ITBench, Part 1: Next-Gen Benchmarking for IT Automation Evaluation
Learn more about ITBench, an open framework to benchmark AI agents for IT automation, focusing on reliability, efficiency, and real-world IT scenarios.
Join the DZone community and get the full member experience.
Join For FreeThe remarkable promise of GenAI-based agentic (AI agents) solutions, coupled with recent improvements in their ability to handle intricate tasks, has increased the potential for AI agents to manage IT systems.
Given the complexity and criticality of IT systems, a key challenge in IT automation is finding reliable ways to evaluate agents before using them in production. The successful adoption of AI agents for IT automation thus depends on the ability to measure and rank their reliability and efficiency in predefined and standard ways.
In this blog, we introduce a novel ecosystem for benchmarking tools, ITBench, to address the more complex challenges of IT automation. The ITBench aims to provide a systematic benchmarking methodology, real-world benchmark scenarios, and targeted open-source tooling to enable the exploration and assessment of AI agents for the automation of IT management.
Our ITBench framework provides baseline AI agents, benchmarking metrics, and results to help agent developers and researchers evaluate their agents across various metrics and supported LLMs. We invite both practitioners and researchers to join us in this effort, which we believe is transformative for IT management.
ITBench Framework
ITBench aims to advance innovation in Agentic AI and establish new standards and practices to benchmark automation in the IT management field. Its main capabilities are following these three axes:
1. Reflecting the Real World
ITBench focuses on IT automation needs that are common and important in real-world production environments. For instance our SRE (System Reliability Engineer) benchmarking scenarios are based on real-world incidents observed in IBM's SaaS products, CISO (Chief Information Security Officer) scenarios are based on CIS (Center for Internet Security) benchmark requirements, while FinOps use cases are identified by the FinOps Foundation reflecting key business requirements.
2. Being Open and Extensible With Comprehensive IT Coverage
We view ITBench as a central hub for benchmarking AI solutions across diverse IT automation use cases. To support this, we provide IT benchmark suites and a framework for vertical (i.e., adding more scenarios) and horizontal expansion (i.e., adding more personas, domains, or use cases), to ensure extensive coverage of IT tasks. ITBench is a newly released open-source framework that enables organizations to develop and benchmark their solutions, whether using open-source or proprietary technologies.
3. Enabling Automated Evaluation With Partial Scoring
ITBench is designed to provide constructive feedback to drive improvements in the design of agentic solutions for IT problems. It includes a comprehensive evaluation framework and leaderboard that provide feedback to users at various stages of their agents’ reasoning process.
ITBench provides push-button deployment and tooling for setting up the environment, runtime agent, guardrail engine, as well as out-of-the-box authorization and authentication, and GitHub-based UX.
ITBench Benchmarking Scenarios, Agents, Automation Server, and Leaderboard
ITBench is a systematic benchmarking framework and run-time environment designed to evaluate agents tasked with automating IT operations. It incorporates a robust and extensible architecture (see Figure 1) comprising agents, scenario specifications, environment setup automation, ITBench servers, and a leaderboard to facilitate a user-friendly and comprehensive assessment of the agent. Here, we present a brief overview of the key components:
- IT Bench Scenario Specification and Environment Setup Automation
- AI Agents
- IT Bench Automation Server and Agent API Server
- Leaderboard and UX
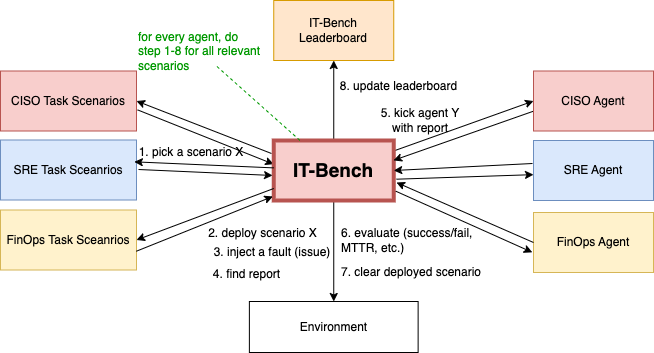
1. Scenario Specification and Environment Setup Automation
ITBench includes domain-specific tasks, known as Scenarios, for agents to solve. For example, one of the scenarios in ITBench is to resolve an SRE “High error rate on service order-management” in a Kubernetes environment. Another example involves assessing the compliance posture for a “new benchmark rule detected for RHEL 9” following upgrades to the RHEL9 benchmarks. A fundamental challenge is to reproduce such scenarios in a manageable testbed environment.
