A Step-by-Step Guide: How to Convert Tables to Graph
Graph Data Modelling How-to convert table into graph
Join the DZone community and get the full member experience.
Join For FreeBackground
"Even though I've mastered many graph query commands, when I started modeling my graph, I still felt like a novice."
These were the words of one of our clients, reflecting a common sentiment among beginners of graph databases when they transit from a familiar relational database to the world of graph databases.
While we often stress the importance of query languages in our guidance for newcomers, the primary challenge faced by most users in practical applications isn't crafting query statements but seamlessly migrating their data to a graph database. This challenge is especially prominent when transitioning from conventional relational databases.
Whether the user's data is structured in tables or not, it often cannot be directly converted into graph data. Graph data adheres to specific requirements: nodes must possess unique IDs serving as their identity cards, while edges must have designated FROM and TO, both referencing node IDs within the graph. Only then can we truly appreciate the beauty of an edge, "a magnificent bridge linking nodes together!"
 A visualization of the graph
A visualization of the graph
This arduous data migration journey usually involves numerous rounds of fine-tuning data schemas[1]. If there were any golden rules or sacred principles in this battle of data transformation, they would be: to meticulously focus on the primary keys and foreign keys within the original tables. These keys will become the IDs for nodes and the FROM and TO for edges, making them the pivotal elements for successfully obtaining graph data.
Let's delve into a practical example demonstrating how to transform the table structure of a Hospital Information Management System built using SQL Server into a graph model and then import the resulting graph data into an Ultipa graph system.
Tables in SQL Server
1. Table Structures
In simplifying matters, consider this Hospital Information Management System holding fundamental details about doctors, patients, departments, and hospital beds, alongside records of doctors' consultations and patients' hospitalizations. All these data are stored across six distinct tables:
Let's create a diagram to visually depict the relationships among these tables:
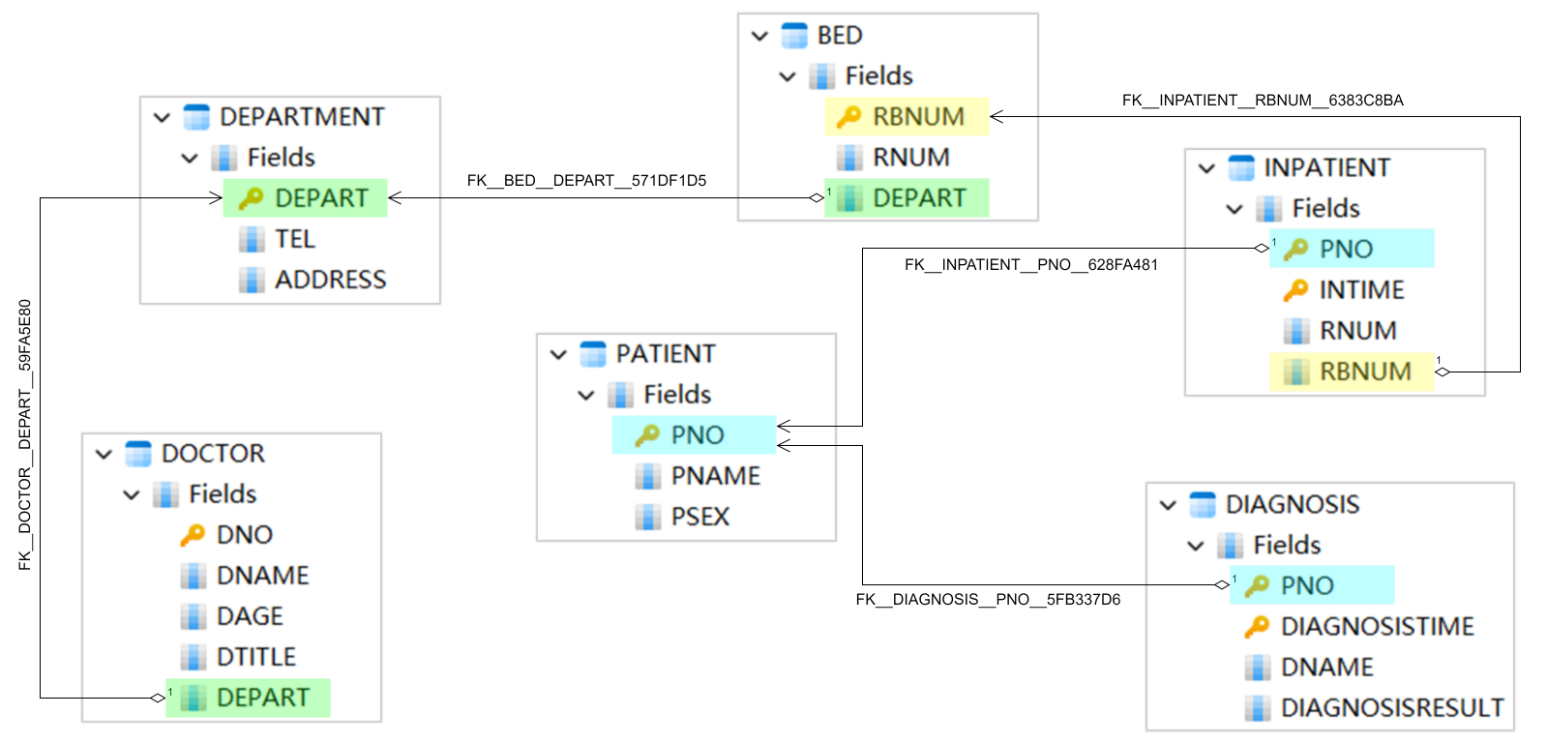
In the diagram provided, the arrows starting from foreign keys and ending at primary keys indicate how tables are interlinked and how SQL join queries are executed. For instance, to gather information about patients, including their names, genders, and diagnoses, seen by a specific doctor during a specific timeframe, one must focus on the field PNO, linking the DIAGNOSIS table with the PATIENT table. For readers well-versed in SQL, this type of table join query is undoubtedly a familiar sight.
This initial table structure design also has its imperfections. For example, in the DIAGNOSIS table, the doctor's name DNAME is recorded instead of their unique identifier, DNO. This design flaw results in a missing foreign key, hindering the DIAGNOSIS table from establishing a connection with the DOCTOR table to obtain detailed doctor information. Although remedial approaches could be taken by adding some common information about doctors in the DIAGNOSIS table, such as the department name DEPART, to sidestep the complexities of join queries, the challenges stemming from redundant storage, such as disk space consumption and data consistency checks, cannot be underestimated. In the subsequent design of the graph database model, these dilemmas will no longer pose hurdles.
