Jakarta Query: Unifying Queries Across SQL and NoSQL in Jakarta EE 12
Jakarta EE 12 introduces Jakarta Query, a brand-new specification aiming to unify query languages across relational and non-relational databases.
Join the DZone community and get the full member experience.
Join For FreeWhen we talk about the history of knowledge and information, it's natural to write and endure. The information is one step; the next step is how to retrieve and search the information storage. This also occurs with the most modern software applications, where we need to handle various databases and different methods for retrieving information.
Furthermore, we need to learn how to retrieve information through queries. The good news for Java developers is that our lives can be easier: Imagine writing a single query once and running it seamlessly across different databases, whether SQL or NoSQL. No more translating between dialects, no more adjusting your persistence logic to fit the quirks of one provider or another. The primary goal of the newest specification, Jakarta Query, is to take shape as part of Jakarta EE 12. If successful, it has the potential to dramatically simplify how enterprise Java developers interact with data, making the persistence layer far more consistent, portable, and developer-friendly.
But it is essential to set expectations early. Jakarta Query is still in its infancy — a draft proposal rather than a finalized standard. Many details remain to be defined, and the final shape of the specification could differ significantly from the current early discussions. In this article, I will outline the history, goals, and objectives of this discussion, as well as what I, as a Java developer, expect from this specification.
The Proposal
This new specification defines an object-oriented query language designed for use with Jakarta Persistence, Jakarta Data, and Jakarta NoSQL. Its central goal is to unify the query capabilities of these technologies under one umbrella, making it possible to express queries in a consistent and portable way across both relational and non-relational databases.
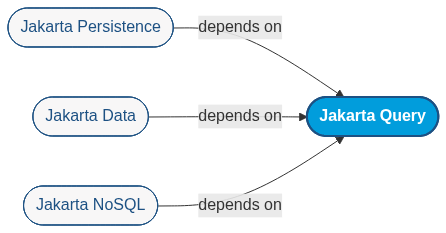
The proposal introduces a dual structure:
- Core language: implemented by Jakarta Data and Jakarta NoSQL providers targeting non-relational datastores.
- Extended language: tailored for relational persistence providers such as Jakarta Persistence.
Jakarta Query is a new spec, but it does not start from scratch; as expected, it will work and consider compatibility. One of its primary objectives is to ensure backward compatibility with previous query languages. For relational databases, it aligns with the Java Persistence Query Language (JPQL), ensuring that applications using Jakarta Persistence continue to function without disruption. For Jakarta Data users, compatibility with the Jakarta Data Query Language (JDQL) remains, with the long-term goal of deprecating JDQL and making Jakarta Data rely directly on Jakarta Query as its query model.
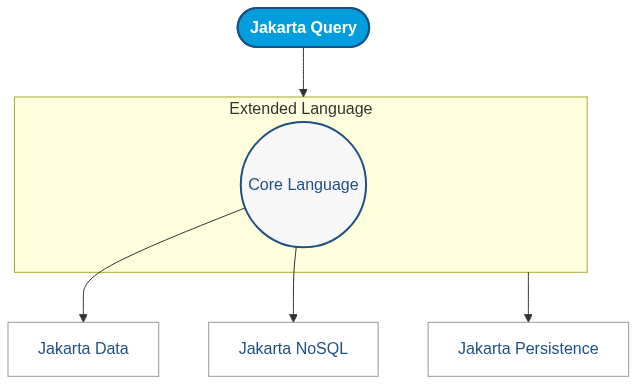
At the same time, Jakarta NoSQL has set the goal of supporting Jakarta Query starting with Jakarta EE 12, which will bring a consistent query experience to non-relational databases as well. The goal here is to preserve the existing ecosystem while gradually converging toward a single, unified query language that can serve relational, non-relational, and higher-level data abstractions under the Jakarta EE umbrella.
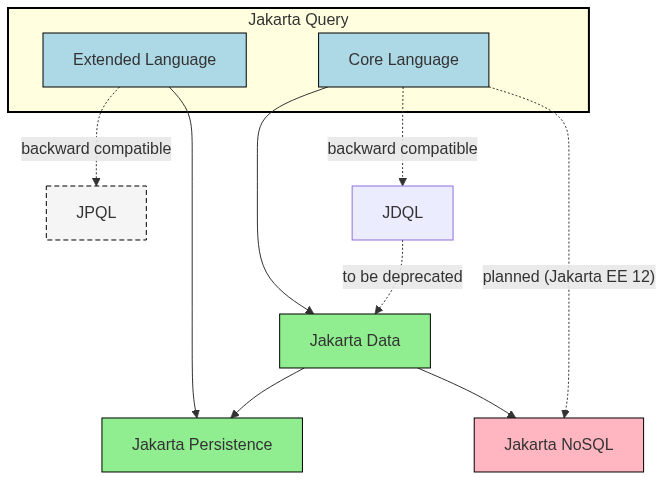
This layered approach ensures backward compatibility with existing standards while opening the door to a unified future in which a single query language can serve diverse storage paradigms.
