Why SQL Isn’t the Right Fit for Graph Databases
Graph database vs. relational database GQL vs. SQL graph data modelling database schema design SQL performance issue QQL intuitiveness.
Join the DZone community and get the full member experience.
Join For Free By Wanyi Sun
By Wanyi Sun
Background
"Why don't your graph products support SQL or SQL-like query languages?"
This question used to be frequently asked by some of our clients in the past but has become increasingly rare over time.
Although once overlooked, the necessity for a graph database to possess a query language seamlessly designed and adapted to its underlying data structure has been conclusively demonstrated by innovative products and embraced by the market. Graph databases exhibit notable differences from relational databases in terms of data model, data storage, performance, and more, tailoring to diverse application scenarios and business objectives. These distinctions affirm that SQL is ill-suited to serve as a query language for a native graph computing engine.
For a more comprehensive comparison, we will demonstrate SQL queries against a tabular dataset stored in SQL Server, as well as their equivalent queries composed in UQL to run against a graph dataset with the same content loaded into Ultipa. Both datasets were analyzed in another article, A Step-by-Step Guide: How to Convert Tables to Graphs.
Datasets
In case you haven't had a chance to review it yet, the tabular dataset we'll be using comprises data from six tables within a Hospital Information Management System: DOCTOR, PATIENT, DEPARTMENT, BED, DIAGNOSIS, and INPATIENT. This dataset is relatively small, consisting of about 60 lines of records. The data fields for each table are outlined below, with a focus on their interconnections (arrows pointing from foreign keys to primary keys):
The hierarchical data management structure in an SQL Server connection is denoted as 'database-table-field,' which can be translated to 'graph-schema-property' in an Ultipa graph system. In other words, a schema in the Ultipa graph system corresponds to a table in relational databases, and schema properties are analogous to table fields.
The graph dataset is derived from the aforementioned tabular dataset by transforming table structures into node schemas (with properties like _id, etc.) and edge schemas (with properties like _from, _to, etc.). This process involves tasks equivalent to modifications, as outlined below, to the original tables:
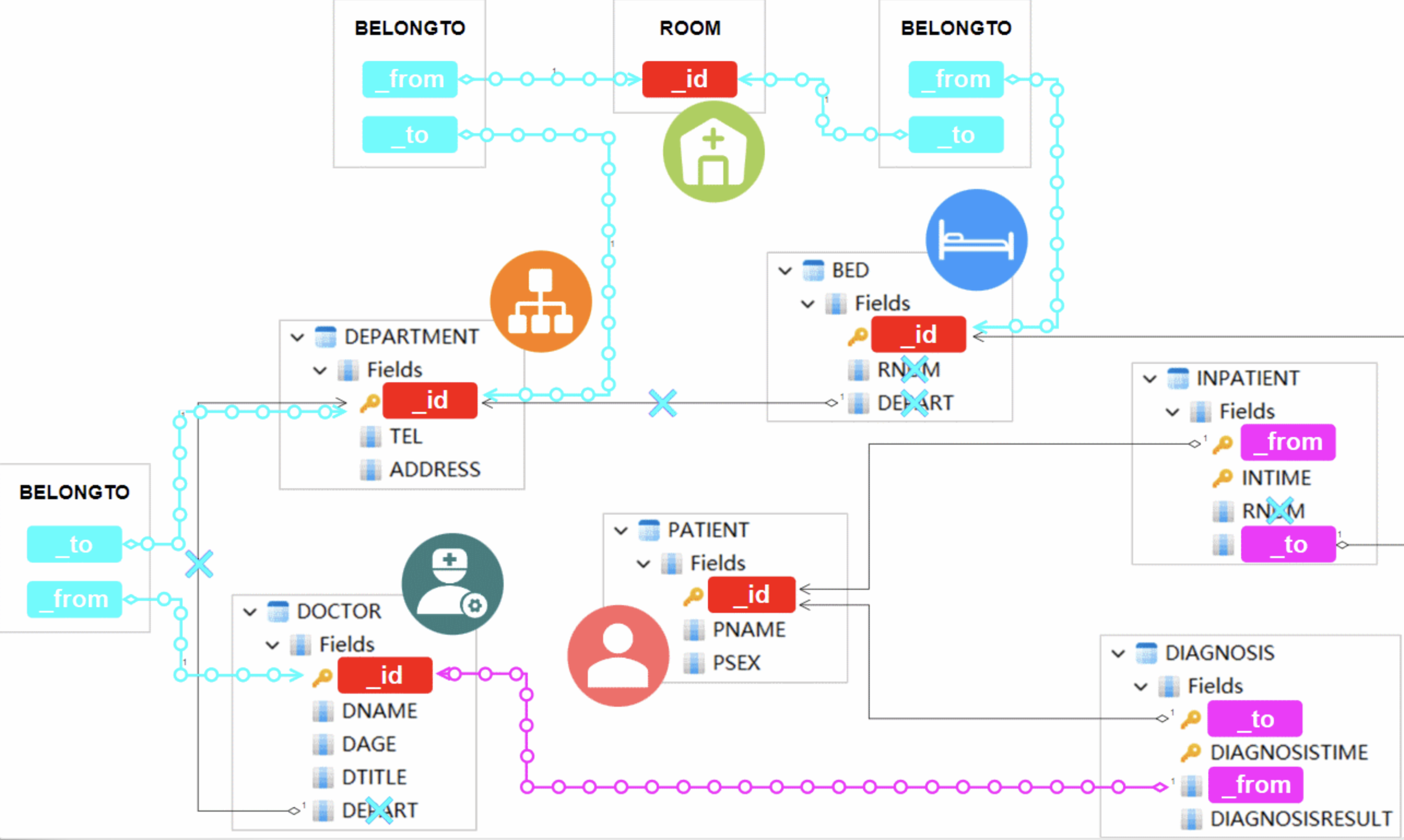 A comprehensive depiction of the graph model, illustrated through modifications to the original table structures
A comprehensive depiction of the graph model, illustrated through modifications to the original table structures
The resulting graph dataset encompasses five node schemas: DOCTOR, PATIENT, DEPARTMENT, BED, and ROOM, along with three edge schemas: DIAGNOSIS, INPATIENT, and BELONGTO. Node IDs are extracted from the table's primary key, while the FROM and TO for edges are derived from the table's foreign keys, supplemented where necessary.
Table Query vs. Schema Query
Given that the concept of a table in SQL Server corresponds to that of a schema in Ultipa, let's begin by comparing the querying process for, say, the DOCTOR table and the DOCTOR node schema.
Query objective: Retrieve all the information for every doctor.
SQL:
SELECT * FROM guest.DOCTOResult of single-table query using SQLUQL:
n({@DOCTOR} as N) RETURN N{*}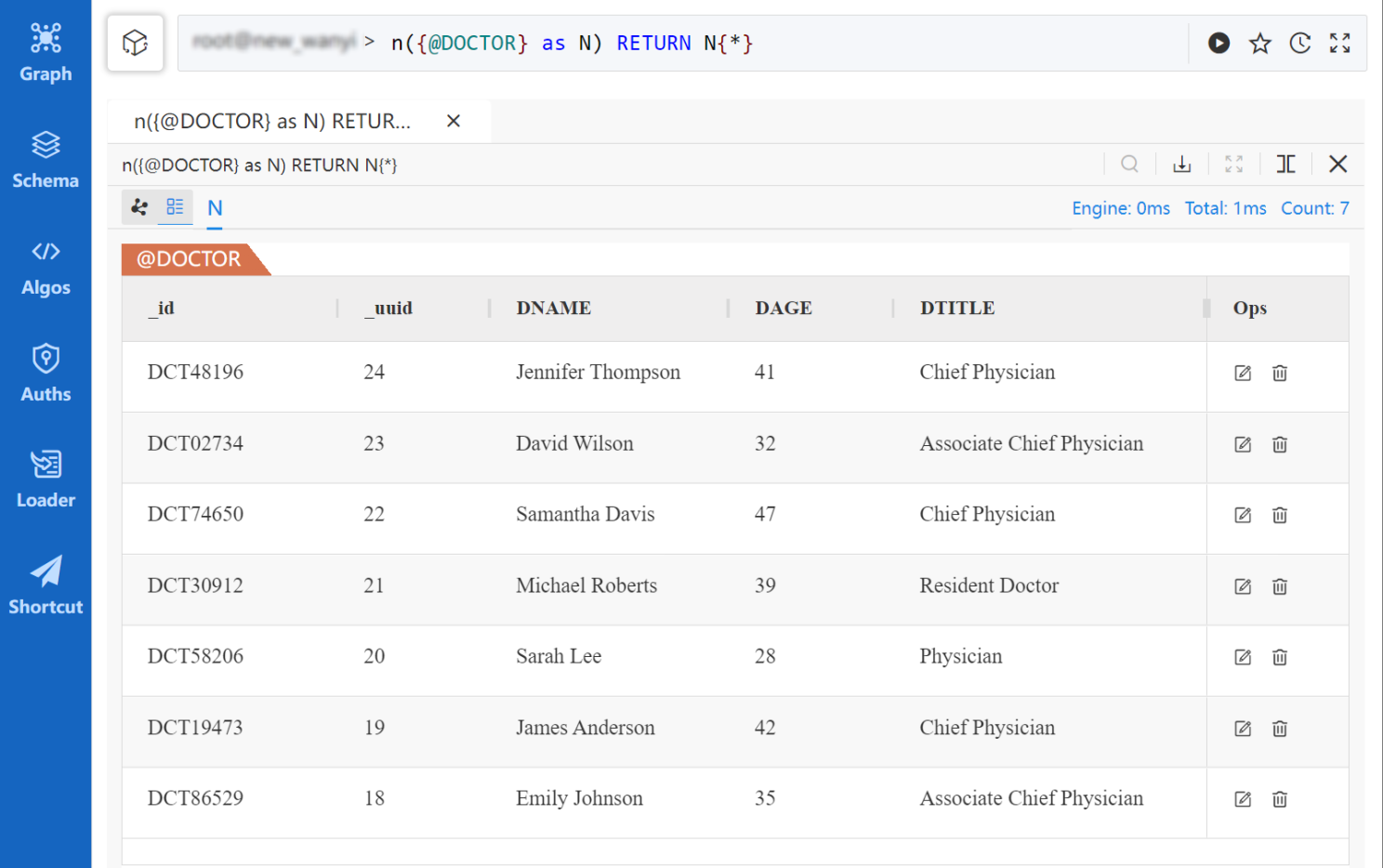 Result of single-schema query using UQL
Result of single-schema query using UQL
Although both queries are equally clear and produce identical results, SQL resembles an English sentence requesting to "select all data fields from the DOCTOR table," while UQL, intentionally deviating from this type of natural language-based syntax, utilizes symbols to convey its execution logic, which is 'n()' that signifies a node in the graph.
This approach aligns with the nature of a graph, where nodes and edges are fundamental components, unlike relational databases where tables exist as the core data model. In the next round, we will encounter 'e()' in UQL denoting an edge.
Join Query vs. Path Query
Graph data earns its acclaim by faithfully replicating the complexities of the real world. This is exemplified by the ease with which one can query chained relationships, called path query, between graph data, especially when compared to the JOIN query of relational tables.
Query objective: Retrieve detailed information about all patients treated by Dr. Michael Roberts, including their diagnosis results and the doctor's name.
SQL:
SELECT
PATIENT.PNO,