2. Data in Tables
Let's input sample data into the aforementioned tables and amalgamate the information from all tables into a singular diagram:
While the tabular representation, though systematic, provides a detailed and transparent overview of individual data fields, it lacks the ability to illuminate the high-dimensional interactions between data records. Questions like "Which department's doctor attended to which patient" or "Which patient was allocated to which ward in a specific department" are complex to deduce solely from tables. This intuitive understanding becomes notably challenging when contrasted with the forthcoming graph model we are about to construct.
Graph Modeling With Ultima
1. Distinguish Nodes and Edges
Let's begin by adopting the existing work: conceptualize each table as a schema, with the data fields serving as the properties within that schema. The challenge lies in distinguishing nodes from edges.
In essence, all tables can be likened to real-world entities, but only the most genuine entities serve as nodes. Therefore, we've identified DEPARTMENT, DOCTOR, BED, and PATIENT as nodes, utilizing their primary keys as node IDs (denoted by _id).
INPATIENT should not be misconstrued as a subset of PATIENT, since it captures the relationship between PATIENT and BED as evidenced by its two foreign keys. Define INPATIENT as an edge and specify its two foreign keys as the FROM and TO of the edge (denoted by _from and _to).
(Feel free to interchange the FROM and TO of the edge as long as the edge's meaning remains coherent. For instance, setting PATIENT's _id as FROM and BED's _id as TO signifies 'patient check-in to a bed', while the reverse suggests 'bed receives a patient'.)
Applying a similar rationale, designate DIAGNOSIS as an edge to encapsulate the connection between DOCTOR and PATIENT. In determining its FROM and TO, fill in the missing foreign key linking to DOCTOR by replacing DNAME with DNO. This missing link issue was previously addressed when explaining the table structure and has now been rectified in the edge design phase.
Node IDs are extracted from the original table's primary key, whereas the FROM and TO for edges are derived from the original table's foreign keys, supplemented where necessary.
Curious minds might wonder, "Do edges have IDs?" The answer is a resounding yes. In fact, we typically use the primary keys of tables designated as edges as their respective IDs. This logic mirrors the approach for node IDs. However, the focus isn't placed on edge IDs because, for edges, the designation of FROM and TO holds greater significance.
2. Adjust Schemas
Two foreign keys in the original tables are still unaddressed: DEPART in the DOCTOR and BED tables, both of which link to the primary key of DEPARTMENT. This raises the question of how to handle foreign keys originating from tables designated as nodes.
As illustrated in the diagram below, solve these two foreign keys by introducing two new edge schemas, WORKAT and BELONG TO, which equals adding two fresh tables to the original structure.
