When Events Move Faster Than Your Database: A Resilient Design Pattern
This article explores a practical and resilient design pattern that addresses this problem by embracing asynchronous processing and eventual consistency.
Join the DZone community and get the full member experience.
Join For FreeEvent-driven systems are designed for speed, scalability, and decoupling. Messages flow rapidly between services, consumers react almost instantly, and systems can evolve independently without tight coordination. However, this speed introduces a subtle challenge, especially in hybrid cloud environments: ensuring that what is published as an event is consistently reflected in the system’s durable state.
In many modern architectures, event publishing and database persistence are no longer co-located. They span regions, networks, and even cloud providers. While this enables flexibility and scalability, it also introduces latency, partial failures, and timing mismatches that are difficult to reason about.
The core issue arises when events move faster than the database can keep up. This creates a temporary but critical inconsistency between the event stream and the actual stored state. Over time, these inconsistencies can accumulate, leading to unpredictable system behavior.
This article explores a practical and resilient design pattern that addresses this problem by embracing asynchronous processing and eventual consistency.
Architecture Context
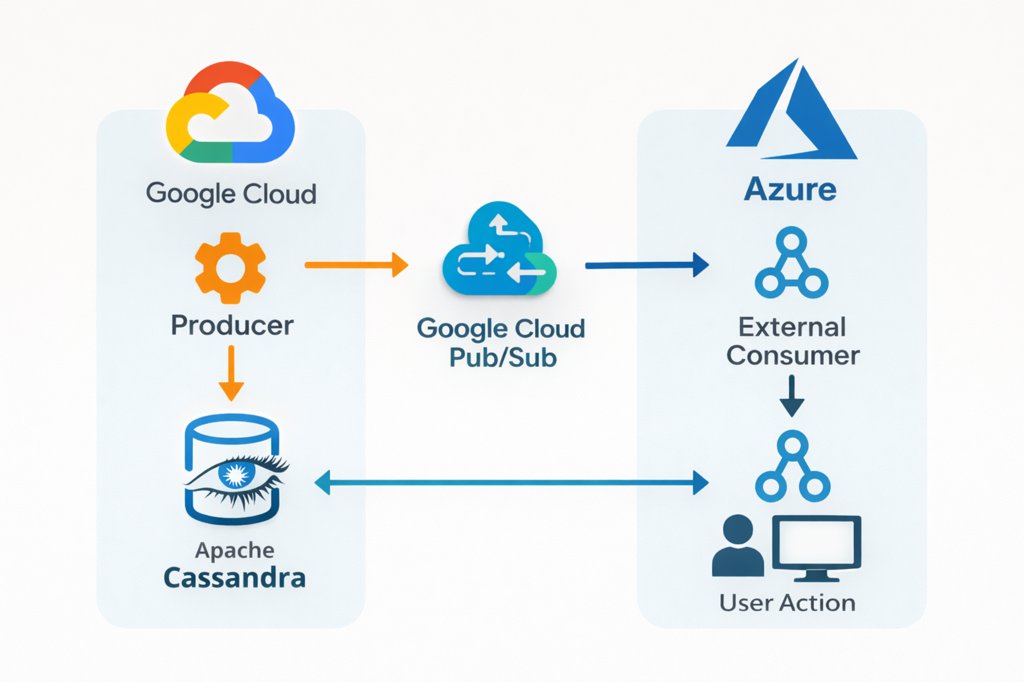
In our system, the producer operates in Google Cloud and publishes events to Google Cloud Pub/Sub. Cassandra, which serves as the system of record, is hosted in Azure. External consumers subscribe to Pub/Sub and react immediately to incoming events.
Initially, the producer was responsible for both publishing events and updating Cassandra. On paper, this seems straightforward. However, in practice, cross cloud communication introduces unpredictable latency and failure modes.
While Pub/Sub provides strong guarantees around durability and delivery, Cassandra writes across cloud boundaries were less reliable. Even with retries, writes could fail due to transient network issues, increased latency, or timeout thresholds. In some cases, writes would succeed after significant delay, creating a lag between event publication and state persistence.
This created a fundamental architectural tension between speed and consistency.
The Consistency Gap
Once an event is successfully published to Pub/Sub, it is delivered to consumers almost immediately. These consumers may trigger downstream workflows, make decisions, or initiate further processing based on the event.
However, the corresponding Cassandra record might not yet exist at that moment. It may still be in-flight, delayed, or even failed due to transient issues. This results in a consistency gap where the system’s event stream indicates that something has happened, but the database does not yet reflect it.
This gap is particularly problematic because it is non-deterministic. Some events align perfectly with database state, while others lag behind. This inconsistency can lead to race conditions, incorrect assumptions in downstream systems, and increased operational complexity.
Attempting to eliminate this gap by blocking event publishing until database writes complete introduces its own challenges. It increases latency, reduces throughput, and tightly couples event availability to database health, which is undesirable in distributed systems.
Design Goals
To address this challenge, the system needed to satisfy several key goals. First, event publishing must remain fast and highly available, ensuring that producers are not blocked by downstream dependencies. Second, database writes must eventually succeed, even in the presence of transient failures. Third, the system must guarantee convergence, meaning that over time, the database state will accurately reflect all published events. Rather than striving for immediate consistency, the design needed to embrace eventual consistency with strong guarantees of reconciliation.
The Listen-to-Yourself Pattern
The solution involved a shift in how responsibilities were assigned within the system. The producer was simplified to focus solely on publishing events. It no longer waits for Cassandra writes to complete, nor does it treat database persistence as part of the publishing workflow.
Instead, an internal consumer was introduced. This consumer subscribes to the same Pub/Sub topic as external consumers and processes the same stream of events. However, its sole responsibility is to update Cassandra.
This internal consumer operates within the Azure environment, closer to Cassandra. As a result, it avoids many of the latency and reliability issues associated with cross-cloud communication. It can perform retries more efficiently and apply idempotent updates to ensure correctness even in the presence of duplicate messages.
This pattern effectively allows the system to listen to its own events and reconcile its state accordingly, hence the name “Listen-to-Yourself.”
Publish First, Reconcile Later
This design introduces a fundamental shift in how the system operates. Instead of following a write-first-then-publish approach, the system now follows a publish-first-then-reconcile model.
Once an event is acknowledged by Pub/Sub, it becomes part of the system’s durable event log. This event log represents the source of truth. The database is no longer the primary authority; instead, it becomes a projection of the event stream.
The internal consumer ensures that every event in the stream is eventually reflected in Cassandra. Even if the initial write fails, the event remains in Pub/Sub and will be retried until it is successfully processed.
This decoupling removes database dependencies from the critical path, allowing the system to maintain high throughput and resilience.
Why This Pattern Works
The strength of this approach lies in its separation of concerns. Publishing is optimized for speed and reliability, while persistence is handled asynchronously. This ensures that failures in one part of the system do not cascade into others.
Retries are localized within the internal consumer, reducing the impact of transient failures. Idempotency ensures that repeated processing of the same event does not lead to inconsistent data.
Additionally, the system becomes self-healing. Any missed or delayed writes are automatically corrected through reprocessing of events. This significantly reduces the need for manual intervention and simplifies operational overhead.
Trade-Offs and Considerations
This pattern does not provide strict transactional guarantees. There is a window during which consumers may observe events before the corresponding database state is updated. However, this trade-off is often acceptable in distributed systems where availability and performance are prioritized.
To make this approach effective, certain considerations must be addressed. Idempotent processing is critical to handle duplicate events safely. Monitoring and observability are important to detect delays in reconciliation. Additionally, back pressure mechanisms may be needed to handle spikes in event volume.
Despite these considerations, the benefits of resilience and scalability often outweigh the drawbacks.
Conclusion
In hybrid cloud environments, enforcing strict synchronization between event publishing and database persistence can lead to fragile systems. Instead, embracing asynchronous processing and eventual consistency enables more robust architectures.
The Listen-to-Yourself pattern provides a practical way to ensure alignment between events and state without compromising performance. By treating the event stream as the source of truth and reconciling state asynchronously, the system achieves reliable convergence.
When events move faster than your database, the solution is not to slow down the system, but to design it to adapt. In distributed systems, resilience comes not from preventing inconsistencies, but from ensuring they are eventually resolved.
Opinions expressed by DZone contributors are their own.
Comments