The Environment Setup represents an operational testbed where a scenario is deployed. Components within the environment expose APIs to observe and modify the state of the environment. When an agent is registered for benchmarking, ITBench selects a set of scenarios within the agent's domain (eg, CISO, FinOps, SRE) and level of expertise (Beginner, Intermediate, or Expert). Then, ITBench iterates through the set of selected scenarios and for each scenario, it automatically instantiates the testbed. An example of an environment includes a Kubernetes cluster installed with the OpenTelemetry Astronomy Shop Demo application, an observability stack including Loki, Jaeger, and Prometheus, along with mechanisms that induce problem(s) in the environment.
Problems are introduced into the environment to trigger incidents or noncompliance, appearing as scenario-specific issues. Environment tools are configured to observe the environment state and raise triggering events on problematic conditions. An example of a triggering event is "High Error Rate on adservice", which may be triggered in the environment due to a cache failure.
Currently, ITBench is pre-populated with an initial set of 94 scenarios across our three key IT Operations areas: Compliance and Security Operations (CISO), Financial Operations (FinOps), and Site Reliability Engineering (SRE), which are the target of our initial ITBench release.
2. AI Agents
The initial release of the ITBench is also pre-populated with three AI agents targeting the above-mentioned three IT Operations areas. In IT automation, the different personas are focused on a specific desired outcome, which defines their automation goals. For SREs, incident resolution is the primary objective. Achieving this can involve multiple steps, such as diagnosing an incident, or a single step, like generating a diagnosis report. CISO persona focuses on the regulatory controls posture assessment process, including collecting evidence and scanning assessment posture tasks. FinOps persona focuses on cost management while meeting business objectives, where sample tasks include identifying and mitigating inefficiencies. During the agent evaluation on ITBench, each step is assessed independently and is measured using pre-defined metrics, such as accuracy and mean time to repair or assess.
We open-sourced two baseline agents (SRE and CISO) along with ITBench. Our baseline agents, SRE agent for SRE, Compliance Assessment Agent for CISO, and FinOps Agent for FinOps, use state-of-the-art agent-based techniques such as ReAct-based planning, reflection, and disaggregation. We also use the open-source CrewAI and LangGraph to create and manage the agents. The agents can be configured to use various LLMs available through WatsonX, Llama, or vLLM.
3. IT Bench Automation Server and Agent API Server
Our ITBench framework supports two main phases corresponding to two personas: (a) the Benchmark Registration phase, where the target is the Benchmark Submitter persona (Note: this is internal capability only at the time of this post), and (b) the Agent Registration phase, which focuses on the Agent Submitter persona and the actual runtime benchmarking execution and evaluation.
a. Benchmark Registration
The benchmark registration phase comprises two main steps: (I) scenario development and registration, and (II) tasks and evaluation metrics registration, as follows:
I. Scenario Development and Registration
Our scenarios are developed based on our experience with the real-world issues observed in production environments and thus are designed to instantiate real-world IT problems in realistic and manageable environments. Each scenario comprises two core components: (i) scenario specification metadata, and (ii) environment setup pipeline.
II. Tasks and Evaluation Metrics Registration
For each scenario type, the Benchmark Submitter pre-registered a well-defined set of tasks that form the basis for the Agent's performance evaluation. In upcoming releases, this capability will be opened to the community.
b. Agent Registration
During this phase, the Agent Submitter first registers as a user on the platform, then follows with the actual Agent Registration. Once an agent has been registered, the Agent Submitter selects their agent, and the corresponding benchmarks are retrieved from the database using the agent domain type, agent expertise level, and scenario class specified during the registration for the agent (see UI illustrated in Figure 2).