The introduction of WORKAT and BELONGTO enables the removal of the DEPART from DOCTOR and BED. As these new schemas are minimalized with only FROM and TO, additional properties can be incorporated on-demand to accommodate real-world scenarios.
Up to this juncture, all the primary keys and foreign keys in the tables are addressed. One last refinement is to isolate the RNUM field, denoting room numbers, from the BED table into a node schema ROOM, since many hospitals require calculating room occupancy or managing facilities within the room.
Some residual steps are: removing the redundant RNUM from both the BED and INPATIENT, and sharing BELONGTO between BED-ROOM, ROOM-DEPARTMENT, and DOCTOR-DEPARTMENT since all these relationships require only properties FROM and TO.
3. Inject Graph Data
Now cleanse and transform the tabular data into graph data in alignment with the above established graph model. Assuming each table's data is stored as an individual CSV file (e.g., DOCTOR's data saved as DOCTOR.csv) with the field names serving as headers in the file, the transformation process entails header modifications, column content replacements, and the creation of new CSV files. The detailed steps are as follows:
- In DEPARTMENT.csv, PATIENT.csv, DOCTOR.csv and BED.csv, rename headers of columns containing primary keys to '_id'.
- In IMPATIENT.csv, rename header 'PNO' to '_from', rename header 'RBNUM' to '_to', and delete the entire column 'RNUM'.
- In DIAGNOSIS.csv, rename header 'PNO' to '_to', rename header 'DNAME' to '_from', and replace the data under 'DNAME' with the corresponding data from the '_id' column in DOCTOR.csv.
- Create BELONGTO.csv with headers '_from' and '_to'.
- Copy the data under '_id' and 'DEPART' in DOCTOR.csv to '_from' and '_to' in BELONGTO.csv, ensuring the corresponding relationships of data in the same row are maintained. Then, delete the entire 'DEPART' column in DOCTOR.csv.
- Create ROOM.csv with header '_id.'. Copy the unique values under 'RNUM' in BED.csv to the '_id' column in ROOM.csv.
- Copy the data under '_id' and 'RNUM' in BED.csv to '_from' and '_to' in BELONGTO.csv, ensuring the corresponding relationships of data in the same row are maintained.
- Copy the unique combined values under 'RNUM' and 'DEPART' in BED.csv to '_from' and '_to' in BELONGTO.csv, ensuring the corresponding relationships of data in the same row are maintained. Then delete the entire 'RNUM' and 'DEPART' columns in BED.csv.
As a reminder, it may be necessary to process primary keys to ensure that their associated IDs are unique[2] throughout the entire graph. While this doesn't apply to the data presented in this article, it is a common challenge encountered by numerous users.
Multiple approaches are available to import graph data into designated graphs within the Ultipa graph system. Such as uploading CSV files individually through Ultipa Manager, a user-friendly visualization tool for managing the Ultipa Graph system, or bulk importing all files at once via the command-line utility, Ultipa Importer.
In Ultipa Manager, the ID, FROM and TO are not visible in the schema list. These are system-generated properties that cannot be modified or deleted.
Ultipa Manager's 2D rendering feature utilizes vibrant colours and icons, ensuring that relationships between different entities are distinctly visible. A quick glance allows easy identification of the interconnected nodes in the graph. This intuitive and convenient visualization sets graph databases apart, surpassing the capabilities of traditional relational databases. It greatly enhances the ease and pleasure of data analysis and exploration.
Conclusion
We trust this article has provided valuable insights into graph modelling, especially for newcomers venturing into the world of graph databases. In practical scenarios, constructing graph models involves more intricate situations. On the other hand, the graph model itself is not fixed, adaptable modifications are required to meet the changing business needs all the time.
Notes:
[1] Schema: In certain relational databases like MySQL or PostgreSQL, the hierarchical data management structure within a server connection is defined as 'database-schema-table-field'. In Ultipa graph systems, this translates to 'graph-schema-property', where a schema in the Ultipa graph system corresponds to a table in relational databases, and schema properties are akin to table fields.
[2] In Ultipa, node IDs possess global uniqueness throughout the entire graph, not confined to a specific schema. For instance, if 'ABC' is the ID for a particular doctor, it cannot be used as the ID for any patient or any other node within the same graph. Conversely, primary keys in relational databases only require uniqueness within their respective tables, allowing different tables to have duplicate primary keys. Consequently, certain primary keys need additional processing before they can be utilized as IDs for graph data, and so do associated foreign keys.
Opinions expressed by DZone contributors are their own.
Comments