Introduction to Modern Data Stack
Exploring how the modern data stack revolutionizes data management with scalable cloud solutions, automated tools, and advanced analytics capabilities.
Join the DZone community and get the full member experience.
Join For FreeThe modern data stack represents the evolution of data management, shifting from traditional, monolithic systems to agile, cloud-based architectures. It's designed to handle large amounts of data, providing scalability, flexibility, and real-time processing capabilities. This stack is modular, allowing organizations to use specialized tools for each function: data ingestion, storage, transformation, and analysis, facilitating a more efficient and democratized approach to data analytics and business operations. As businesses continue to prioritize data-driven decision-making, the modern data stack has become integral to unlocking actionable insights and fostering innovation.
The Evolution of Modern Data Stack
The Early Days: Pre-2000s
Companies use big, single systems to keep and manage their data. These were good for everyday business tasks but not so much for analyzing lots of data. Data was stored in traditional relational databases like Oracle, IBM DB2, and Microsoft SQL Server.
The Big Data Era: Early 2000s - 2010s
This period marked the beginning of a shift towards systems that could handle massive amounts of data at high speeds and in various formats. We started to see a lot more data from all over, and it was coming in fast. New tech like Hadoop helped by spreading out the data work across many computers.
The Rise of Cloud Data Warehouses: Mid-2010s
Cloud computing started to revolutionize data storage and processing. Cloud data warehouses like Amazon Redshift and Google BigQuery offered scalability and flexibility, changing the economics and speed of data analytics. Also, Snowflake, a cloud-based data warehousing startup, emerged, offering a unique architecture separating computing and storage.
The Modern Data Stack: Late 2010s - Present
The modern data stack took shape with the rise of ELT processes, SaaS-based data integration tools, and the separation of storage and compute. This era saw the proliferation of tools designed for specific parts of the data lifecycle, enabling a more modular and efficient approach to data management.
Limitations of Traditional Data Systems
In my data engineering career, across several organizations, I've extensively worked with Microsoft SQL Server. This section will draw from those experiences, providing a personal touch as I recount the challenges faced with this traditional system. Later, we'll explore how the Modern Data Stack (MDS) addresses many of these issues; some solutions were quite a revelation to me!
Scalability
Traditional SQL Server deployments were often hosted on-premises, which meant that scaling up to accommodate growing data volumes required significant hardware investments and could lead to extended downtime during upgrades. What's more, when we had less data to deal with, we still had all these extra hardware that we didn't really need. But we were still paying for them. It was like paying for a whole bus when you only need a few seats.
Complex ETL
SSIS was broadly used for ETL; while it is a powerful tool, it had certain limitations, especially when compared to more modern data integration solutions. Notably, Microsoft SQL Server solved a lot of these limitations in Azure Data Factory and SQL Server Data Tools (SSDT).
- API calls: SSIS initially lacked direct support for API calls. Custom scripting was required to interact with web services, complicating ETL processes.
- Memory allocation: SSIS jobs needed careful memory management. Without enough server memory, complex data jobs could fail.
- Auditing: Extensive auditing within SSIS packages was necessary to monitor and troubleshoot, adding to the workload.
- Version control: Early versions of SSIS presented challenges with version control integration, complicating change tracking and team collaboration.
- Cross-platform accessibility: Managing SSIS from non-Windows systems was difficult, as it was a Windows-centric tool.
Maintenance Demands
The maintenance of on-premises servers was resource-intensive. I recall the significant effort required to ensure systems were up-to-date and running smoothly, often involving downtime that had to be carefully managed.
Integration
Integrating SQL Server with newer tools and platforms was not always straightforward. It sometimes required creative workarounds, which added to the complexity of our data architecture.
How the Modern Data Stack Solved My Data Challenges
The Modern Data Stack (MDS) fixed a lot of the old problems I had with SQL Server. Now, we can use the cloud to store data, which means no more spending on big, expensive servers we might not always need. Getting data from different places is easier because there are tools that do it all for us, and there is no more tricky coding.
When it comes to sorting and cleaning up our data, we can do it straight into the database with simple commands. This avoids the headaches of managing big servers or digging through tons of data to find a tiny mistake. And when we talk about keeping our data safe and organized, the MDS has tools that make this super easy and way less of a chore.
So with the MDS, we're saving time, we can move quicker, and it's a lot less hassle all around. It's like having a bunch of smart helpers who take care of the tough stuff so we can focus on the cool part—finding out what the data tells us.
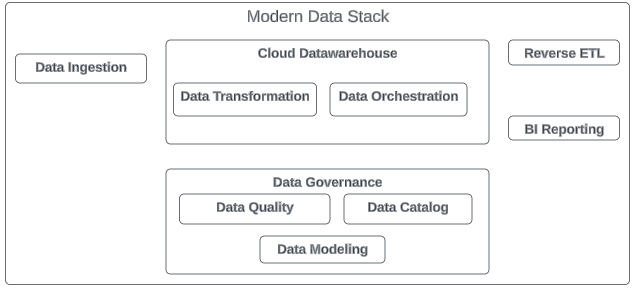
Components of the Modern Data Stack
MDS is made up of various layers, each with specialized tools that work together to streamline data processes.
Data Ingestion and Integration
The extraction and loading of data from diverse sources, including APIs, databases, and SaaS applications.
Ingestion tools
fivetran, stitch, airbyte, segment, etc.
Data Storage
Modern cloud data warehouses and data lakes offer scalable, flexible, and cost-effective storage solutions.
Cloud Data Warehouses
Google Bigquery, Snowflake, Redshift, etc.
Data Transformation
Tools like dbt (data build tool) enable transformation within the data warehouse using simple SQL, improving upon traditional ETL processes.
Data Analysis and Business Intelligence
The analytics and Business Intelligence tools allow for advanced data exploration, visualization, and sharing of insights across the organization.
Business Intelligence Tools
Tableau, Looker, Power BI, Good Data
Data Extraction and Reverse ETL
Enables organizations to operationalize their warehouse data by moving it back into business applications, driving action from insights.
Reverse ETL tools
Hightouch, Census
Data Orchestration
Platforms that help automate and manage data workflows, ensuring that the right data is processed at the right time.
Orchestration Tools
Airflow, Astronomer, Dagster, AWS Step Functions
Data Governance and Security
Data governance focuses on the importance of managing data access, ensuring compliance, and protecting data within the MDS. Data Governance also provides comprehensive management of data access, quality, and compliance while offering an organized inventory of data assets that enhances discoverability and trustworthiness.
Data Catalog Tools
Alation (for data cataloging), Collibra (for governance and cataloging), Apache Atlas.
Data Quality
Ensures data reliability and accuracy through validation and cleaning, providing confidence in data-driven decision-making.
Data Quality Tools: Talend, Monte Carlo, Soda, Anomolo, Great Expectations
Data Modeling
Assists in designing and iterating database schemas easily, supporting agile and responsive data architecture practices.
Modeling Tools
Erwin, SQLDBM
Conclusion: Embracing MDS With Cost Awareness
The Modern Data Stack is pretty amazing; it's like having a Swiss army knife for handling data. It definitely makes things faster and less of a headache. But while it's super powerful and gives us a lot of cool tools, it's also important to keep an eye on the price tag. The pay-as-you-go pricing of the cloud is great because we only pay for what we use. But, just like a phone bill, if we're not careful, those little things can add up. So, while we enjoy the awesome features of the MDS, we should also make sure to stay smart about how we use them. That way, we can keep saving time without any surprises when it comes to costs.
Opinions expressed by DZone contributors are their own.
Comments