The Agent Submitter receives the required input and output for the tasks the agent must execute to achieve the objective, along with pre-defined evaluation metrics that the agent must support for proper assessment.
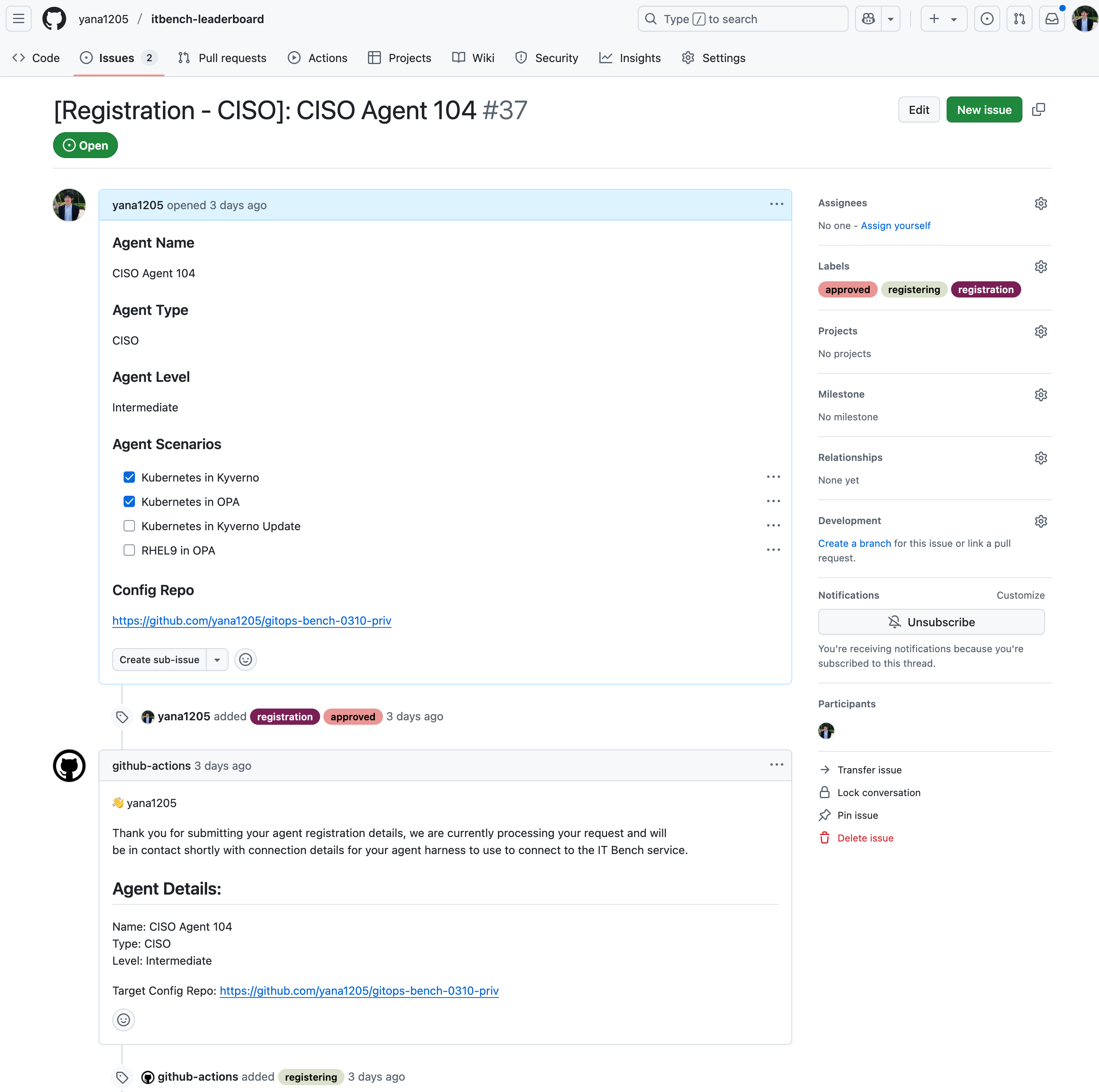
ITBench framework supports both API Server and UI Leaderboard interfaces, enabling a streamlined benchmarking workflow. Users can register the agent endpoint via the Leaderboard’s UI or API. The agent can then query the Leaderboard to retrieve and deploy benchmark scenarios before reporting their operational status.
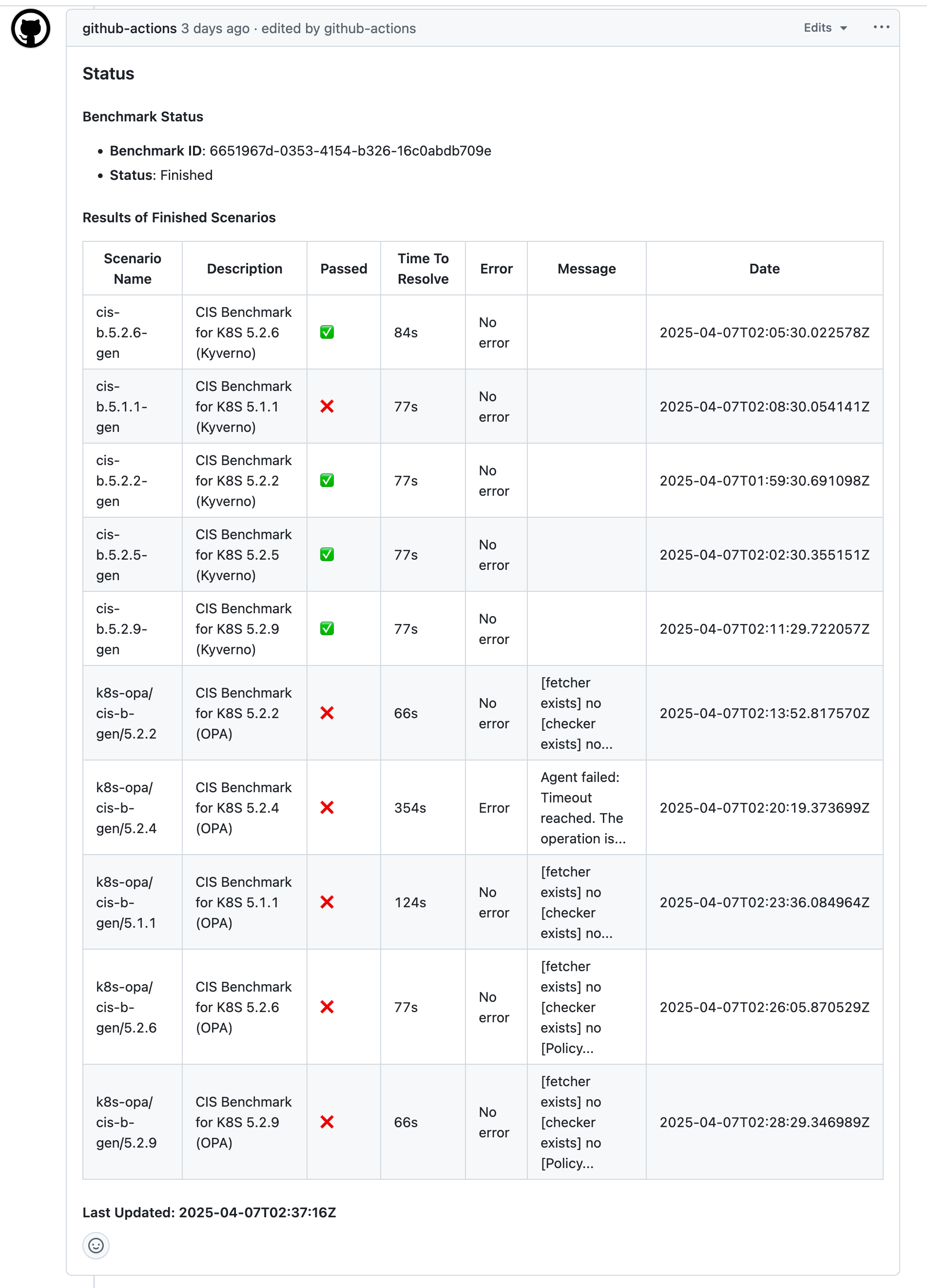
The scenarios can be deployed either automatically by the ITBench Automation Server, in its hosted environment, or manually outside the ITBench, in the user’s hosted environment, in which case both agent and environment can still leverage the same Agent API Server endpoint to publish status updates (see UI illustrated in Figure 3).
Figure 1 shows the agent benchmarking process workflow after registration by the Agent Submitter and is summarized below.
1. ITBench fetches a benchmark scenario for a particular agent from the Benchmark Queue.
2. ITBench provisions the environment as per the benchmark scenario specification. The scenario’s environment is the set of systems required for the execution of a specific IT task. The agent interacts with (and can potentially modify) the environment to solve the given IT automation tasks. A benchmark evaluation measures the agent’s performance based on whether it successfully completes the tasks in the given environment. The environment could be, for instance, a Kubernetes cluster running a target application or an RHEL 9 host with a specific configuration to be validated. The environment is under the direct control of the Agent and therefore may be subject to destructive actions (in case of faulty performance), thus functioning as a sort of “playground.”
3. For each scenario included in the benchmark run, ITBench monitors the environment’s status via the Agent Server’s API. Once the status becomes Deployed, it injects a fault into the environment by executing the inject_fault function.
4-6. ITBench continues to monitor the environment’s status. Once the status reaches FaultInjected, it updates the manifest’s status in the Benchmark DB, including key details such as Benchmark ID, Scenario ID, cluster credentials, and URLs in the manifest. This allows the agent to access and retrieve this manifest for working with the environment. After the agent completes the scenario execution, it posts the Agent completion report.