PATIENT.PNAME,
PATIENT.PSEX,
DIAGNOSIS.DIAGNOSISRESULT,
DIAGNOSIS.DNAME
FROM
guest.DIAGNOSIS
JOIN guest.PATIENT ON guest.DIAGNOSIS.PNO = guest.PATIENT.PNO
WHERE
DNAME = 'James Anderson'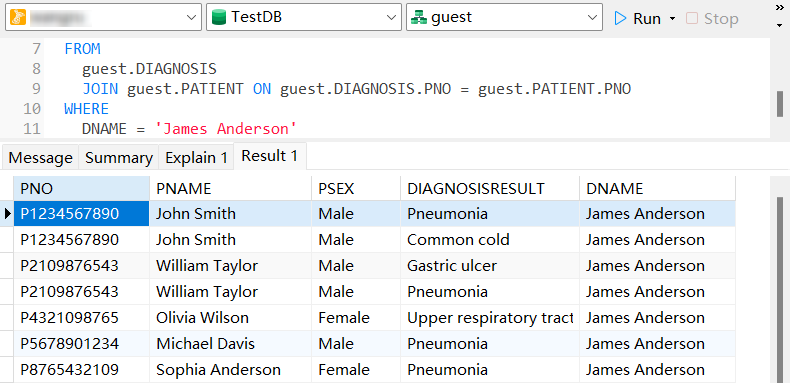
UQL:
n({@DOCTOR.DNAME == "James Anderson"} AS D)
.e({@DIAGNOSIS} AS A)
.n({@PATIENT } AS P)
RETURN table(
P._id,
P.PNAME,
P.PSEX,
A.DIAGNOSISRESULT,
D.DNAME
)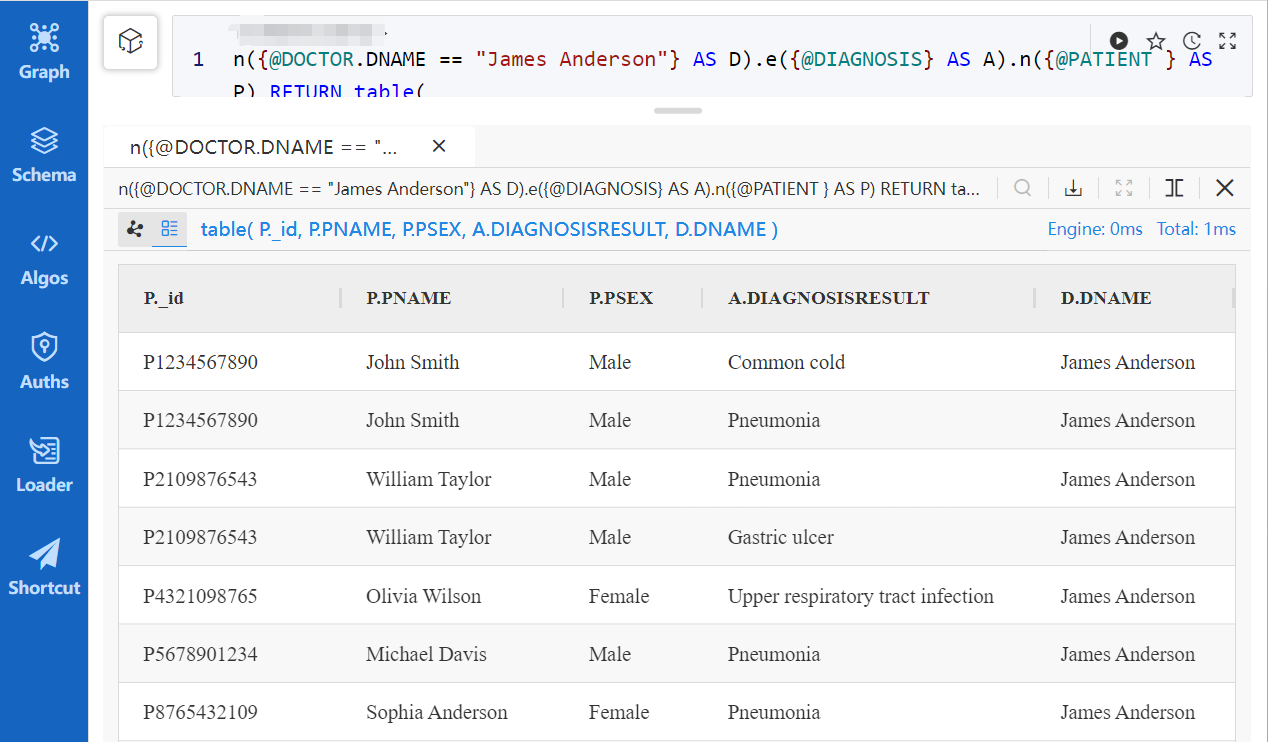 Result of path query using UQL
Result of path query using UQL
While it may not have been emphasized prominently in the preceding codes for querying a single table or schema, an intriguing observation emerges with these more extensive code excerpts: the syntax expressions of these two query languages are reversed. SQL commences by defining the data to be retrieved and subsequently outlines the filtering conditions the data must satisfy. On the other hand, UQL first delineates the criteria the data should meet and then specifies the data to be retrieved. This reversal in syntax order can impact developers' thought processes, leading to distinct programming experiences.
 Comparison of syntax orders, SQL (left) vs. UQL (right)
Comparison of syntax orders, SQL (left) vs. UQL (right)
Let's shift our focus back to the representation of data relationships. SQL uses JOIN to link tables and applies ON to anchor key fields (primary keys, foreign keys). In contrast, UQL employs a path template n().e().n() to systematically define the interconnected nodes and edges, essentially eliminating the need for additional anchoring steps.
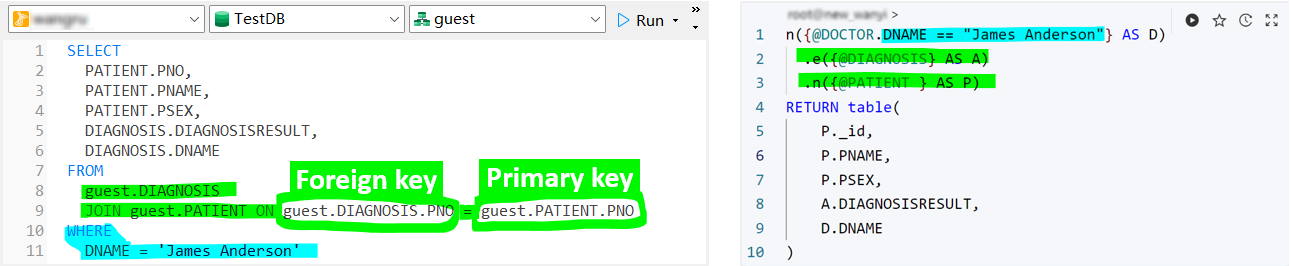 Comparison of relationship expressions, SQL (left) vs. UQL (right)
Comparison of relationship expressions, SQL (left) vs. UQL (right)
Why can a graph query language, in this case, UQL, achieve such a streamlined expression? This is because the inherent anchoring relationships between tables, namely the links from foreign keys to primary keys, are seamlessly embedded within the edge data (_from and _to). This fundamental integration is precisely why graph databases outperform relational databases in efficiently managing associative relationships.
Moreover, UQL directly incorporates filtering conditions into every node and edge declaration, the n() and e(), unlike SQL's WHERE clause, which adds filtering conditions after joining all tables and anchoring. This approach makes UQL syntax more concise, and cohesive and enhances code readability.
UQL ingeniously consolidates every node and edge, along with their filtering conditions, into a natural, chain-like path model.
It's worth highlighting that although the SQL and UQL snippets above are similar in length and produce identical results, their actual querying functions differ from the bottom. In the example above, SQL only accomplishes the connection between two tables, PATIENT and DIAGNOSIS, retrieving the doctor's name (DNAME) from the DIAGNOSIS table. In comparison, UQL establishes relationships among PATIENT, DIAGNOSIS, and DOCTOR, essentially performing a JOIN across three tables (schemas). It returns D.DNAME, a property of the node schema DOCTOR. Understanding these underlying distinctions adds irony to the performance comparison: the SQL query took 3ms, whereas the UQL query, handling more data correlations, only took 0.5ms.
The shift from 3ms to 0.5ms might appear inconsequential, but as the number of chained relationships being queried increases, it becomes remarkably pronounced. A recursive 5-table JOIN query in SQL against a small table of 10,000 rows will take 38 seconds, whereas the equivalent query achieved by a 5-step path template in UQL only takes 0.001 seconds. In more general cases, SQL tends to struggle when executing lengthy chained table JOINs against large datasets. While the inefficient leverage of concurrency does contribute to this substantial distinction, the Cartesian product of table records in all JOIN procedures is a fundamental reason for the exponential level of performance degradation in SQL queries compared to UQL.
Tips on Using Graph Query
So far, we have been presenting the query results of UQL in a traditional tabular format for comparison with SQL. However, we strongly advocate representing the results of path queries on small-scale graphs using 2D/3D visualizations. This approach facilitates a more intuitive understanding and analysis of the data.
The query objective achieved in this article represents one-step paths in the graph. Upon reconfiguring the return values of the provided UQL into these paths and executing the query, the 2D results obtained in Ultipa Manager appear as follows:
n({@DOCTOR.DNAME == "James Anderson"})
.e({@DIAGNOSIS})
.n({@PATIENT}) AS p
RETURN p{*}Conclusion
In this article, our goal is not to showcase all aspects of how a graph query language differs from a structured data query language. Instead, we aim to convey how a graph database should fundamentally design its query language and why SQL may not be suitable for querying graph data.
The simplicity in code composition and query efficiency against a native graph provide a valuable insight—perhaps when handling data, we should embrace a more intuitive and natural approach, akin to understanding the world through a graph, rather than getting entangled in the abstract data networks of relational databases.
Opinions expressed by DZone contributors are their own.
Comments