replication, which performs replication using exact block addresses and byte-by-byte replication.
Logical replication uses a published/subscriber model where multiple subscribers can subscribe to a publisher. Subscribers pull data from the publications they are subscribed to and may do cascading replication by re-publishing data to other subscribers.
Logical replication provides control over the replication set so you can decide if you want to replicate a particular table or columns from a table or all the tables in a schema.
PostgreSQL 11 - 2018
Truncate Support
Replicating TRUNCATE statements to subscribers with logical replication. Previously, if an application issues a truncate statement, it wasn’t replicated to the subscriber nodes. With this feature in version 11, truncate functionality is replicated with logical replication.
Prepared Transaction Information
Passing prepared transaction information to logical replication subscribers.
Efficient Advancement of Replication Slots
This feature allows replication slots to be advanced programmatically instead of being consumed by the subscribers. This is particularly useful in the efficient advancement of replication slots when the contents don’t need to be consumed by the subscribers; this action is performed by the pg_replication_slot_advance() function.
Reduce Memory Usage: PostgreSQL 12 - 2019
Copying Replication Slots
The features allow the replication slots to be copied using pg_copy_physical_replication_slot() and pg_copy_logical_replication_slot() functions. The logical slot starts from the same LSN as the source logical slot.
PostgreSQL 13 - 2020
logical_decoding_work_mem
PostgreSQL 13 adds the logical_decoding_work_mem parameter to specify the amount of memory allocated to the WAL sender for saving changes in memory before spilling it to the disk. You can increase the parameter value to keep more changes in memory and reduce disk writes or decrease the value to reduce the memory usage of the WAL sender. The default value of this parameter is 64 MB, and it doesn’t require a database server restart, but the configuration file needs to be reloaded if it is modified. Each subscription spawns a WAL sender process on the publisher node to process the changes from publisher to subscriber. The size of the WAL sender process determines the amount of changes to keep in memory before spilling it to the disk. The logical_decoding_work_mem parameter will control this memory usage for logical replication.
Partitioned Table Support
Prior to this feature, the partitions on a partitioned table needed to be replicated individually. PostgreSQL 13 allows you to logically replicate partitioned tables; you can publish the partition table explicitly, and all its partitions will be automatically replicated. The addition or removal of partitions from the table likewise needs to be added or removed from the publication. The publish_via_partition_root option (used when creating a publication) controls whether the changes to a partition contained in the publication will be published using the identity and schema of the parent table rather than that of the partitions that are actually changed.
PostgreSQL 13 also supports logical replication of partitioned tables on the subscribers; previously, this was only supported for non-partitioned tables.
max_slot_wal_keep_size (integer)
The max_slot_wal_keep_size parameter can be set in the postgresql.conf file or on the command line. It determines the number of WAL files required by replication_slots to be kept in the pg_log directory; any replication slots exceeding the specified value are marked invalid.
PostgreSQL 14 - 2021: Performance Improvements
Streaming Large In-Progress Transactions
This feature in version 14 allows streaming large in-progress transactions to the subscribers. Previously, all large in-progress transactions exceeding the logical_decoding_work_mem value would be written to disk until the transaction is completed. This improves the performance of logical replication for large transactions.
Data Transfer in Binary Mode
PostgreSQL 14 provides the ability to create subscriptions with binary transfer mode instead of text mode (the default). The binary transfer mode is faster than text.
Process Large DDL Efficiently
Allow logical decoding to more efficiently process cache invalidation messages. This improves logical replication efficiency when processing large amounts of DDL.
Support Two-Phase Commit With Logical Decoding
The logical decoding API is enhanced to support two-phase commits. The two-phase commit is controlled by the pg_create_logical_replication_slot() function. The optional parameter, two-phase, when set to true, specifies that the decoding of prepared transactions is enabled for this slot.
PostgreSQL 15 - 2022
Publish All Tables in the Schema
Version 15 supports the syntax for including all tables in a schema for publication: CREATE PUBLICATION pub1 FOR TABLES IN SCHEMA foo. This command includes all the tables in schema foo in the publication; any table added to the schema at a later time is automatically included in the publication.
Row Filtering
This feature allows publication content to be filtered using a WHERE clause. Any rows that don't satisfy the WHERE clause are omitted from the publication.
Column Filtering
This feature allows publication content to be filtered for specific columns. Only the specified columns are included in the publication.
Support for Prepared Transactions
Logical replication of prepared transactions is supported in the version 15 release. Also, the new create_replication_slot option supports a two-phase option for slot creation.
SKIP Transaction
The ability to skip transactions on the subscriber is supported with the ALTER SUBSCRIPTION… SKIP command. This command skips conflicting transactions on the subscriber; you can specify the last LSN by using the skip_option to indicate the failed transaction.
Disable Replication on Error
The disable_on_error option is supported while creating a subscription. This option allows replication to be stopped when an error is raised by the subscriber. This prevents infinite loops if an error is caused by the replicating transaction.
PostgreSQL 16 - 2023
Filtering Based on Publication Origin
This feature in PostgreSQL 16 supports the origin = NONE clause while creating a subscription; the other value supported for origin is ANY. Setting the origin to NONE means that the subscriber is only requesting replication changes that don’t have an origin — setting the origin to ANY means sending changes regardless of the origin. This prevents loops in bi-directional replication.
Allow Logical Decoding From Standby
Allowing logical decoding from stand-by means that subscribers can subscribe from the stand-by, reducing the load on the primary server. This wasn’t possible prior to PostgreSQL 16. It requires that wal_level be set to logical on both the primary and standby servers.
Parallel Apply
The parallel apply feature is a significant performance improvement for logical replication in PostgreSQL 16. It supports large in-progress transactions by allowing multiple parallel workers to be used on the subscriber to apply changes. The user can specify the parallel streaming option while creating the subscriber. The max_parallel_apply_workers_per_subscription parameter controls the maximum number of parallel workers per subscription.
Support Binary Mode for COPY
Prior to PostgreSQL 16, text mode was only supported for the initial table copy, and binary transfer mode was only supported for the replication of changes. With PostgreSQL 16, you can set binary=true while creating the subscription to perform the initial data copy in binary mode (much faster than text mode). This option is only supported if both publisher and subscriber are on PostgreSQL 16.
Logical Replication: Looking Ahead
The building blocks for logical replication were added in PostgreSQL 9.4, but the logical replication feature was added in PostgreSQL 10. Since that release, there have been a number of important improvements to logical replication. The last two major releases of PostgreSQL have contributed to the performance and usability of logical replication with parallel application on the subscriber, allowing binary mode initial copy, supporting row/column-based filtering, and more.
Looking ahead at PostgreSQL 17 (and beyond) for logical replication, there is definitely a requirement for more performance improvement by increasing the replication rate and reducing the replication lag. I believe this can be achieved with parallelism support and worker optimization. There is also a need for better integration of logical replication with external tools for high availability and upgrades. The possibility of active-active (multi-master) replication is also approachable as part of the PostgreSQL core, but it is missing major features like conflict detection and resolution.
Some of the missing but important features are provided by pgEdge's distributed PostgreSQL Spock extension. pgEdge provides a fully distributed PostgreSQL cluster that supports active-active replication with low latency, high availability, and data residency. Multi-master replication and the pgEdge clustering solution will be discussed in the next post of this series.
Published at DZone with permission of Ahsan Hadi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments