Introduction to Apache Kafka With Spring
Introduction to Apache Kafka with Spring.
Join the DZone community and get the full member experience.
Join For FreeApache Kafka is a community-distributed streaming platform that has three key capabilities: publish and subscribe to streams of records, store streams of records in a fault-tolerant durable way, and then process streams as they occur. Apache Kafka has several successful cases in the Java world. This post will cover how to benefit from this powerful tool in the Spring universe.
Apache Kafka Core Concepts
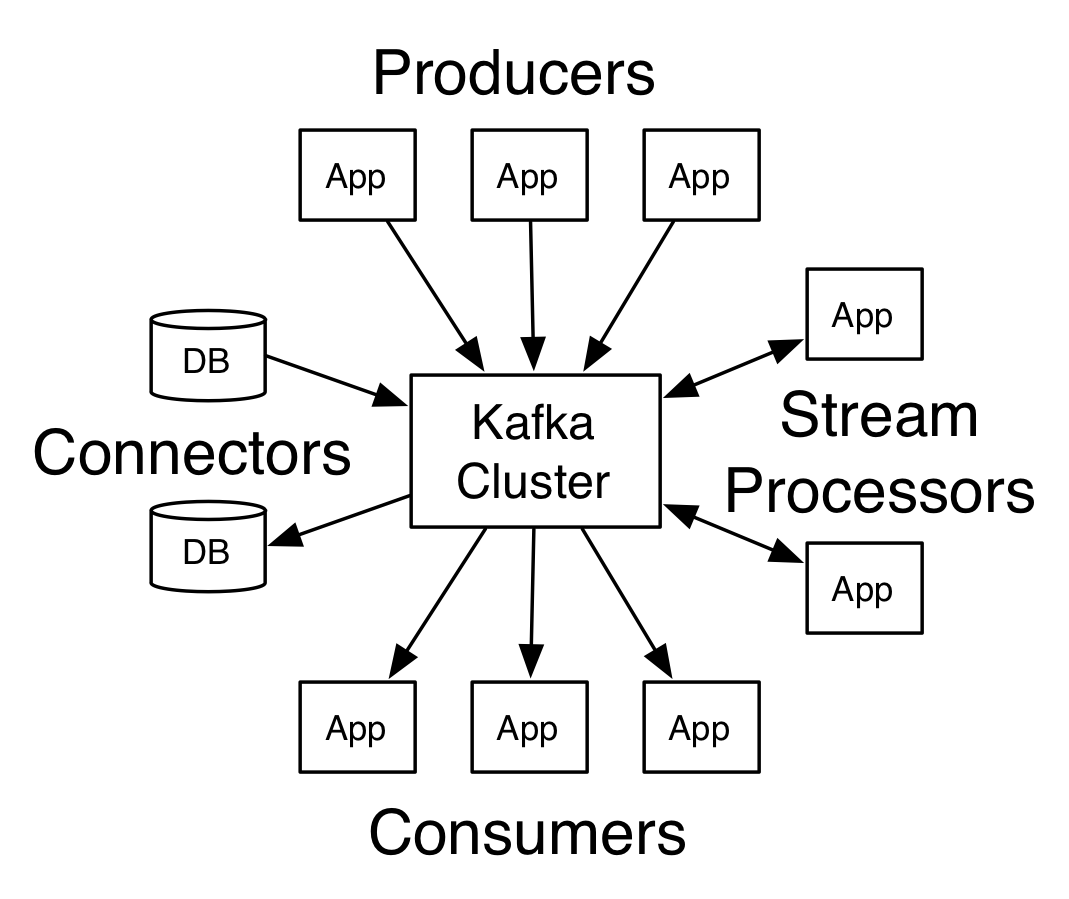
Kafka is run as a cluster on one or more servers that can span multiple data centers; Kafka cluster stores a stream of records in categories called topics, and each record consists of a key, a value, and a timestamp.
From the documentation, Kafka has four core APIs:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems.
Using Docker
There is also the possibility of using Docker. As it requires two images, one to Zookeeper and one to Apache Kafka, this tutorial will use docker-compose. Follow these instructions:
- Install Docker
- Install Docker-compose
- Create a docker-compose.yml and set it with the configuration below:
x
version'2.1'
services
zoo
imagezookeeper3.4.9
hostnamezoo1
ports
"2181:2181"
environment
ZOO_MY_ID1
ZOO_PORT2181
ZOO_SERVERSserver.1=zoo128883888
kafka
imageconfluentinc/cp-kafka5.5.1
hostnamekafka1
ports
"9092:9092"
environment
KAFKA_ADVERTISED_LISTENERSLISTENER_DOCKER_INTERNAL//kafka119092,LISTENER_DOCKER_EXTERNAL//$DOCKER_HOST_IP-127.0.0.19092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAPLISTENER_DOCKER_INTERNALPLAINTEXT,LISTENER_DOCKER_EXTERNALPLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAMELISTENER_DOCKER_INTERNAL
KAFKA_ZOOKEEPER_CONNECT"zoo1:2181"
KAFKA_BROKER_ID1
KAFKA_LOG4J_LOGGERS"kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR1
depends_on
zoo
Then, run the command:
xxxxxxxxxx
docker-compose -f docker-compose.yml up –d
To connect as localhost, also define Kafka as the localhost within Linux, append the value below at t
he /etc/hosts:
xxxxxxxxxx
127.0.0.1 localhost kafka
Application With Spring
To explore Kafka, we'll use the Spring-kafka project. In the project, we'll simple a name counter, where based on a request it will fire an event to a simple counter in memory.
The Spring for Apache Kafka (spring-kafka) project applies core Spring concepts to the development of Kafka-based messaging solutions. It provides a "template" as a high-level abstraction for sending messages. It also provides support for Message-driven POJOs with @KafkaListener annotations and a "listener container". These libraries promote the use of dependency injection and declarative. In all these cases, you will see similarities to the JMS support.
The first step in a Spring project maven based, where we'll add Spring-Kafka, spring-boot-starter-web.
Spring-kafka by default uses the String to both serializer and deserializer. We'll overwrite this configuration to use JSON where we'll send Java objects through JSON.
x
spring.kafka.consumer.value-deserializer=org.springframework.kafka.support.serializer.JsonDeserializer
spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.JsonSerializer
spring.json.add.type.headers=false
spring.kafka.consumer.properties.spring.json.trusted.packages=*
The first class is a configuration to either create a topic if it does not exist. Spring has a TopicBuilder to define the name, partition, and replica.
xxxxxxxxxx
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.TopicBuilder;
public class TopicProducer {
static final String NAME_INCREMENT = "name_increment";
static final String NAME_DECREMENT = "name_decrement";
public NewTopic increment() {
return TopicBuilder.name(NAME_INCREMENT)
.partitions(10)
.replicas(1)
.build();
}
public NewTopic decrement() {
return TopicBuilder.name(NAME_DECREMENT)
.partitions(10)
.replicas(1)
.build();
}
}
KafkaTemplate is a template for executing high-level operations in Apache Kafka. We'll use this class in the name service to fire two events, one to increment and another one to decrement, in the Kafka.
xxxxxxxxxx
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
public class NameService {
private final NameCounter counter;
private final KafkaTemplate<String, Name> template;
public NameService(NameCounter counter, KafkaTemplate<String, Name> template) {
this.counter = counter;
this.template = template;
}
public List<NameStatus> findAll() {
return counter.getValues()
.map(NameStatus::of)
.collect(Collectors.toUnmodifiableList());
}
public NameStatus findByName(String name) {
return new NameStatus(name, counter.get(name));
}
public void decrement(String name) {
template.send(TopicProducer.NAME_DECREMENT, new Name(name));
}
public void increment(String name) {
template.send(TopicProducer.NAME_INCREMENT, new Name(name));
}
}
Once we talked about the producer with the KafkaTemplatethe next step is to define a consumer class. A Consumer class will listen to a Kafka event to execute an operation. In this sample, the NameConsumer will listen to events easily with the KafkaListener annotation.
xxxxxxxxxx
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.logging.Logger;
public class NameConsumer {
private static final Logger LOGGER = Logger.getLogger(NameConsumer.class.getName());
private final NameCounter counter;
public NameConsumer(NameCounter counter) {
this.counter = counter;
}
(id = "increment", topics = TopicProducer.NAME_INCREMENT)
public void increment(Name name) {
LOGGER.info("Increment listener to the name" + name);
counter.increment(name.get());
}
(id = "decrement", topics = TopicProducer.NAME_DECREMENT)
public void decrement(Name name) {
LOGGER.info("Decrement listener to the name " + name);
counter.decrement(name.get());
}
}
To conclude, we see the potential of Apache Kafka and why this project became so accessible to Big-Data players. This is a simple example of how secure it is to integrate with Spring.
References:
Opinions expressed by DZone contributors are their own.
Comments