7. ITBench starts the evaluation and executes the delete_scenario function.
8. Once the evaluation results for all the scenarios in the benchmark are ready, ITBench aggregates them and publishes the results to the Leaderboard.
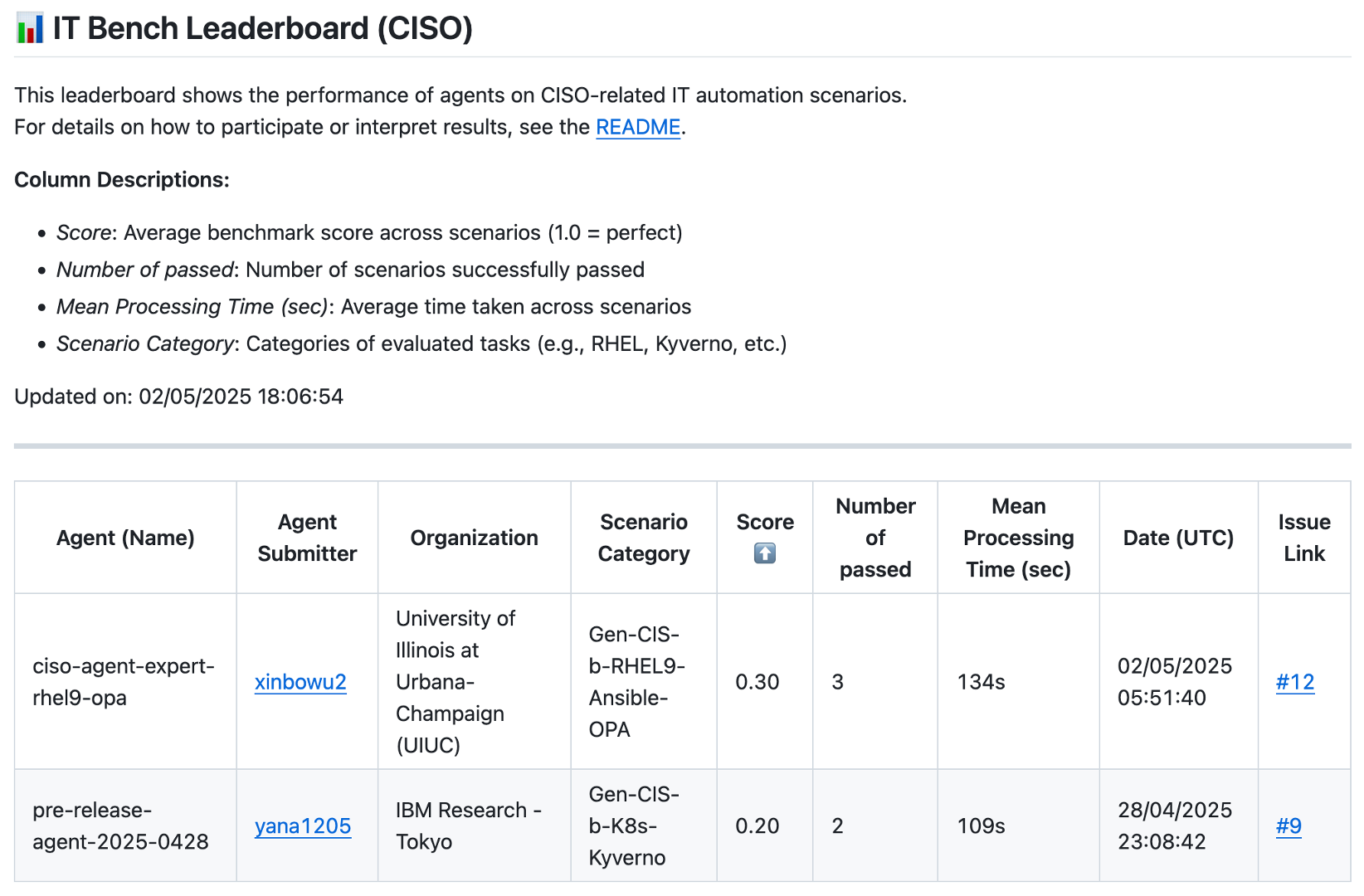
4. Leaderboard
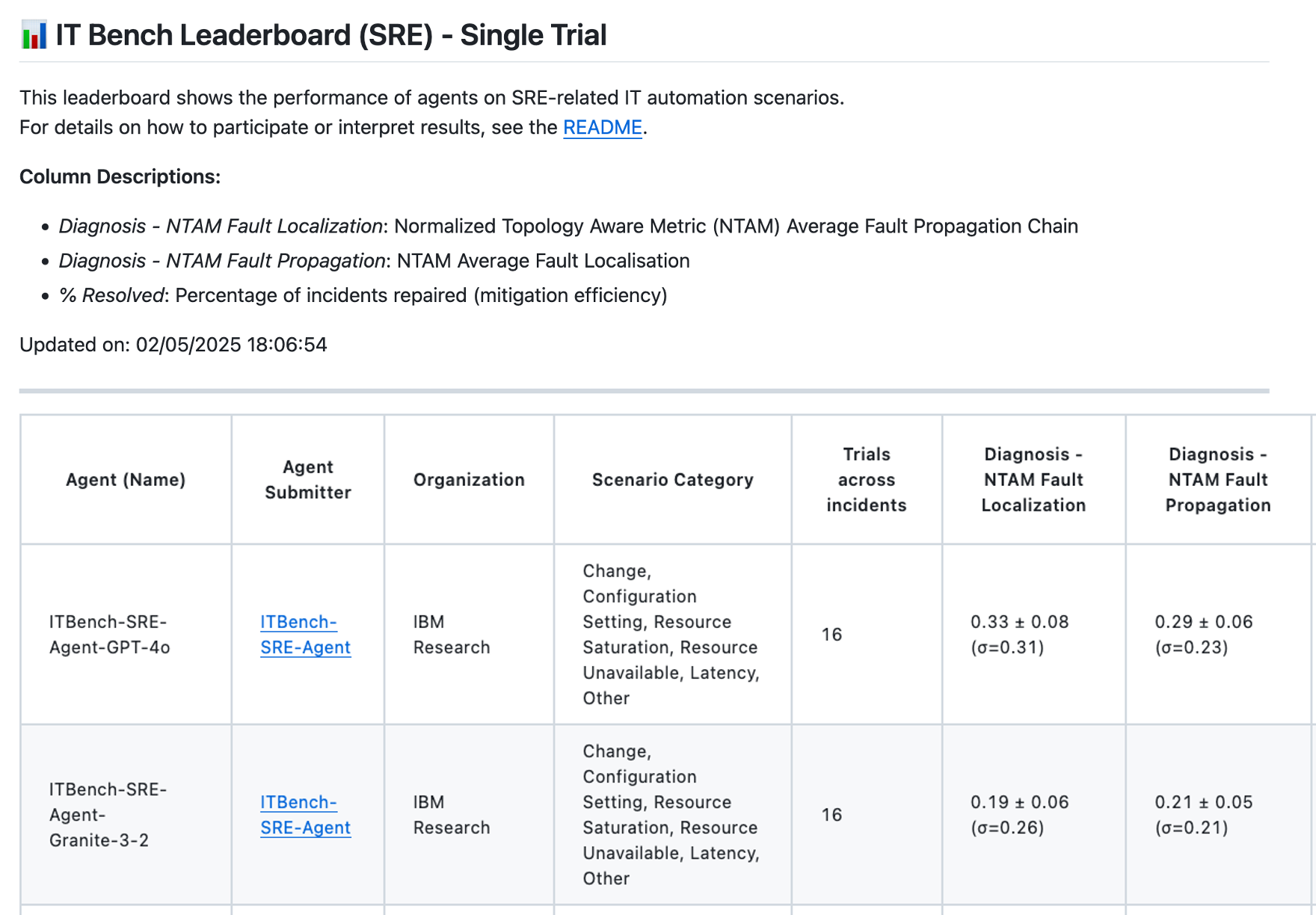
ITBench includes a Leaderboard (see Figure 4) to promote reproducibility and comparative analysis. The Leaderboard offers a pre-defined, extensible (in future releases) set of performance metrics designed to provide clear insights into agent performance relative to the evaluation criteria. ITBench devises scoring methods for partially correct solutions to provide meaningful feedback for summative assessments. This comprehensive approach establishes a new standard for evaluating and advancing AI-driven solutions in IT automation.
For each scenario that an agent works on, upon task completion, the ITBench records the final system state, which is then used at the end of all scenario runs, along with the pre-defined ground truth data, to validate how well the agent performed across all the scenarios. We open-sourced a small subset (11 out of 94) of scenarios ITBench along with the baseline agents to help the community familiarize itself with ITBench through practical examples. We reserved the remaining scenarios in ITBench to benchmark and evaluate the submitted agentic solutions.
Conclusion
In this introductory blog post of this multi-blog series, we introduced ITBench, a novel framework for benchmarking tools for evaluating AI agents targeting the complex challenges of IT automation. One of the key design principles of IT-Bench is ensuring its flexibility to support diverse areas of different IT systems and its extensibility to new scenarios and evaluation metrics.
We are expanding scenario coverage in key IT operations areas — Compliance and Security (CISO), Financial Operations (FinOps), and Site Reliability Engineering (SRE) — and driving growth through open community contributions. We look forward to community contributions and feedback!
What’s Coming Next?
In addition to the high-level architecture and workflows we described for the IT Bench in this blog, we plan to present the user experience in a follow-up post with step-by-step detail and interactions with the ITBench core utilities and APIs.
Stay tuned for upcoming posts, in which we will dive into the evolution of our open-source CISO, FinOps, and SRE agents, featuring new scenarios, tasks, and evaluation metrics.
Learn More
Check out our open-source Git repo documentation for a detailed introduction to the CISO, SRE, and FinOps Agents, along with their benchmark scenarios and execution:
Our agents include sample scenarios and executable automation packages, available in open-source:
For those looking to dive deeper into ITBench, we recommend our detailed arXiv article "ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks," in which we present the evaluation results of our baseline agents across all available scenarios, metrics, and multiple LLMs.
Opinions expressed by DZone contributors are their own.
Comments