An object-oriented query language fills an essential gap between how developers model data and how databases store it. In object-oriented programming, data is often seen as a graph of interconnected objects, with inheritance and polymorphism as natural constructs. Relational databases, however, rely on foreign keys, with SQL offering no native constructs for associations or polymorphism. Jakarta Query extends SQL-like syntax to treat associations, inheritance, and subtype polymorphism as first-class elements, aligning queries more closely with domain models.
A Brief Historical Background
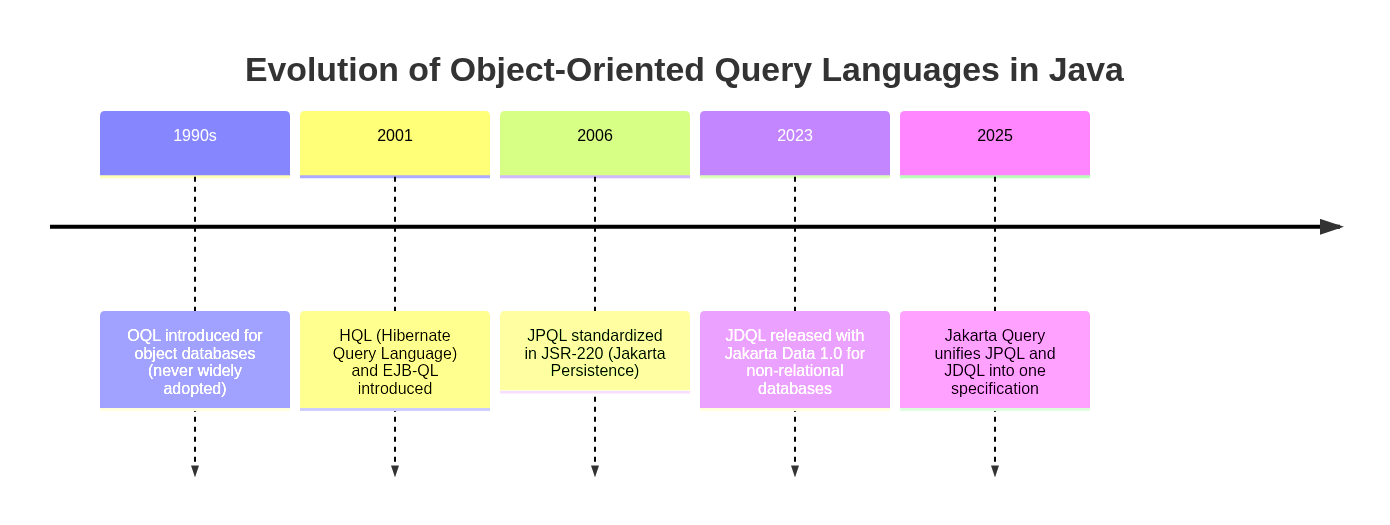
The idea of object-oriented query languages is not new. In the early 1990s, the Object Query Language (OQL) was designed for object databases, though it never gained traction due to the limited adoption of such systems. A decade later, the Java ecosystem saw the rise of Hibernate Query Language (HQL) and Enterprise JavaBeans Query Language (EJB-QL), both of which were aimed at object-relational mapping. HQL became widely adopted and strongly influenced the creation of the Java Persistence Query Language (JPQL), which was standardized in 2006 through JSR-220. JPQL remains in widespread use today as part of Jakarta Persistence.
More recently, Jakarta Data introduced the Jakarta Data Query Language (JDQL), a strict subset of JPQL intended for non-relational databases. While both JPQL and JDQL share similar roots, they have evolved separately, managed by different groups, resulting in unnecessary fragmentation. Jakarta Query steps in to unify their evolution, ensuring a consistent query model for both relational and non-relational data access under the Jakarta EE umbrella.
The following section will dive into the challenges, showing why the path toward Jakarta Query is as ambitious as it is necessary.
Challenges: Bridging Paradigms With a Single Query Language
Before celebrating portability, we have to stare down the impedance mismatch — a term borrowed from electrical engineering that describes what happens when two systems with different “interfaces” meet, and energy (or in our case, semantic intent) is lost. In software, this mismatch lies between Java’s object model (objects, identity, associations, inheritance, and polymorphism) and databases’ storage/query models (sets, relations, algebra, indexes, distribution, and consistency strategies. Jakarta Query’s promise — a single, object-oriented query language that works across Jakarta Persistence, Jakarta Data, and Jakarta NoSQL — must reconcile those differences without compromising either side.
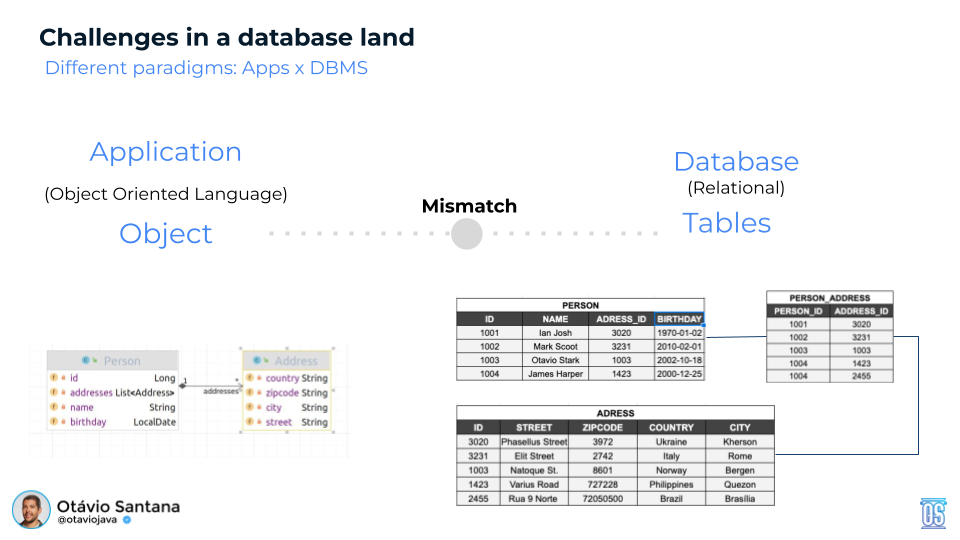
Relational databases represent relationships explicitly (foreign keys, joins) and rely on relational algebra. They do not natively model object navigation or subtype polymorphism; those are projected into SQL via joins and discriminator schemes. Many NoSQL stores, meanwhile, model relationships by embedding (documents), user-defined types (UDTs) (wide-column/column-family), or edges (graphs). Each approach optimizes for different trade-offs (locality vs. normalization, write amplification vs. query fan-out, transactional scope, indexing).
To illustrate, consider a simple Java model:
public class Person {
private Long id;
private String name;
private List<Address> addresses;
}
public class Address {
private Long id;
private String city;
private String street;
}A natural query in such a model might be:
select address.city from PersonThis query is not formally defined yet in Jakarta Query. Still, the goal is clear: it should be compatible with existing approaches — mapping smoothly to JPQL in Jakarta Persistence and to JDQL in Jakarta Data — while becoming the unified query model that replaces these parallel paths in the future.
When Jakarta Query targets NoSQL, the flow goes through the core language. Queries can be executed directly against Jakarta NoSQL or indirectly via Jakarta Data, which delegates to a Jakarta NoSQL provider. The exact translation into a native query depends on the chosen NoSQL driver, since each datastore (document, graph, wide-column, key-value) exposes different query capabilities.
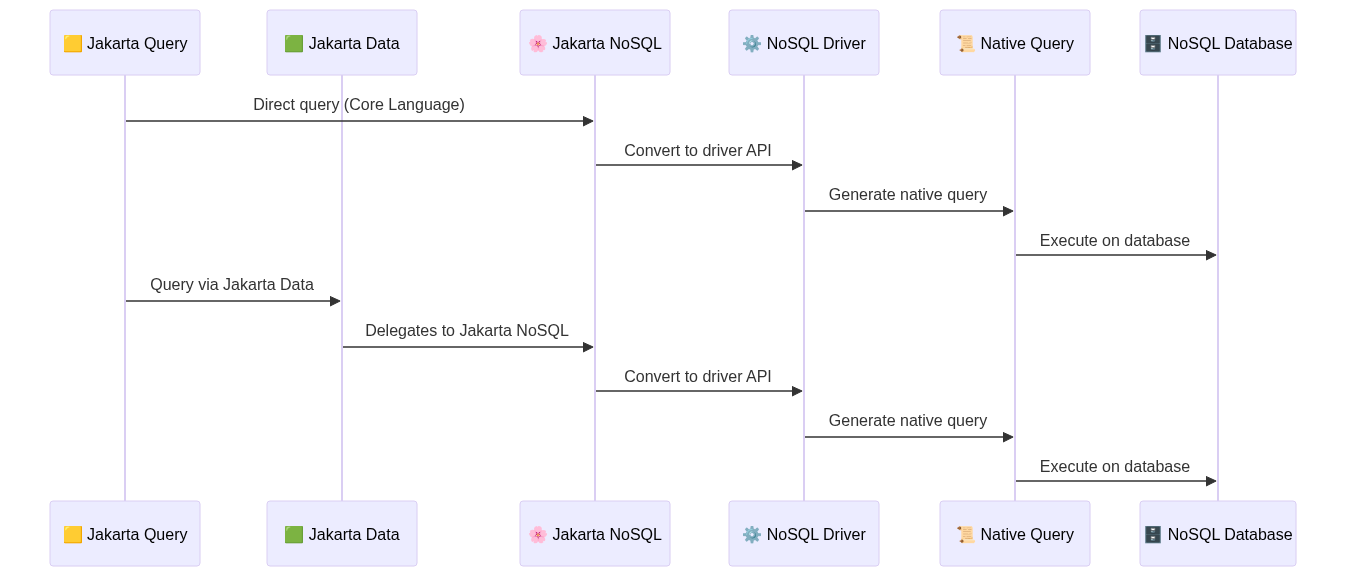
On a Document database, such as MongoDB and Oracle NoSQL: the Association is internalized via embedding; the query select address.city from Person becomes an array projection (addresses[*].city).
JSON representation:
{
"id": 42,
"name": "Ada Lovelace",
"addresses": [
{ "id": 1001, "city": "London", "street": "Baker St" },
{ "id": 1002, "city": "Paris", "street": "Rue de Rivoli" }
]
}Wide-Column and Graph Perspectives
- Wide-column (e.g., Cassandra) would likely store addresses as a collection of UDTs, queried with collection operators.
- Graph databases would represent Person and Address as vertices with an edge (HAS_ADDRESS), and the query becomes:
- Traversal with Apache Tinkerpop:
g.V().hasLabel('Person').out('HAS_ADDRESS').values('city'). - Neo4J:
MATCH (p:Person)-[:HAS_ADDRESS]->(a:Address) RETURN a.city - Thus, eventually, the Jakarta Query should allow particular query behavior, such as allowing us to define the edge in a Graph database query. It is not about creating this standard, but allowing particular behavior on databases that goes beyond joins. For example: allows to define the edge name to this relationship once, this "
HAS_ADDRESS" could be "LIVES" instead.
- Traversal with Apache Tinkerpop:
When Jakarta Query targets relational databases, the extended language comes into play. Queries may be directed to Jakarta Persistence or passed through Jakarta Data, which then delegates to a persistence provider. In this case, the mapping is more predictable, as queries align closely with JPQL semantics and are ultimately translated into SQL against the relational schema.
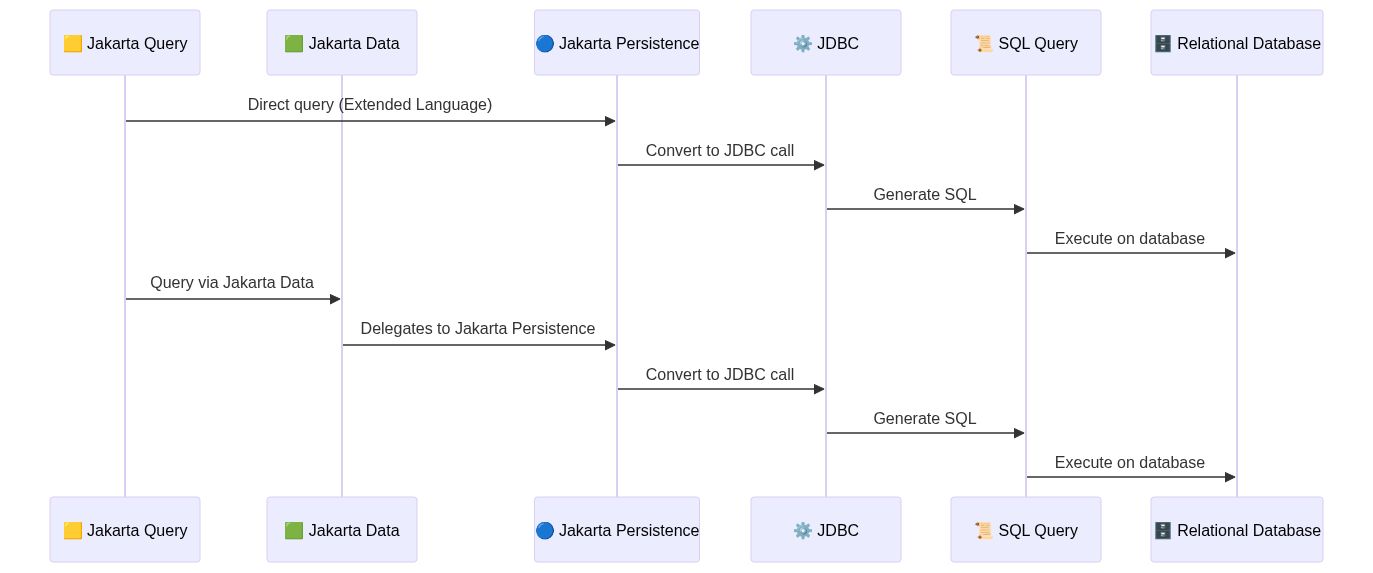
- Association is externalized via ADDRESS.person_id and reassembled with a JOIN.
- The query
select address.city from Personbecomes a SQL join across the 'Person' and 'Address' tables.
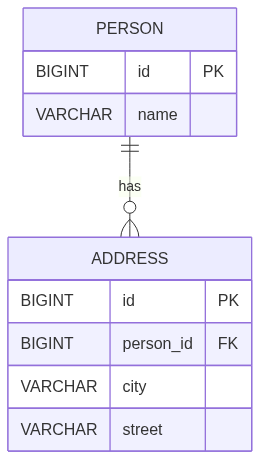
When we discuss Jakarta Query and its goal of handling various databases that connect to Java, this is even more unique, as it involves different database paradigms. We must consider that the specification should support the minimum behavior at the same time, allowing particular behaviors, and it is just the start. On Jakarta Query, we have several challenges:
- Association semantics across storage models: The same query —
select address.city from Person— means a join in SQL, an array projection in documents, a collection predicate in wide-column, or a traversal in graphs. Jakarta Query must make these semantics portable without forcing the lowest common denominator. - Polymorphism and inheritance: Java supports subtype polymorphism, but SQL does not; document and graph stores handle it differently. The query language must define predictable semantics for polymorphic queries and degrade gracefully when unsupported.
- Capability discovery and graceful fallback: Different backends support different operations. Jakarta Query must define how clients can discover capabilities, and how unsupported features are reported — through clear diagnostics rather than silent errors.
- Performance portability: A portable query may run fast on one backend and poorly on another. The specification must encourage query shapes that remain predictable while leaving space for backend-specific optimizations.
- Backward compatibility without stagnation: Jakarta Query is new, but it must honor existing investments and remain compatible with JPQL and JDQL. At the same time, the roadmap is clear: JDQL will be deprecated, and Jakarta Data will eventually use Jakarta Query directly.
Conclusion
What I have shared here is not an official roadmap but rather my perspective as a Java developer watching Jakarta Query take shape. These are speculations and expectations about how the specification might evolve and why they matter. For me, Jakarta Query has the potential to be the most breaking change in Jakarta EE 12, just as Jakarta Data was the defining innovation of Jakarta EE 11. A single, unified query language that bridges relational and non-relational databases is no small step — it could reshape the way enterprise developers think about persistence.
I am particularly excited because this work is being led by some of the brightest minds in the Java ecosystem. Gavin King, the creator of Hibernate and a key figure behind Jakarta Persistence and Jakarta Data, is deeply involved, ensuring both vision and continuity. That gives me confidence that Jakarta Query is in excellent hands.
To follow the progress, you can find more details on the official specification page: Jakarta Query 1.0. Even better, since it is fully open source, you can get involved, contribute, and join the conversation at the project’s GitHub repository: jakartaee/query.
Opinions expressed by DZone contributors are their own.
Comments