Jakarta Query: Unifying Queries in a Polyglot Persistence World, the News on Jakarta EE 12 M2
Jakarta Query unifies queries across Jakarta Persistence, Data, and NoSQL, with common and relational levels to simplify polyglot persistence in EE 12 M2.
Join the DZone community and get the full member experience.
Join For FreeAs software architectures grow more complex, persistence ceases to be a purely technical concern and becomes an architectural one. Modern systems rarely rely on a single database or a single data model. Instead, they adopt polyglot persistence, choosing different storage technologies depending on scalability needs, access patterns, and domain boundaries. Relational databases remain essential, but they increasingly coexist with document stores, key-value databases, and other non-relational systems.
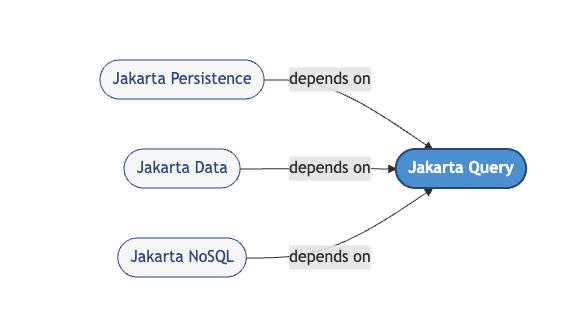
This reality has already reshaped the Jakarta ecosystem. Specifications like Jakarta NoSQL and Jakarta Data emerged to acknowledge that persistence is no longer synonymous with ORM. With Jakarta EE 12, another important piece joins the picture: Jakarta Query, a new specification designed to unify how Java developers query data across persistence technologies.
Jakarta Query
With the Jakarta EE 12 M2 release on January 27, Jakarta Query has reached a point where its intent and direction are clear enough to discuss not just what it is, but why it exists and how it fits into the platform’s evolution.
At its core, Jakarta Query addresses a long-standing tension in enterprise Java. Even when different persistence APIs coexist, developers are still forced to learn and maintain multiple query languages. SQL for relational databases, JPQL for JPA, method-based queries for repositories, and vendor-specific query dialects for NoSQL systems all solve similar problems in slightly different ways. Over time, these languages evolve independently, fragmenting both developer experience and platform consistency.
Rather than introducing yet another isolated language, Jakarta Query defines a common object-oriented query model that can be shared across Jakarta Persistence, Jakarta Data, and Jakarta NoSQL. The goal is not to hide differences between databases, but to provide a stable, consistent foundation so developers can reason about queries in a single conceptual space rather than many.
This unification matters because, regardless of the database, Java applications face the same fundamental challenge: mapping object graphs to data representations. In object-oriented languages, data naturally forms graphs of interconnected objects, navigated through references and shaped by inheritance and polymorphism. Relational databases, on the other hand, represent relationships using foreign keys and tables, with no native concept of navigation or polymorphic associations. SQL works extremely well for relational algebra, but it does not express object navigation as a first-class construct.
An object-oriented query language bridges this gap. Conceptually, it is a dialect of SQL enriched with navigation, associations, and subtype polymorphism — features that reflect how applications are actually modeled in Java. Jakarta Query formalizes this idea at the platform level.
Levels of Query Language
To support the diversity of datastores in the Jakarta ecosystem, the specification deliberately defines two query language levels, rather than a single monolithic one. The first is a common subset designed to work across Jakarta Data and Jakarta NoSQL providers, including those backed by non-relational databases. The second builds on top of this subset, adding relational-specific capabilities for Jakarta Persistence and other SQL-based technologies.
The Jakarta Common Query Language (JCQL) focuses on operations that are broadly applicable across data stores: selection, restriction, ordering, and simple projection. Its purpose is portability. A query written at this level should be implementable even when the underlying datastore does not support joins or complex relational operations.
Consider a simple document representing a room:
{
"id": "R-101",
"type": "DELUXE",
"status": "AVAILABLE",
"number": 42
}Using the common language, a query that retrieves all available deluxe rooms ordered by number looks like this:
from Room where type = 'DELUXE' and status = 'AVAILABLE' order by numberThere are no joins, no grouping, and no assumptions about relational structure — only object attributes and simple predicates. This is intentional. The common language reflects the lowest common denominator that still feels natural to Java developers.
Building on that foundation, the Jakarta Persistence Query Language (JPQL) defined by Jakarta Query is a strict superset of the common language. It introduces relational-oriented constructs such as joins, grouping, aggregate functions, and bulk operations. These features are essential for SQL-backed systems and remain fully aligned with existing JPA semantics.
For example, imagine a hotel document that embeds a collection of rooms:
{
"id": "H-200",
"name": "Grand Hotel",
"rooms": [
{ "id": "R-101", "status": "OCCUPIED" },
{ "id": "R-102", "status": "OCCUPIED" },
{ "id": "R-103", "status": "AVAILABLE" }
]
}Using the persistence language, a query can express richer analytics:
select h.name, count(r) from Hotel h join h.rooms r where r.status = 'OCCUPIED' group by h.name having count(r) > 10 order by count(r) descThis query relies on joins, grouping, and aggregate functions — features that make sense in relational contexts and are therefore intentionally excluded from the common subset.
The specification clearly documents which features belong to each level. Clauses like FROM, WHERE, ORDER BY, basic SELECT, UPDATE, and DELETE are available in both. More advanced constructs — joins, grouping, HAVING, distinct selections, constructor expressions, subqueries, and set operations — are reserved for the persistence level. The same separation applies to functions and expressions, including datetime, boolean, numeric, and string operations.
This two-level design is one of Jakarta Query’s most important architectural decisions. It avoids forcing non-relational databases to emulate relational semantics they do not naturally support, while still allowing full expressive power where it makes sense. At the same time, it preserves backward compatibility with existing JPQL and aligns closely with the query model introduced in Jakarta Data 1.0.
From a developer’s perspective, the value is consistency. A query written for Jakarta Data using the common language does not suddenly become alien when moving to Jakarta Persistence. Instead, it fits into a larger, coherent query ecosystem. This reduces cognitive load, improves portability, and strengthens the overall developer experience across the platform.
Seen in this light, Jakarta Query is not just another specification. It is a connective layer. It aligns how queries are expressed across persistence technologies, reinforces the idea that persistence APIs operate at different abstraction levels, and acknowledges that modern Java applications live in a world where multiple databases are the norm rather than the exception.
With Jakarta EE 12, the platform moves one step closer to treating persistence as an integrated, coherent experience rather than a collection of loosely related APIs. Jakarta Query plays a central role in that shift, ensuring that regardless of where data lives, Java developers can reason about queries in a unified, object-oriented way.
Opinions expressed by DZone contributors are their own.
Comments