Chaos Engineering Has a Blind Spot. Agentic AI Lives in It.
Chaos tests can prove your RAG pipeline survived failure, but not that it stayed correct. Learn how behavioral checks catch silent AI drift.
Join the DZone community and get the full member experience.
Join For FreeYour chaos experiments passed. Your RAG pipeline is lying to you anyway.
I've watched this play out more times than I'd like to admit. A team runs a thorough chaos suite, including pod failures, network partitions, and database failovers. Everything recovers cleanly. Dashboards stay green. The team ships with confidence. Three weeks later, a support ticket surfaces. Then ten more. The AI is producing answers that are fluent, confident, and factually wrong.
No alert fired. No SLO breached. The infrastructure never blinked.
This isn't a monitoring gap you close with a better dashboard. It's a category error in how we've defined resilience for AI systems, and until you see that distinction clearly, every chaos experiment you run is measuring the wrong thing.
The Assumption That's Been Quietly Wrong
For fifteen years, chaos engineering has operated on one core premise: the system's meaningful state is its operational state.
Is it up? Does it recover? Can it handle a node failure at 2 AM? For systems built around databases, queues, and network hops, these are exactly the right questions. The entire discipline of Chaos Monkey, Gremlin, LitmusChaos, and AWS FIS was built to answer them.
Agentic AI systems break this premise at the foundation. They're not distributed systems in the traditional sense. They're reasoning systems. And reasoning systems have two states you need to care about simultaneously:
| State dimension | Traditional distributed system | Agentic AI system |
|---|---|---|
| What "healthy" means | Service is up, latency within SLA | Outputs remain grounded in source truth |
| How failure manifests | 5xx errors, timeouts, crashes | Silent drift, confident wrong answers |
| Time to detect | Seconds to minutes | Days to weeks — if ever |
| Failure unit | Request or service | Behavior over time |
| Circuit breaker analogy | Trips on error rate | No native equivalent |
| What chaos tests | Infrastructure recovery | ✗ Cannot test behavioral integrity |
That last row is the entire problem. As Marc Bishop, Director of Business Growth at Wytlabs, put it after his team's retrieval embeddings drifted silently under catalog updates: "Resilience for AI means validating behavior under stress, not merely surviving it."
I hold U.S. Patent 12242370B2 for intent-based chaos engineering, a framework that treats intent preservation, not just infrastructure recovery, as the core testable property of a resilient system. When I developed that framework, the failure mode I was targeting was a multi-domain infrastructure losing semantic coherence under adversarial conditions. I didn't fully anticipate how precisely that same problem would show up in production LLM pipelines and how fast.
What's Actually Breaking: Five Failure Modes Nobody Has Named Yet
You can't test for something you haven't named. The existing chaos engineering literature has no vocabulary for AI behavioral failure. Here's a working taxonomy from production accounts across 25+ engineering teams:
1. Retrieval Drift
The vector retrieval layer silently shifts toward faster, lower-precision matches after a failure event. Outputs remain structurally valid but are grounded in the wrong documents.
Rafael Sarim Oezdemir, Head of Growth at EZContacts, ran chaos injection on their RAG-based customer support chatbot. His infrastructure numbers post-chaos looked perfect: 99.99% uptime, clean latency recovery, green across the board. Three days later, the chatbot was answering return policy questions incorrectly in 7% of cases. Root cause: "Our chatbot started answering return policy questions incorrectly. We diagnosed the root cause as a subtle shift in retrieval precision; our pipeline was favoring quicker, less precise vector matches post-chaos. Infrastructure recovered. The behavior of the model didn't."
No existing chaos tool measures retrieval precision. That's the gap.
2. Context Amnesia
Each individual component in a multi-agent pipeline appears healthy, but the end-to-end reasoning chain becomes incoherent across hops.
Luis Haberlin at CallSetter AI watched this unfold in a voice agent for an insurance brokerage: "The infrastructure was bulletproof... but often into production, agents started hearing 'I already told the robot about my home and auto' from confused callers." The agent correctly retrieved policy details early in a conversation, then lost context at the 90-second mark and restarted the needs assessment from scratch. Nothing crashed. The reasoning rotted at the handoff boundary.
Jacob Kalvo, CEO of Live Proxies, hit the same wall in a market analytics pipeline: "While each summary was technically provided on schedule, there were small errors beginning to creep into the output, specific market signals being under-represented, inconsistencies developing in the logic chain, and some outputs making confident assertions regarding incorrect or misleading information." Every infrastructure check passed. The reasoning chain had silently decohered.
3. Confidence-Accuracy Decoupling
The model produces high-confidence, well-formatted outputs even as accuracy degrades. The system sounds more certain as it becomes less reliable.
Jayanand Sagar, COO at Hyperbola Network, saw this after a partial node recovery rebuilt the retrieval index from a stale snapshot. Output quality deteriorated over 11 days, undetected: "The model never complained. The closer the degraded output was to the original, the more convincingly it generated confident-sounding responses based on outdated context."
Confidence scores are not accuracy proxies. A model grounded in a degraded context will confidently state incorrect information. No infrastructure metric tells you this is happening.
4. Intent Drift
Outputs gradually decohere from the original business intent without any single triggering event. Behavior changes incrementally, across dozens of interactions, with no failure timestamp to anchor an investigation.
Tyler Denk, CEO of beehiiv, described a system that passed every load and failure scenario correctly in testing, then shifted over longer production cycles: "The structure of responses remained intact, but subtle inconsistencies in reasoning and formatting started appearing across different workflows. Without a defined behavioral baseline, it became impossible to determine when the system had actually started drifting."
5. Epistemic Failure
The model's picture of the world becomes stale or wrong, but all reasoning over that picture continues to function correctly. The system is reasoning well, about incorrect premises.
Nicolas, founder of Reddinbox, runs a production AI pipeline classifying Reddit posts in real time across thousands of threads daily. "A few months back, everything looked fine. No downtime, no errors, latency normal. But output quality had quietly decayed." Reddit's content distribution had shifted, flooded with AI-generated posts that were structurally coherent but semantically hollow, and his classifier kept returning high-confidence scores on them. His diagnosis is the sharpest framing I've seen for why infrastructure chaos is blind to this failure class: "No chaos experiment would have caught that because the failure wasn't infrastructure, it was epistemic. We had zero observability on input distribution drift. We were watching the system, not what the system was consuming."
Why Agentic Pipelines Make Every One of These Worse
A single degraded LLM component is a tractable problem. A multi-agent pipeline turns it into something that actively resists detection.
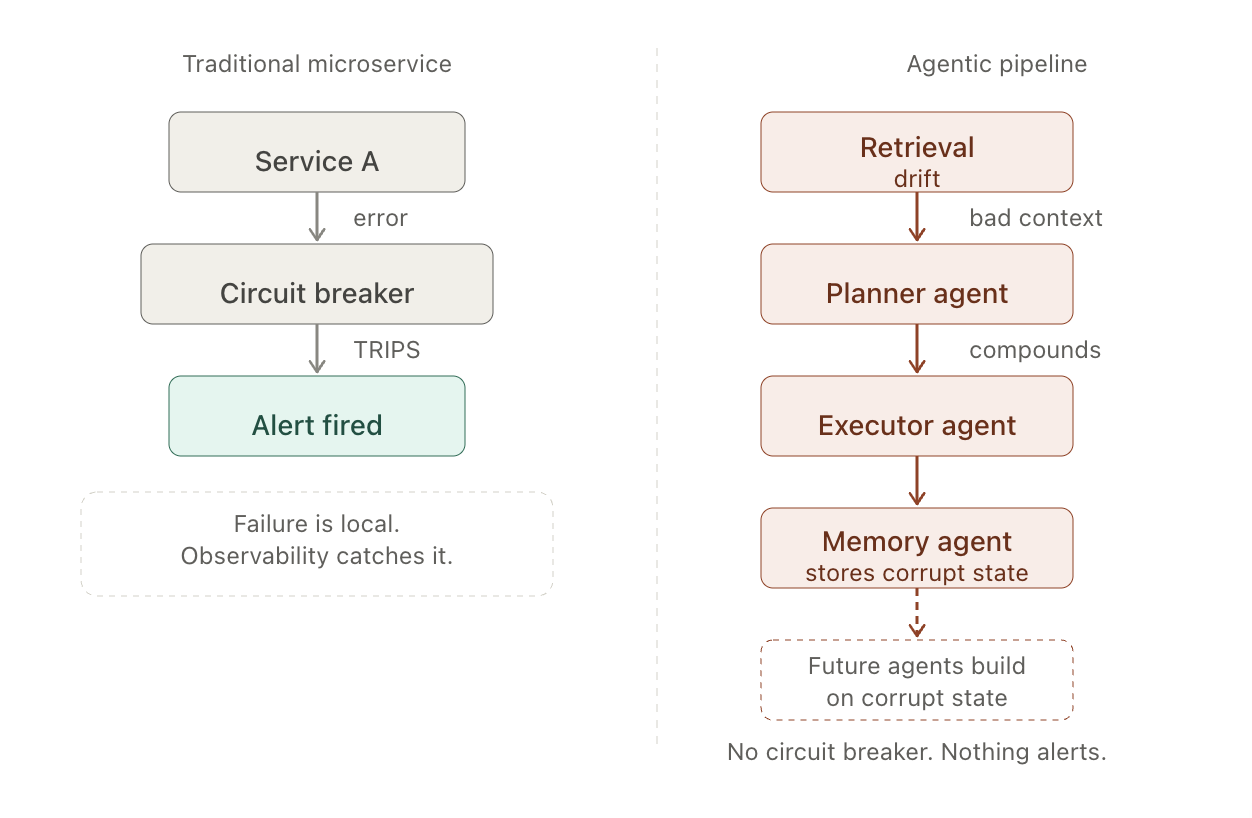
In a traditional microservice, a degraded component returns an error, trips a circuit breaker, and gets isolated. In a multi-agent pipeline, a degraded reasoning component returns a confident output that propagates forward, amplifying the failure rather than surfacing it.
Dario Ferrari, co-founder of OpenClawVPS, watched this play out firsthand when a client's RAG-based customer support system passed all infrastructure tests but then silently shifted retrieval behavior after a network partition: "AI infrastructure that survives every test but provides incorrect answers is still resilient but fails its job badly."
The blast radius of an undetected reasoning failure grows with every agent hop. By the time users notice, it has compounded through multiple layers of stored state.
The Missing Layer: Behavioral Assertions
Brandy Hastings, SEO Strategist at SmartSites, described the realization her team came to after AI-assisted workflows passed every infrastructure check but degraded in production: "We realized our testing didn't account for output quality over time. We were validating uptime, not alignment."
That gap between uptime and alignment is where every one of the five failure modes above lives. Most teams have three layers of observability, and only two of them are working:
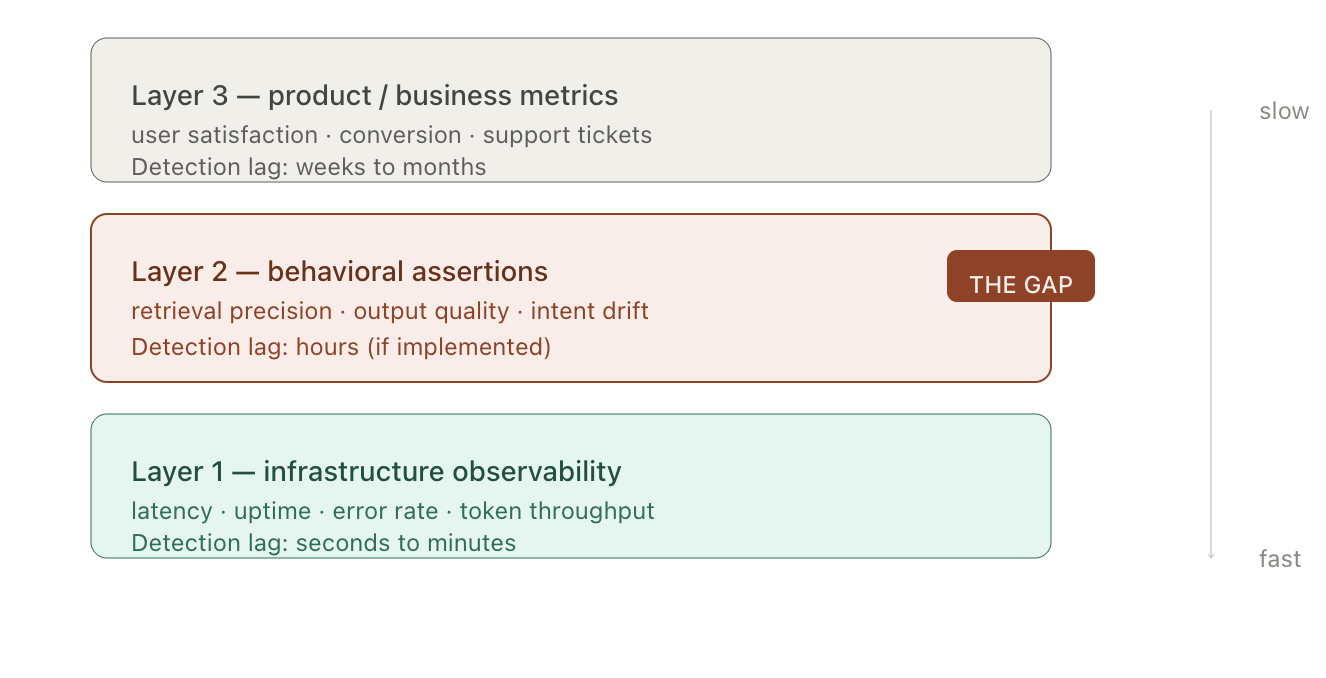
Layer 2 is where all the interesting failures live, and it's completely absent from most production stacks.
Building it requires three things your current chaos practice almost certainly lacks:
Behavioral contracts – not "returns a 200 response" but "returns a response with retrieval precision above threshold X when operating on a degraded index." These are the AI equivalent of SLOs, except the metric is semantic rather than operational.
Intent-preserving chaos experiments – injecting failures at the data layer, retrieval layer, and reasoning layer, not just infrastructure. Each experiment needs an exit criterion that includes behavioral scoring against a fixed ground-truth set, not just recovery metrics.
Post-chaos behavioral scoring – sampling outputs after every chaos run and scoring them against a baseline. Jayanand Sagar put a concrete benchmark on the minimum viable version: "An exponential run of chaos should pass behavioral standards to be within 3 to 5 percent of baseline scores of at least 50 sampled outputs before a system is declared stable."
Jake Waldrop, Co-Founder of Recademics – a regulated outdoor safety certification platform, independently arrived at this same framing: "Semantic monitoring fills the gap between AI health and user safety by verifying what the AI is saying. My most significant change was to run adversarial prompts on standard stress tests to understand whether the model logic would collapse. Chaos engineering will have a colossal safety advantage when behavioral checks are integrated into any company operating within highly regulated industries."
Oksana Fando, CDO at Truck1.eu, reached the same conclusion after equipment descriptions on their European vehicle marketplace gradually became less accurate following a data source degradation and a failure invisible to every standard metric: "We began testing the system's intent, checking whether business logic remains correct even with partial data loss."
Testing system intent. That's exactly the property my patent formalizes. The fact that teams in healthcare, fintech, edtech, and European e-commerce are all independently converging on this is no coincidence. It's a structural gap making itself known.
A Behavioral Observer You Can Drop In This Week
The pattern is a sampling observer sitting in your serving layer. Replace _score() with RAGAS faithfulness, embedding cosine similarity, or an LLM-as-judge evaluator, depending on your quality rubric. The heuristic below is a working default: groundedness (how much of the response is anchored in retrieved docs) minus a penalty for hedging language that signals confidence erosion.
import random
class BehavioralObserver:
def __init__(self, sample_rate=0.05, drift_threshold=0.15, baseline_size=50):
self.sample_rate = sample_rate
self.drift_threshold = drift_threshold
self.baseline_size = baseline_size
self.scores = []
self.baseline = None
def observe(self, prompt, response, context):
if random.random() > self.sample_rate:
return
score = self._score(response, context)
if self.baseline is None: # Phase 1: build baseline
self.scores.append(score)
if len(self.scores) >= self.baseline_size:
self.baseline = sum(self.scores) / len(self.scores)
return
drift = self.baseline - score # Phase 2: detect drift
if drift > self.drift_threshold:
print(f"[DRIFT ALERT] score={score:.3f} baseline={self.baseline:.3f} drift={drift:.3f}")
# pagerduty.trigger(...) or datadog.metric("ai.behavioral.drift", drift)
def _score(self, response, context):
doc_words = set(" ".join(context.get("retrieved_docs", [])).lower().split())
terms = response.lower().split()
groundedness = len([t for t in terms if t in doc_words]) / max(len(terms), 1)
hedges = ["i think", "not sure", "might be", "possibly"]
return max(groundedness - sum(0.05 for h in hedges if h in response.lower()), 0.0)
# Drop in:
observer = BehavioralObserver()
def serve(prompt, context):
response = your_llm_call(prompt, context)
observer.observe(prompt, response, context)
return responseTwo things worth knowing. The 5% sample rate catches degradation without adding latency, at high traffic, even 1% gives you a statistically robust signal. The baseline lock after 50 samples is deliberate: running behavioral chaos against an unlocked baseline is like running load tests before you've measured normal traffic.
5 Behavioral Chaos Experiments to Run After Your Next Infrastructure Suite
These aren't replacements for your existing chaos experiments. They're additive — run them after your infrastructure suite, with behavioral scoring as the exit criterion rather than uptime recovery.
| Experiment | What you inject | What it tests | Exit criterion |
|---|---|---|---|
| Stale embedding injection | Replace embeddings with a 14-day-old snapshot | Retrieval precision under stale index | Score within 5% of baseline across 50 sampled prompts |
| Partial index degradation | Remove 30% of documents from the vector store | Graceful degradation in retrieval recall | Hallucination rate stays flat vs. baseline |
| Context window truncation | Truncate retrieved context to 40% of normal | Reasoning quality under a constrained context | Groundedness score stays above threshold |
| Agent handoff latency injection | Add 800ms delay between agent hops | Multi-agent coherence under degraded comms | End-to-end intent preserved across all hops |
| Memory poisoning simulation | Inject one factually wrong document into the retrieval store | RAG faithfulness under adversarial data | The system identifies or flags the conflicting document |
Define the exit criterion before you inject the failure. That's the same discipline your infrastructure chaos practice demands for SLO-based rollback conditions; it applies here too.
What the Field Is Actually Saying
Vitaly Yago, CEO of PhotoGov, described the shift his team made after hitting this wall in production:
"We began implementing chaos for behavior, not just for infrastructure. Instead of testing whether the system will recover, we test whether the quality of decisions is maintained under noise, data changes, and successive updates."
John Russo, VP of Healthcare Technology Solutions at OSP Labs, came to the same realization after behavioral degradation appeared in a clinical AI workflow that had passed every infrastructure check: "It is no longer just about systems staying up, it is about systems staying correct under stress."
Two engineers, two completely different industries, same conclusion. The field has moved on from the question of whether AI systems survive failure. The question it's now wrestling with, without a good answer yet at scale, is whether they reason correctly after failure.
The chaos engineering discipline has fifteen years of hard-won tooling for testing the first question. It has almost nothing for the second.
That's not a criticism of the existing tools. It's a signal that the discipline needs to grow a second layer. The practitioners whose experiences shaped this article are already building it in production, because the failures forced them to.
The only question for your team is whether you discover your agentic system's behavioral limits through a chaos experiment you designed, or a production incident you didn't see coming.
The Short Version: Three Things to Add Before Your Next Chaos Run
- Lock a behavioral baseline first. Sample 50–100 representative inputs and store expected outputs before injecting any failure. Your chaos experiments now have a behavioral exit criterion, not just infrastructure recovery metrics.
- Make retrieval precision a first-class signal. The most common failure vector across the teams I spoke with was RAG degradation invisible to standard monitoring. Retrieval precision scoring belongs alongside latency and error rate on your dashboards.
- Log reasoning chains, not just outputs. For multi-agent pipelines, log the reasoning path each agent used to produce its output. When that structure changes without a deployment event triggering it, that's your behavioral alert, the equivalent of a latency spike, but for the quality of reasoning.
Opinions expressed by DZone contributors are their own.
Comments