Kubernetes Assimilation: Persistence Is Futile
Persistence alone is not enough to service a Kubernetes environment well. Read this article to learn more about solutions without compromises.
Join the DZone community and get the full member experience.
Join For FreeOutline
- Why stateful applications are gaining ground in the container space
- The types of stateful applications that benefit from Kubernetes orchestration
- How you can deploy high performance, low latency block storage in Kubernetes environments and get great performance, increased reliability, and lower cost
- Containers are moving from a stateless micro-service-oriented compute infrastructure to a stateful one, requiring persistent storage.
Why Stateful Applications Are Gaining Ground in the Container Space
Kubernetes seems to be assimilating everything. It started out just being for microservices, especially stateless ones, but it's really taking over all sorts of applications. What’s beneficial about Kubernetes is its ability to scale services up, to scale down, and to assure portability. So, to riff on the Borg from Star Trek, “persistence is futile!”
Kubernetes was designed for stateless applications; the functionality of which is that they don't have to save their state when they go down. Stateful applications do need to save their state on a regular basis, and when they go down, they use that state to start up again. This applies to modern cloud-native applications, such as databases (DBs). Functionally speaking the benefits of databases are scalability, portability, and the ability to extract the DB from the underlying hardware. So, functionally DBs are aligned very well with the Kubernetes philosophy. And the notion of pods, of deploying services together is powerful especially with today's cloud-native applications which also share the same functionality philosophies: to scale by adding instances, hardware portability, and the flexibility to move applications. So, it seems only natural to deploy applications that are stateful under Kubernetes and get the same benefits that you have for stateless applications.
Types of Stateful Applications That Benefit From Kubernetes Orchestration
Applications that can benefit from Kubernetes orchestration are modern cloud-native applications that are made to scale, support web-based applications, or services-oriented architectures. These can be traditional databases, SQL databases such as MySQL and Postgres. These are essentially single instance databases; they can replicate but they don't necessarily scale out like some other NoSQL databases or other cluster databases. Other types of databases are NoSQL databases such as Cassandra and MongoDB, a document-based database. Other types are in-memory databases such as Redis and Apache Ignite or different processing frameworks, such as Apache Spark or Apache Kafka.
And for all these applications when deployed on bare metal, it’s recommended to have local flash at minimum for best performance, and NVMe is what you really want to use for the lowest levels of latency and highest levels of bandwidth. These applications all use low latency. Occasionally they can use high bandwidth for either reads or writes. Why does an in-memory database need low latency storage? The answer is because not everything always fits in memory. Anytime you get a memory miss you're going to go to storage and so when you do that, you want that to be as fast as possible. Also, when you start up and shut down, they're going to read in lots of data and if they do a shutdown, they are going to save their state. When saving their state, they're going to dump the contents of RAM to a storage device. The recommendation is that it is local.
So, what do you do then, in a Kubernetes environment? There is a local persistent volume functionality that was introduced in Kubernetes 1.14, and this just means that you can have persistent storage on Kubernetes using the Kubernetes server local drive. You could have SSDs installed in each one of the Kubernetes application servers running various loads.
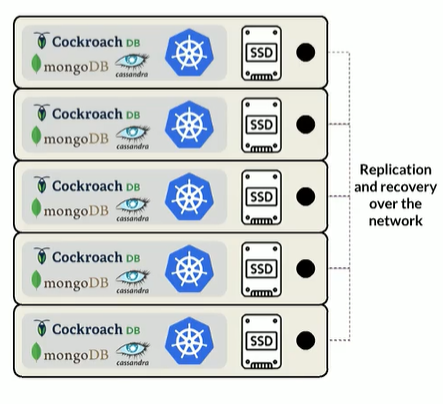
Figure 1
The persistent storage is in the pod and the physical server, which delivers great performance. Otherwise, the applications can shut down or start up, and you'll have great performance. However, this architecture breaks the philosophy of Kubernetes and the applications. When you use this local persistent volume functionality, Kubernetes is going to only schedule the given pod that's using this persistent storage to that one physical server. So, you've lost application portability, and you can't “move” off that physical server. You’ve also introduced the problem of flash allocation, especially if you don't put them in every single server. You must start tracking which servers have flash and which don't.
The architecture will result in poor flash utilization. You could add an 8TB drive in every single Kubernetes server, but you may only need it part of the time, which results in very poor flash utilization. If you add local flash in every application server or Kubernetes server, you're going to end up with 50 to 85% of that flash being wasted. Capacity utilization often ranges only in the 25% range or as low as 15% utilization. It's very common for single application servers to only need 150,000 - 300,000 IOPs, but the single NVMe drives can supply between 600,000 – 800,000 IOPs, underutilizing the performance of the drive.
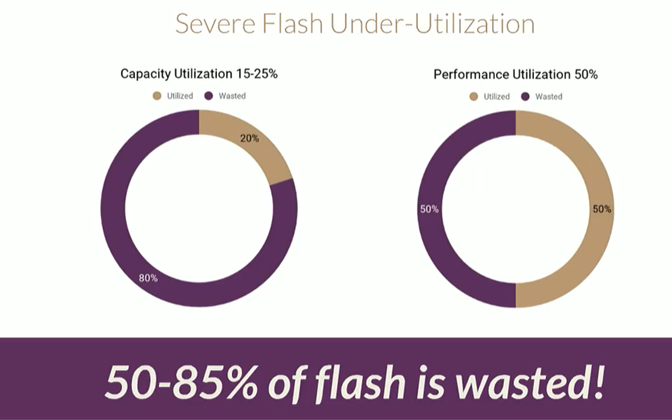
Figure 2
When your underutilizing capacity and performance across the fleet, the tendency is to want to share. It is very common when using Kubernetes to use a persistent storage solution that comes over the network. Many companies have CSI drivers readily available and there are many persistent storage solutions. You may want to match your scalable Kubernetes orchestration environment with a scalable storage environment like Ceph and deploy it inside Kubernetes containers. iSCSI also is popular and works fine. There are also various file system-based products for Kubernetes environments. as well as open source and propriety block-based products. However, it is extremely rare for them to perform at the same levels of local flash, and the ones that do tend to either not offer any data services or data protection. Even if they do, then they might be proprietary hardware, or worse, they are proprietary drivers. Proprietary block drivers are often tied to the kernel, or they require RDMA networking. This means you may have RDMA NICs in some hosts and not in others, which really starts to break the simplicity and portability philosophy of Kubernetes clusters.
Containers are moving from a stateless microservice-oriented compute infrastructure to a stateful one, requiring persistent storage.
So why is the title of this blog, “Persistence Is Futile?” Because persistence by itself is not enough to service a Kubernetes environment well. With all the solutions today, why is persistence futile? Because choosing persistence today with the existing solutions means you're making severe compromises. And what you really want to do is not have to compromise on your storage solution. When using local persistent volumes, you're going to get the performance, but you lose a lot of the benefits of Kubernetes orchestration; specifically, the hardware portability and the flexibility to move applications. Using a network persistent storage solution is also not recommended as:
- They are too slow. Performance is in the millisecond range, and very few are below 1000 microseconds.
- They break with the Kubernetes philosophies.
- They might have proprietary block drivers which means it makes it very difficult to do upgrades.
- They might require special NICs, meaning some of your hardware fleet is different than others.
- You may have to make special changes to your switches and the way you do your network management.
- Some have no data services, so they require the application to do all their own data production, and, as mentioned, you may choose to do single instance databases such as MySQL or Postgres. Maybe you don't want to use replication because of slow down, so you'd like the storage to be able to provide the protection for you.
There are solutions where you don’t have to make compromises between having centralized storage but slow performance, or having local persistent volumes and be really fast but lose a lot of the benefits of Kubernetes.
Published at DZone with permission of Carol Platz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments