Introduction to IAM in Google Cloud Platform (GCP)
An introduction to identity and access management (IAM) for anyone getting started with GCP or even experienced professionals who are looking for a structured overview.
Join the DZone community and get the full member experience.
Join For FreeIdentity and access management (IAM) is one of the most important security controls in cloud infrastructure environments like GCP. Since nearly every action performed is an API call — including the provisioning, deprovisioning, and manipulation of resources — all a malicious actor needs to get into your environment is the wrong binding of a permission to the wrong identity, or alternatively, a compromised identity.
For this reason, it’s crucial to pay close attention to the permissions that grant access to resources in your GCP organization and make sure only the minimum number of permissions required to perform business functions are provided. In other words, you need to maintain least-privilege for all identities — both humans and services — at all times.
This article will review the main mechanism through which permissions to resources are managed in GCP. This is a great introduction for anyone getting started with GCP or even for experienced professionals who are looking for a structured overview.
GCP employs a Role Based Access Control (RBAC) mechanism for permission assignment. RBAC means that any permission assignment is based on the functions the identity is supposed to perform. The implementation uses permission documents called “Roles” and defines the connection between an identity (or a “Principal”), a “Role,” and a “Scope” — the level of the resource hierarchy where the permissions apply.
The figure below illustrates the objects relevant to GCP IAM and how they map against one another to assign an identity to a set of permissions for a resource (or a set of resources). We will explore all these terms.

Since the Scope is such an important concept in the GCP IAM paradigm, structuring the resources in your organization properly is extremely important. For this reason, we will start by discussing how resources should be structured.
Resource Structure
When you start using GCP, an Organization resource is created for you:
When a user with a Google Workspace or Cloud Identity account creates a Google Cloud Project, an Organization resource is automatically provisioned for them.
The organization resource represents the company that owns it and is the container for the Folders, Projects, and resources that are structured together in a hierarchy; this structure allows for management of various policies and IAM is one of the most important.
Figure 2 shows the resource hierarchy in the GCP Organization resource.

Projects are the atomic container used to manage resources relevant to the same deployment (e.g., development/testing/staging/production) of an application — for example, <APP_NAME>-development, <APP_NAME>-staging, or <APP_NAME>-production. It’s also the main billing unit for resources as it has a 1-to-1 relationship with a billing account. If you are familiar with Azure, you’ll see that these two functions make the Project an equivalent to both Azure’s Resource Group (which is meant to contain resources relevant to the same application) and Azure’s Subscription (which is the main billing unit).
Projects may reside directly under the organization resource or in a Folder.
Folders are supposed to correspond with your organizational structure to provide structure for the Projects in the organization. They support nesting, so a folder may have sub folders in it.
In the context of IAM, structuring resources properly is of vital importance as permissions may be granted for a specific resource, or a container of resources at any of the levels — organization, folder, or project (we will demonstrate this concept later on). If you structure your resources to properly correspond with your business, providing the right access is much easier.
The next section will review the various identities to which access may be granted.
Identities
Google Workspace/Cloud Identity
Google Cloud Identity is an “Identity as a Service (IDaaS) solution that centrally manages users and groups”. It’s basically an identity provider (IdP) in which you create the user and group objects and manage parameters such as security factors (MFA) and application access. For simplicity’s sake, we’ll simply refer to this service as Google Cloud Identity, but keep in mind you may know it as Google Workspace.
In Google Cloud Identity, you manage users and groups, and the entire user roster in a Google Cloud Identity instance may also be referred to by using the Domain identity.
Users
In Google Workspace, you manage user objects for your organization. Users are uniquely identified by their email and are divided into Organizational Units (OUs) which is useful for setting policies such as MFA and application access. However, OUs are NOT relevant for managing IAM access to Google Resources.

Google Groups
The relevant mechanism for managing user access to GCP resources is Google Groups. As Google Groups traditionally started as a solution for mailing distribution lists (and are still frequently used for this purpose) they are also uniquely identified by an email account. For our purposes, you can use this unique identifier to assign Google Groups with permissions for your cloud resources (which we will see later). When you do so, you provide access to all the identities that belong to that Google Group. It’s a much better practice to provide access to Google Groups rather than manage the permissions for each user separately.
Note that Google Groups may be nested and include other Google Groups (which will inherit the permissions assigned to the group) AND a Google Group may include service accounts (which we review in the next section).
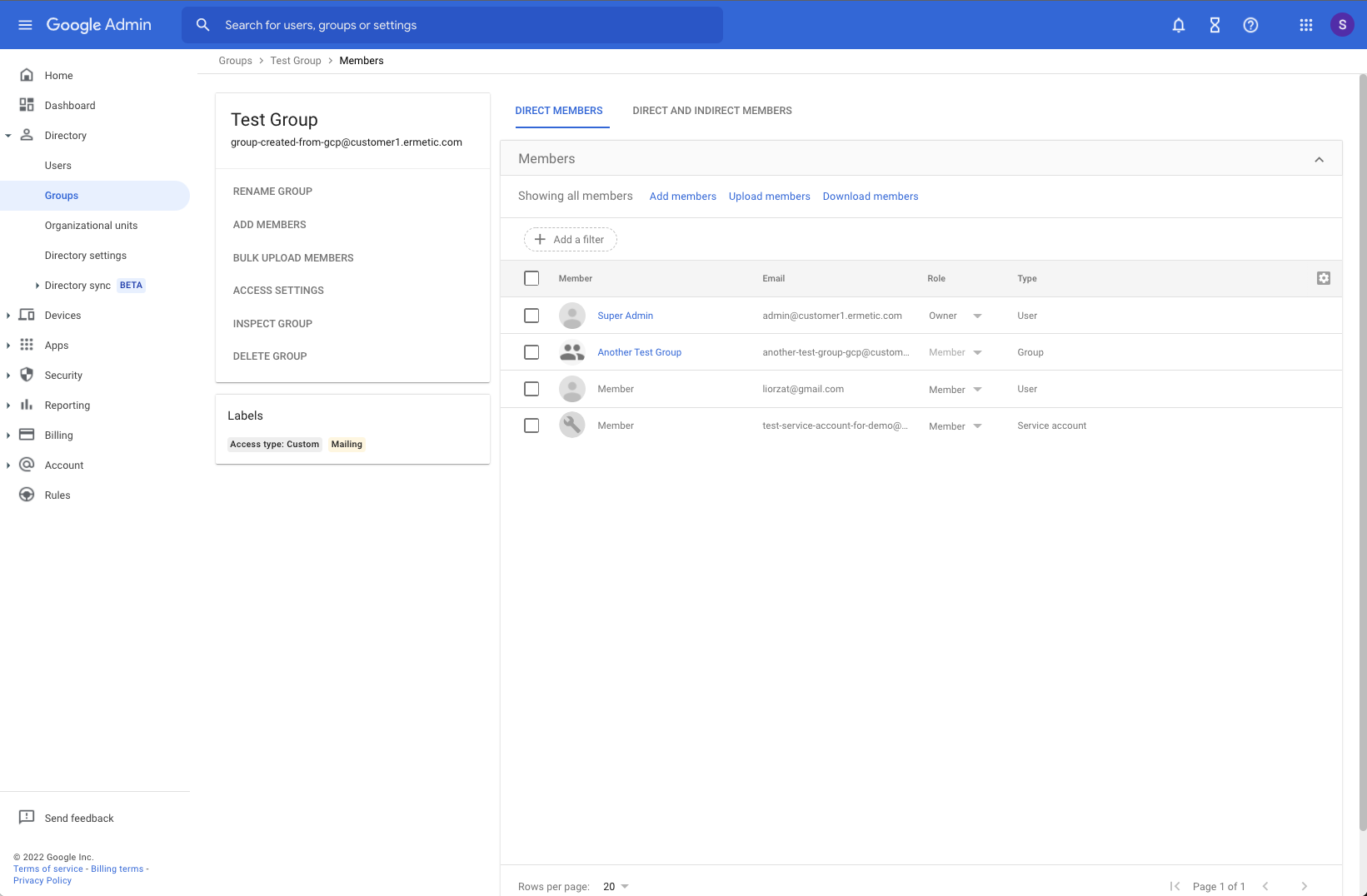
Google Groups are very different from OUs; while OUs are rigid and a user can only belong to one of them (as they are meant to correspond with the organizational structure as defined by your HR department) a user may belong to several groups simultaneously (and thereby receive several sets of permissions or be a member of several distribution lists). In addition, Google Groups may include identities from outside your organization, as they don’t have to adhere to your organization’s structure as OUs do. This is important to keep in mind as the permissions assigned to the group will also apply to these users as well and by definition, they are riskier to manage from a technical and legal perspective.
Domain
Finally, an object you must be familiar with in the context of GCP Workspace is the domain.
Each Google Cloud Identity has a primary domain (in the form of “@company_name.com”); this primary domain can be used when assigning permissions to cloud resources to ALL the users that are managed in the Google Cloud Identity instance.
Two things are important to note here: First, assigning permissions to the primary domain will allow access to all the users managed in that Cloud Identity instance, but not to the Google Groups that are managed there. The logic behind this is clear, as allowing access to the identities in the Google Groups may also allow access to external identities and that would be a huge security hazard.
Second, a Cloud Identity instance may also have secondary domains (in fact, as many as 599 secondary domains!). For this reason, we highlight the fact that the primary domain is the one that counts, and not the actual domain of the users (which is not relevant). For example, if you have a secondary domain (e.g., “@secondary.com”) in your Cloud Identity environment and your primary domain is “@primary.com”, assigning access to “@primary.com” would in fact provide access to all the users with the “@secondary.com” suffix that are managed in the Cloud Identity instance. The fact that they have a different domain than the one permissions were assigned to is irrelevant.
Now, let’s move on to identities managed in GCP itself.
Service Accounts
Service accounts are a type of proxy identity that serve a very important purpose in GCP.
What proxy identity means is that other entities such as resources may use it to access other resources. (Like a role in AWS?)
A service account may be used by a Google Cloud Identity user, a personal Gmail account, another service account (even if it resides in a different organization), a Google Group, and basically any kind of identity that may be assigned permissions.
How a Service Account Works
Using the service account can be done in one of three ways:
- The service account can be attached to a resource, and that resource may then use the permissions assigned to the service account when the resource runs workloads; for example, a compute instance is attached a service account and when code runs on it, it will be able to access the permissions assigned to the service account. In order to do so, the permission
iam.serviceAccounts.actAshas to be available to the identity provisioning the resource to which the service account is attached (in our example, the computing instance). - The service account may be directly impersonated using the action
iam.serviceAccounts.actAswhich allows the identity performing the impersonation to be able to use the permissions assigned to the service account. - Finally, service accounts support creating short lived credentials which can then be used when making API calls to leverage the permissions assigned to the service account.
Service Account Types
There are three notable types of service accounts:
- User-managed: service accounts created and managed by administrators of the GCP project.
- Default: service accounts which are created by Google and may be managed by the administrator of a project. They are suggested as the default (hence the name) service account to be attached to a resource of a certain type. It’s crucial to be familiar with this mechanism as sometimes these default service accounts are granted very permissive permissions, such as the Compute Engine Default Service Account, which by default is granted the “Editor” basic role on a project (which, as we will soon see, is very permissive).
- Google-managed: these are service accounts that are created by Google when relevant services that need access to cloud resources in a project are enabled. These service accounts are by default granted certain roles (which can be removed by a project administrator, however this is NOT a recommended practice). We reviewed this topic and some of the risks associated with it in a recent blog post.
Beware of Static Credentials
Another important feature of Service Accounts is the ability to generate Key Pairs for them. A Key Pair is basically a set of strings that enables authentication as the service account, and once this is done, you can perform actions on behalf of the service account with full access to all the permissions it has.
This is of course a huge security hazard if not managed properly, and some may argue you should avoid using these altogether. Imagine that these keys fall in the wrong hands — for example, if they are improperly stored in a public resource such as a storage bucket, a public document, a public code repository, an environment variable many people have access to, and so on. A malicious actor may hold to them and use them without you knowing.
For this reason, you must avoid using key pairs for service accounts as much as possible. For example, if a workload needs access to permissions, it’s much safer to attach a service account to the resource on which the workload is running (a Cloud Function or Compute Instance) instead of using a key pair, storing it somewhere and having the workload use it to authenticate (even if it is stored securely, it’s never guaranteed not to leak). Also, developers should not use key pairs locally to use the GCP CLI, when they can use Google accounts with enforced MFA to authenticate.
Probably the worst thing you can do with a key pair is provide it to a 3rd party that requests it to access resources in your account. It’s very difficult to guarantee the safety of static credentials when only used by your own employees — making sure they are safe in the hands of a third party is virtually impossible.
Finally, if you are in fact in a position where you must use key pairs, make sure they are properly stored and rotated regularly (at least once every 90 days).


Special Identifiers
The last type of identity we want to make note of are two special identifiers: allUsers and allAuthenticatedUsers.
Respectively, they allow access to “anyone who is on the internet” and “all service accounts and all users on the internet who have authenticated with a Google Account.” So basically, using either of them on a permission assignment makes that assignment public for the resources where it applies. Would be good to give an example here.
Many people believe these identifiers to only be relevant in the context of users in their Google Cloud Identity instance — which is of course not the case. So, watch out!
Roles
The third, and probably easiest, object to understand is the Role.
A Role is simply a document listing permissions. In the next section we’ll see how a binding is created and the permissions assignment is actually created, but first let’s review the three types of Roles.
Basic
These are legacy roles that were created and managed by Google (they may also be referred to as “Primitive” Roles). They are extremely permissive and are generic to all resource types (so as you may expect, they hold a huge list of permissions).
There are three Basic Roles: Viewer, Editor, and Owner.
You must be really careful when using them — preferably avoid using them all together. As we mentioned before, you might also want to replace them in situations where they are granted by default, such as for the default service account for the Compute Engine which is granted the Editor Role on a project where the computing service is enabled.
Do not grant these roles to users external to your Google Cloud Identity or to service accounts outside your GCP organization.
There are also additional risks around some of the permissions these roles provide — we’ll explore this topic in greater length in an upcoming post. Stay tuned!
Predefined
Like Basic Roles, Predefined Roles are created and managed by Google. However, they are much more granular and are usually defined for a specific type of resource and a specific job duty/function. For example, the predefined Role: Storage Object Viewer allows viewing objects in storage buckets.
Even though they are less risky than Basic roles as they include far fewer permissions, you should still pay attention when using them as you may apply them to a very wide scope (a Project, Folder, or Organization) and doing so will provide the permissions to all the resources residing under the scope.
Custom
Finally, you can create and manage your own custom roles which are a list of permissions that you tailor based on a specific function.
Using these roles is a challenge since you must be extremely familiar with the activity your identities need to perform. However, if you configure them correctly, they are the best way to achieve least privilege.
Putting it All Together: Creating a Binding
To put this all together, we will now use the concepts we reviewed — Identities, Roles and Resource structures with various scopes — and see how permissions are actually granted.
To grant a permission, you create what is called a “binding” — an object that makes the connection between a Role (a set of permissions) which is granted to an identity (any of the ones we mapped above) for a particular scope — a resource or container of resources.
These bindings are clustered in a document called an IAM Policy which exists on each scope. A binding includes the role and the members (identities) to which the role can be granted. It can optionally also contain conditions to limit when and where the binding applies. Figure 7 shows an example of an IAM policy:

A binding can be created for external users (such as personal Gmail accounts, service accounts of 3rd parties, and so on) just as easily as for users from your Google Cloud Identity instance or service accounts in your organization. An example of this can be seen in figure 8. So, pay close attention to this! In addition, it’s very hard to keep track of external identities with access to resources in your organization as there is no specific native tool in GCP that centralizes them all in one display.

Finally, it’s important to remember that, as explained above, granting a role on scope is inherited to the scopes below it — containers and resources. Figure 9 demonstrates this:

In the diagram, the Compute Admin role applies to all the compute resources that are present in the scopes where it’s set. The Owner role, which is a Basic role, applies to both compute and cloud functions resources.
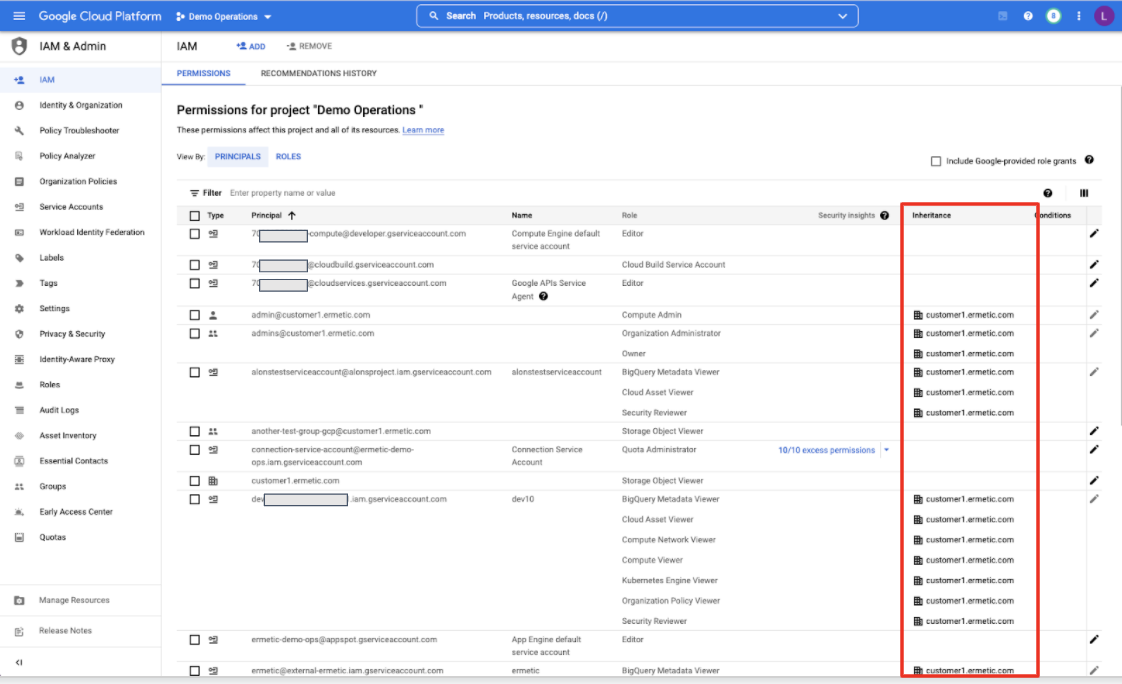
This can also be seen in the IAM blade of each scope, where you can find a list of all the bindings either made for it directly or inherited by membership of a wider scope. In figure 10 you can see an example of this visualization for a GCP Project: along with the role and the principal, there’s an “inheritance” column that clearly states if the permission is due to a direct binding or is inherited from a scope the project belongs to (in this specific example from bindings done on the organization resource the project belongs to).
Final Words
We hope this review has been useful in giving you a clear overview of the RBAC paradigm in GCP.
Published at DZone with permission of Lior Zatlavi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments