Understanding AI Agent Types:Guide to 8 Modern AI Architectures
A guide to eight AI agent types with implementations, real-world use cases, and selection framework. Learn about LCM, HRM, LAM, SLM, VLM, LRM, MOE, and GPT architectures.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I will discuss eight major AI agent types: LCM, HRM, LAM, SLM, VLM, LRM, MOE, and GPT, optimized for specific problem domains, technological implementations, and practical applications. By understanding the strengths and limitations of each architecture, practitioners can make informed decisions when designing AI systems for production environments.
Introduction
The landscape of AI agents has transformed dramatically over the past five years. Rather than developing single models to address all problems, the industry has converged on specialized architectures, each tailored to specific computational and reasoning requirements. This article provides practitioners, researchers, and decision-makers with a detailed roadmap of eight foundational agent types, complete with technological stacks and implementation guidance.
Overview ![Overview]()
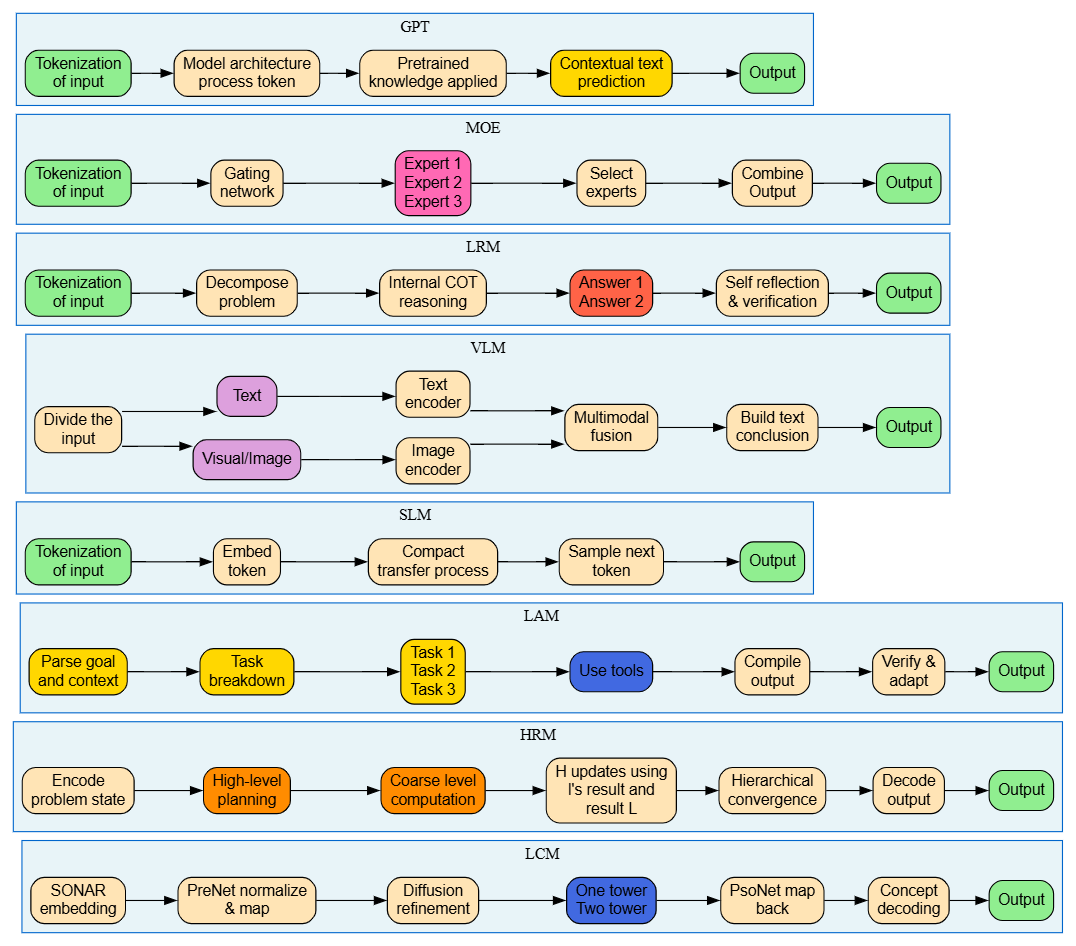
1. LCM (Latent Code Model)
Overview
LCM agents operate through embedding-based refinement, transforming raw input into structured latent (hidden) representations. They use advanced diffusion-based techniques to progressively refine code or representations through multiple iterations, making them particularly effective for tasks requiring step-by-step optimization.
What it does: Understands code semantically and suggests optimizations by learning patterns from millions of code repositories.
How it works: Converts code into semantic embeddings (SONAR), normalizes them, iteratively refines through diffusion (improving something little by little instead of all at once) processes, and decodes optimal patterns back into actionable suggestions.
For beginners: Think of it as a senior developer who deeply understands what your code does and suggests better ways to write it.
Tech stack: PyTorch/Diffusers, Hugging Face Transformers, FAISS vector search, Docker/Kubernetes
Metrics: 200–500 ms latency | 82–89% accuracy | $0.02–0.05 per suggestion
Example:
A developer writes partial code to calculate variance like this:
def calculate_stats(data): # need to optimize thisLCM agent embeds the code context, understands the computation pattern, learns that it could use NumPy vectorization, and suggests:
"Use NumPy arrays instead of loops for 10x performance."2. HRM (Hierarchical Reasoning Model)
Overview
HRM agents split hard problems into different levels, like a ladder. They handle big-picture planning and rough calculations separately, then combine the results. This lets them do smart thinking across many layers at the same time.
What it does: It solves tough problems with many layers by planning big ideas at the top and figuring out details at the bottom, and makes sure everything fits together without conflicts.
How it works: Encodes the problem, creates high-level strategic plans, performs coarse computations, feeds results back up to adjust strategy, and iterates until convergence.
For beginners: Like a CEO working with department managers, the top-level sets targets, departments work out feasibility, and feedback adjusts targets until everyone agrees.
Tech stack: Pyomo/Gurobi optimization, TensorFlow Extended (TFX), Neo4j graphs, Apache Airflow orchestration
Metrics: 5–30 min planning time | 95–99% optimality | $0.50–$5.00 per problem
Example: Manufacturing plant needs to maximize Q4 profit while meeting demand and staying in budget. HRM strategically targets $10M revenue, calculates it needs $6M materials, checks if the facility can handle it (can only do 40,000 units instead of the 50,000 target), and revises the plan to 40,000 units at 85% margin.
Scenario: Strategic quarterly production planning for manufacturing
An HRM agent tackles: "Maximize profit while meeting demand and staying within budget."
-
High-level (Strategic):
- Identify revenue targets: $10M quarterly
- Budget constraints: $6M manufacturing cost
- Market demand forecast: 50,000 units
-
Coarse-level (Tactical):
- Rough material requirements: 150 tons
- Workforce needs: 200 workers
- Facility utilization: 75%
-
Iteration:
- High-level constraints refined: Feasibility checked
- Facility constraint: Can only process 40,000 units
- Revise targets and recompute
-
Result: Optimized plan — 40,000 units, 45 workers, 85% margin
3. LAM (Language Agent Model)
Overview
LAM agents excel at breaking natural language goals into concrete subtasks, using external tools to execute them, then verifying and adapting results. They're engineered for task decomposition and tool orchestration, making them ideal for automation workflows.
What it does: Understands natural language goals, breaks them into concrete subtasks, uses available tools to execute each, verifies results, and adapts if needed.
How it works: Parses user intent, decomposes into independent tasks, routes each to specialized tools (APIs, databases, services), compiles results, validates, and adapts as needed.
For beginners: Like a personal assistant who understands your request in English, knows which tools to use, executes them, and ensures everything worked before giving you the final answer.
Tech stack: LangChain orchestration, OpenAI/Anthropic APIs, Zapier (6000+ integrations), Celery task queue, Pydantic validation
Metrics: 5–30 sec execution | 80–88% completion success | $0.01–0.05 per task
Example:
Scenario: Automated travel itinerary planning assistant
User request: "Plan a 3-day Tokyo trip, $2000 budget, loves sushi and temples."
LAM parses this, breaks into: flight search (Skyscanner API -> $850), hotel booking (Booking.com AP -> $270), temple identification (Google Places), restaurant search (TripAdvisor), itinerary compilation, budget verification, final output.
4. SLM (Small Language Model)
Overview
SLM agents are compact, efficient language models optimized for speed and edge deployment. They maintain core language understanding while minimizing computational overhead, enabling real-time inference on resource-constrained devices.
What it does: Delivers fast language understanding on edge devices (phones, IoT) with minimal memory and power consumption.
How it works: Converts text to tokens, embeds in a small vector space (256D instead of 2048D), processes through lightweight neural layers, and predicts next token probabilistically.
For beginners: Like a small brain in your phone that's fast and doesn't drain battery, compared to a giant server that's smarter but needs internet.
Models: Mistral 7B, Phi-3 (3.8-14B), TinyLlama 1.1B, DistilBERT, MobileBERT
Tech stack: TensorFlow Lite, PyTorch Mobile, ONNX Runtime, CoreML (Apple), MediaPipe
Metrics: 10–100ms latency | 80–85% accuracy | 50–500 MB model size
Example: Gboard mobile keyboard predicts your next word as you type "How are y..."-> shows "you" (92%), "your" (6%), "young" (2%) suggestions in <50ms, all on-device with no internet required.
Scenario: On-device mobile keyboard prediction system
User types on smartphone: "How are y..."
The SLM agent:
- Tokenizes: ["How", "are", "y"] -> token IDs [342, 589, 1024]
- Embeds: Converts to 256-dimensional vectors (fits in 100KB)
- Processes: Through lightweight transformer layers:
- Layer 1: "How are" context analyzed in 2ms
- Layer 2: Next word predicted in 1ms
- Samples: Generates top predictions:
- "you" (92% confidence)
- "your" (6% confidence)
- "young" (2% confidence)
- Outputs: "you" suggestion appears instantly, no cloud latency
5. VLM (Vision Language Model)
Overview
VLM agents process visual and textual information simultaneously using separate encoders for each modality and fusing them for comprehensive understanding. They enable systems to reason about images and text together.
What it does: Understands images and text together by processing them separately through specialized encoders, then fusing their meanings for joint reasoning.
How it works: Separates input into image and text streams, encodes images via ViT/CLIP, encodes text via BERT/GPT, fuses representations, and reasons over the combined meaning.
For beginners: Like understanding a meme by reading both the image and caption together — you need both to get the full meaning.
Tech stack: CLIP/ViT/DINOv2 encoders, Ray Serve, Weaviate vector database, Triton Inference Server
Metrics: 150–700ms latency | 80–90% accuracy | 2–8 GB model size
Example: Social media moderation analyzes a post with a climate protest image and a caption, "Great protest for climate action today!" VLM watches peaceful gathering (image) + environmental activism language (text) + high alignment -> approves. If the image showed a beach vacation but the caption said "Join protest tomorrow," -> flags misalignment for human review.
Scenario: Automated content moderation for social media
Post contains:
- Image: Crowded street scene with people holding signs
- Caption: "Great protest for climate action today!"
The VLM agent:
- Divides input: Image and text separated
- Image path:
- Encodes visual features: people, outdoor setting, gathering, peaceful
- Detects: No weapons, no violence, organized group
- Sentiment: Constructive assembly
- Text path:
- Encodes caption: "protest," "climate action," "positive tone"
- Sentiment: Supportive of activism
- Fuses information:
- Image shows: Peaceful assembly
- Text indicates: Environmental activism
- Alignment: Strong match, legitimate activism
- Concludes: "Legitimate climate activism post"
- Outputs:
- Approval: done
- Confidence: 94%
- Category: Environmental Activism
- Action: Approve and promote
Alternative scenario (image-text mismatch):
- Image: Tropical beach vacation
- Caption: "Join our protest tomorrow"
- Output: Flag for manual review (misalignment detected)
6. LRM (Long-Range Reasoning Model)
Overview
LRM agents are designed for extended reasoning processes, employing chain-of-thought reasoning, decomposition, and self-verification to solve complex problems requiring multiple reasoning steps and deep analysis.
What it does: Solves complex problems requiring deep multi-step thinking, exploring multiple solution paths, and verifying answers before output.
How it works: Tokenizes input, decomposes into logical parts, explores multiple reasoning chains simultaneously, generates candidate answers, self-critiques each, and outputs the verified best answer.
For beginners: Like a researcher showing their work, trying different approaches, checking each one, and only publishing the answer they're confident in.
Tech stack: Claude 3/GPT-4 Turbo (128K context), DSPy reasoning framework, Z3/CVC4 solvers, SymPy mathematics
Metrics: 5–60 sec inference | 85–95% accuracy | $0.10–$2.00 per problem
Example: Math problem: "Train A leaves at 2 PM at 60mph, Train B leaves at 3 PM at 70mph from 100 miles away toward each other. When do they meet?" LRM tries speed-based approach (combined 130mph, 40-mile gap after 1 hour, 18.5 min) and equation-based approach (130t=170, t=1.308 hours), verifies both agree on 3:18:30 PM, outputs verified answer with confidence 99.8%.
Scenario: Solving complex multi-step mathematical problem
The LRM agent:
- Tokenizes: Breaks problem into tokens
- Decomposes:
- Variables: Speed1=60, Speed2=70, Distance=100, StartTime1=2PM, StartTime2=3PM
- Relationships: They travel toward each other
- Constraints: Meet at same time and location
- Equation needed: Solve for meeting time
- Reasoning path 1 (Speed-based approach):
Plain Text
Combined approach speed = 60 + 70 = 130 mph Time for first train alone = 1 hour (3 PM - 2 PM) Distance covered by first train = 60 × 1 = 60 miles Remaining distance = 100 - 60 = 40 miles Time to meet after 3 PM = 40 / 130 ≈ 0.308 hours ≈ 18.5 minutes Meeting time = 3:18:30 PM - Reasoning path 2 (Equation-based approach):
Plain Text
Let t = hours after 2 PM Distance by Train 1: 60t Distance by Train 2: 70(t-1) [starts 1 hour later] Meet when: 60t + 70(t-1) = 100 60t + 70t - 70 = 100 130t = 170 t = 1.308 hours = 1 hour 18.5 minutes Meeting time = 2 PM + 1:18:30 = 3:18:30 PM
- Generates answers:
- Answer A: 3:18:30 PM
- Answer B: 3:19 PM (rounding variation)
- Answer C: 3:20 PM (approximation error)
- Verifies each:
- Answer A: Validates in both equations
- Answer B: Rounding causes small error
- Answer C: Fails verification
- Meeting location: 78.46 miles from Station A
- Outputs:
Plain Text
Answer: 3:18:30 PM (1 hour 18 minutes 30 seconds after 2 PM) Location: 78.46 miles from Station A Confidence: 99.8% Reasoning steps: 12 verified
7. MOE (Mixture of Experts)
Overview
MOE agents use a gating mechanism to dynamically route inputs to specialized expert networks. Different types of problems will be handled by different experts, improving efficiency and specialization while maintaining flexibility.
What it does: Routes different types of problems to specialized expert networks that each excel in their domain, combining their strengths.
How it works: Analyzes input characteristics, gating network routes to appropriate expert(s), experts process in parallel, results combined into final output.
For beginners: Like a hospital system, where a patient comes in, they're assessed, routed to specialists (orthopedics, cardiology, etc.) based on symptoms, specialists work on their part, and results are combined for diagnosis.
Tech stack: Mixtral 8x7B, Kubernetes + Istio mesh, HAProxy load balancing, Prometheus metrics, NGINX
Metrics: 50–200ms routing latency | 94–97% accuracy | 500–5000 req/s throughput
Example: Customer service ticket "My payment won't process and I can't access my account" gets routed: Billing Expert (65% weight) analyzes payment logs and finds the account flagged for fraud. Security Expert will (35% weight) check logins ... finds 5 failed attempts from different IPs, then confirms security hold active. Combined response: "Complete 2FA verification to restore access (typically 2-5 min)."
Scenario: Customer service routing and support system
Customer submits ticket: "My payment isn't processing, and I can't access my account."
The MOE agent:
- Tokenizes: Analyzes ticket content
- Gating network analyzes:
- Keywords: "payment", "account access" -> Billing + Security
- Urgency: High (payment issue) -> Priority routing
- Customer tier: Premium -> Expert level routing
- Issue complexity: Medium (multiple systems)
- Routes to experts:
- Billing Expert: 65% weight and Security Expert: 35% weight (Other experts: 0%)
- Experts process (in parallel):
- Billing expert:
- Analyzes payment system logs
- Finds: Account flagged for unusual activity
- Suggests: "Verify identity for security"
- Billing expert:
- Security Expert:
- Analyzes login attempts
- Finds: 5 failed login attempts from different IPs
- Confirms: Security hold active
- Suggests: "Complete 2-factor verification"
- Compiles output:
Primary Solution: Complete 2FA verification Secondary Action: Reset payment method Timeline: 5 minutes to restore access Alternative: Call support hotline- Routes to human if complexity > threshold, otherwise:
Outputs: Unified response will be:
"Your account has been temporarily secured due to unusual activity. To restore access, complete 2-factor verification in your settings. This typically takes 2-5 minutes."Benefits demonstrated:
- Multiple experts consulted simultaneously
- Load balanced: high-volume tickets redirected to multiple expert paths
- Specialized knowledge applied: Security + Billing
- Scalable: Can add new experts without retraining entire system
8. GPT (Generative Pre-Trained Transformer)
Overview
GPT agents use a transformer architecture with pre-trained knowledge to generate contextually relevant text. They leverage massive unsupervised learning to understand patterns in language and generate human-like responses.
What it does: Generates human-like text by learning language patterns from massive internet-scale data, predicting probable next words in context.
How it works: Tokenizes input, processes through attention layers (each focusing on different word relationships), applies pretrained knowledge patterns, samples next token, repeats until complete.
For beginners: Like an autocomplete that learned from billions of sentences what words typically follow other words, so it writes naturally.
Models: GPT-4 Turbo, Claude 3, Llama 3, Gemini Pro, Mistral 8x7B
Tech stack: OpenAI/Anthropic/Hugging Face APIs, LangChain orchestration, FastAPI serving, Langfuse monitoring
Metrics: 500ms–3s latency | 85–92% quality | $0.001–$0.02 per 1K tokens
Example:
Scenario: Professional email writing assistance
User prompt:
GPT agent:
- Tokenizes: Input into 40–50 tokens
- Processes through transformer:
- Attention layer 1: Identifies task (professional decline)
- Attention layer 2: Recognizes tone (grateful, diplomatic)
- Attention layer 3: Determines structure (greeting, reason, thanks, future)
- Applies pretrained knowledge:
- Professional communication patterns
- Courtesy conventions
- Corporate etiquette
- Relationship preservation strategies
- Predicts contextually:
- Most likely opening: "Dear [Name],"
- Probability: 94%
- Generates token-by-token:
Outputs: Complete, professional email ready to sendPlain Text
"Dear [Name], Thank you so much for the offer of [Position] at TechCorp. I am genuinely honored by your confidence in my abilities. After careful consideration, I have decided to pursue another opportunity that aligns more closely with my current career goals. However, I remain impressed by your company's innovation and would welcome the opportunity to stay in touch for potential collaboration in the future. I wish you and the team continued success. Best regards, [Name]"
Agent Selection
| Use Case | Recommended Agent | Secondary Option | Key Technologies |
|---|---|---|---|
| Mobile Keyboard Prediction | SLM | GPT | TensorFlow Lite, PyTorch Mobile, Quantization |
| Customer Support Chatbot | LAM | GPT | LangChain, OpenAI API, Zapier |
| Code Completion | LCM | GPT | SONAR, Diffusers, FastAPI |
| Strategic Planning | HRM | LRM | Pyomo, Neo4j, Apache Airflow |
| Image Understanding | VLM | - | CLIP, ViT, Ray Serve, Weaviate |
| Complex Problem Solving | LRM | HRM | Claude/GPT-4, DSPy, Z3 Solver |
| Multi-domain Support | MOE | LAM | Mixtral, Kubernetes, Istio |
| Content Generation | GPT | LAM | OpenAI API, LangChain, Langfuse |
| E-commerce Recommendation | MOE | VLM | Expert routing, Redis, Cassandra |
| Medical Diagnosis | LRM | VLM | Claude/GPT-4, Knowledge bases, SymPy |
How to Select
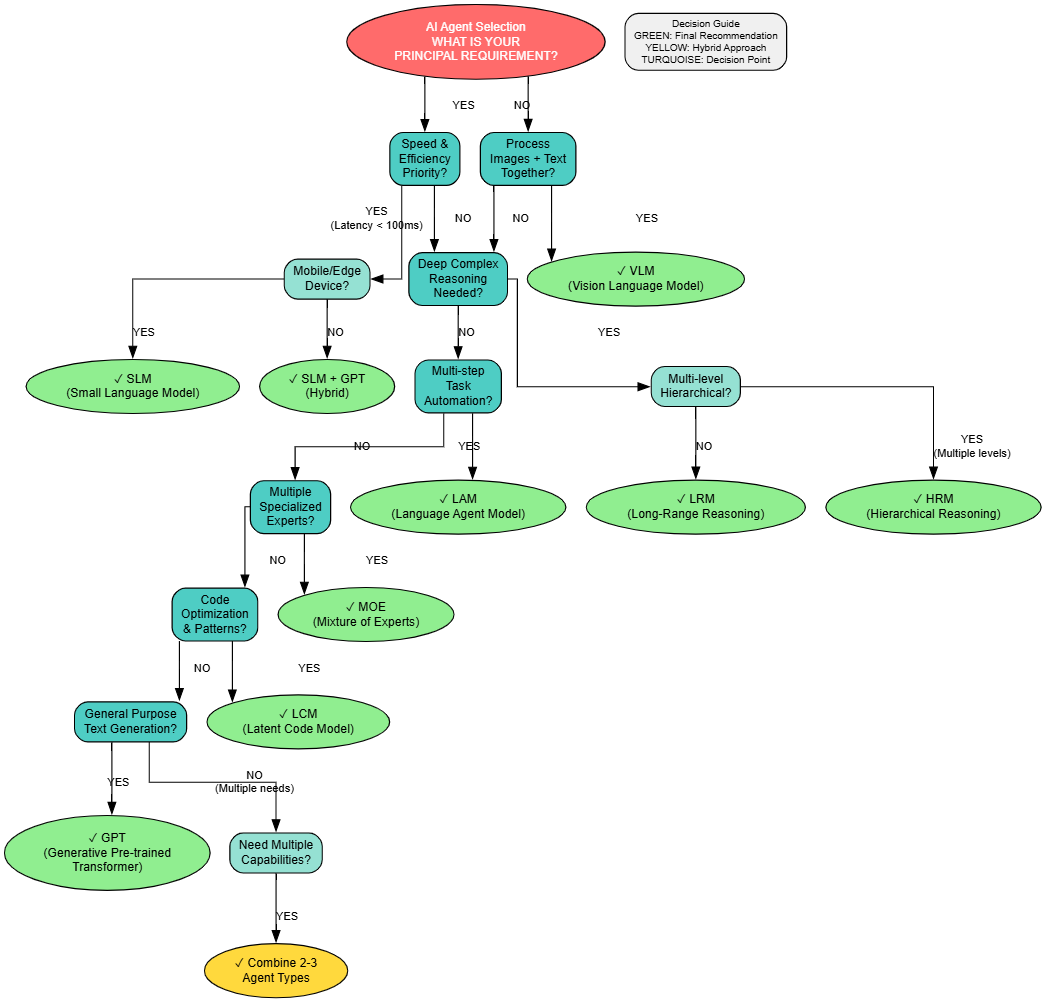
Conclusion
Each agent type, LCM, HRM, LAM, SLM, VLM, LRM, MOE, and GPT, offers distinct advantages suited to particular problems:
- Speed-critical systems: SLM
- Multimodal understanding: VLM
- Complex reasoning: LRM or HRM
- Task automation: LAM
- Specialized routing: MOE
- General-purpose generation: GPT
- Code optimization: LCM
Understanding these agent architectures is now essential for AI practitioners, engineers, and decision-makers to select, implement, and optimize the right agent type, which will be a key competitive advantage.
Opinions expressed by DZone contributors are their own.
Comments