Revolutionizing KYC: Leveraging AI/ML for Regulatory Compliance
Integrating AI and ML into KYC processes significantly enhances regulatory compliance, operational efficiency, and customer satisfaction.
Join the DZone community and get the full member experience.
Join For FreeKnow Your Customer (KYC) embodies a sophisticated and proactive compliance framework strategically adopted by financial institutions to methodically scrutinize and validate client identities, transactional behaviors, and risk exposures. Beyond mere regulatory formality, KYC constitutes an integral pillar for institutional integrity, meticulously architected to mitigate systemic vulnerabilities such as identity fraud, illicit financial flows, and potential terrorist financing.
Fundamentally, KYC represents an intersection of regulatory rigor and advanced analytical methodologies. It encompasses a structured process of gathering detailed identity evidence—ranging from government-issued documentation to transactional patterns—and applying intricate risk-scoring models to ascertain and continuously reassess customer authenticity, credibility, and behavioral consistency.
In contemporary settings, KYC transcends static checks; it integrates predictive analytics, leveraging machine learning algorithms, natural language processing, and behavioral analytics to dynamically pinpoint anomalies and preempt compliance breaches. This enhanced KYC paradigm facilitates an adaptive, anticipatory compliance environment, enabling financial institutions to maintain robust operational integrity while concurrently delivering seamless customer experiences amidst increasingly complex regulatory landscapes.
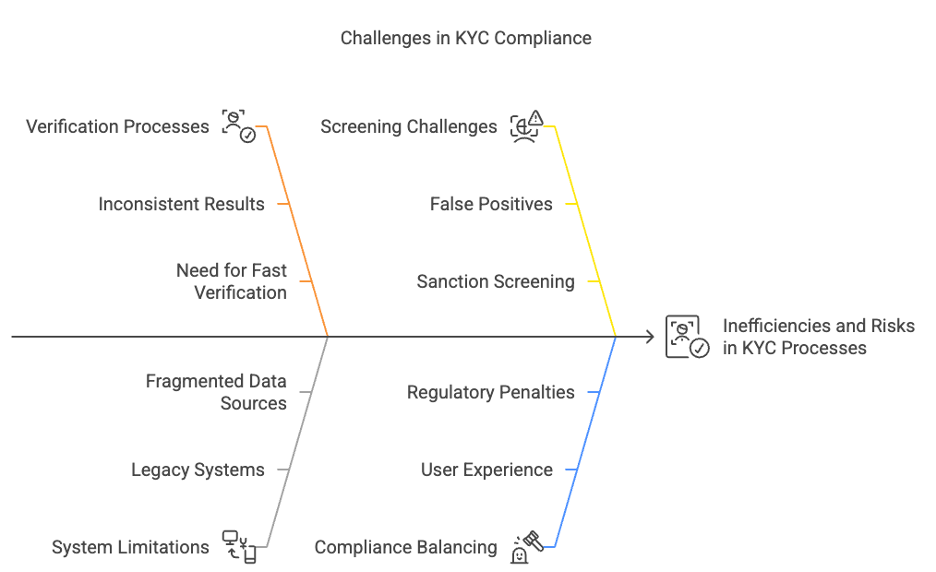
The Pain Points of Traditional KYC
- Manual document verification leads to inconsistent results.
- Legacy systems struggle to keep up with changing regulations.
- High false-positive rates in sanction screening.
- Fragmented data sources result in customer onboarding delays.
- Balancing compliance with user experience
- Risk of financial crimes and regulatory penalties
- Complexity and cost of compliance
- Need for fast and accurate verification
- Maintaining security while enhancing user experience
How AI/ML Transforms KYC
Document Verification with OCR + NLP: AI-driven OCR can extract structured data from identity documents with high precision. NLP models validate data contextually to flag inconsistencies.
Facial Recognition & Liveness Detection: ML models verify identities via face-matching and detect spoofing attempts using video analytics.
Dynamic Risk Scoring: ML algorithms assign risk scores by analyzing user behavior, location, device metadata, and transactional patterns.
Continuous Monitoring: Real-time anomaly detection enables institutions to move from point-in-time KYC to perpetual KYC (pKYC).
In this article, we will focus on Document verification with OCR and NLP.
Overall Architecture
OCR Phase
- Use
pytesseractoreasyocrto extract text. - Structure the extracted data (name, DOB, document number, etc.)
- Support languages like French, Spanish, etc. using
pytesseract’s lang param
NLP Validation Phase
- Use
spaCyor rule-based heuristics to validate:- Name formatting
- Date of birth (e.g., not in future)
- Expiry dates
- Field alignment across multiple mentions
- Driver’s License, Passport, National ID, etc.
Fuzzy Matching for Field Labels
- Use
fuzzywuzzyorrapidfuzzto match misspelled/misaligned field labels.
Inconsistency Flagging
- Flag missing or suspicious fields (e.g., "Name: 123").
- Return structured verification report.
Design Strategy
| Feature | Tool/Method |
|
Field label matching |
fuzzywuzzy (extractOne) |
|
Multilingual OCR |
pytesseract.image_to_string(image, lang='eng+fra') |
|
Doc type detection |
Simple heuristics based on content keywords |
|
Field flexibility |
Map known variants of field labels to unified field names |
Architectural Considerations for AI-Driven KYC
- Data Ingestion Layer: Ingest structured and unstructured data (images, PDFs, APIs) securely and at scale.
- AI/ML Pipeline: Implement modular pipelines for OCR, facial matching, and classification models. Consider using frameworks like TensorFlow, PyTorch, and Apache Beam.
- Feature Store: Maintain a centralized feature store to ensure model consistency across training and inference.
- Model Governance: Integrate explainability (XAI) and model monitoring tools to comply with regulatory mandates.
- Integration Layer: Expose KYC services via REST APIs or event-driven interfaces using Kafka or gRPC.
Implementation
- Add support for multilingual OCR.
- Build a flexible field extractor using fuzzy label matching.
- Extend regex rules to be more inclusive for different formats
# Multilingual Document Verification with OCR and Fuzzy Matching
import re
import difflib
from datetime import datetime
from PIL import Image
import pytesseract
# Define multilingual field labels
FIELD_SYNONYMS = {
"name": ["name", "full name", "nom", "nombre"],
"dob": ["date of birth", "dob", "birth date", "naissance", "fecha de nacimiento"],
"document_number": ["document number", "doc no", "numéro de document", "número de documento"],
"expiry_date": ["expiry date", "expiration", "date d'expiration", "fecha de expiración"]
}
# Normalize and validate structured data
def validate_structured_data(data):
issues = []
if data["name"]:
name_parts = data["name"].split()
if len(name_parts) < 2 or not all(part.isalpha() for part in name_parts):
issues.append("Name format might be incorrect.")
else:
issues.append("Name not found.")
if data["dob"]:
try:
dob = datetime.strptime(data["dob"], "%d/%m/%Y")
if dob > datetime.now():
issues.append("DOB is in the future.")
except ValueError:
issues.append("DOB format is invalid.")
else:
issues.append("DOB not found.")
if data["expiry_date"]:
try:
expiry = datetime.strptime(data["expiry_date"], "%d/%m/%Y")
if expiry < datetime.now():
issues.append("Document is expired.")
except ValueError:
issues.append("Expiry date format is invalid.")
else:
issues.append("Expiry date not found.")
if data["document_number"]:
if not re.fullmatch(r'[A-Z0-9]+', data["document_number"].upper()):
issues.append("Document number format is invalid.")
else:
issues.append("Document number not found.")
return issues
# Fuzzy matching for label recognition
def fuzzy_extract_fields(text):
structured_data = {
"name": None,
"dob": None,
"document_number": None,
"expiry_date": None
}
lines = text.lower().splitlines()
reverse_label_map = {label: key for key, labels in FIELD_SYNONYMS.items() for label in labels}
for line in lines:
tokens = line.strip().split()
for n in range(4, 0, -1):
for i in range(len(tokens) - n + 1):
phrase = ' '.join(tokens[i:i + n])
match = difflib.get_close_matches(phrase, reverse_label_map.keys(), n=1, cutoff=0.8)
if match:
field_key = reverse_label_map[match[0]]
value = line.split(':')[-1].strip()
if not structured_data[field_key]:
structured_data[field_key] = value
break
# Fallback: pattern-based date and document number inference
date_matches = re.findall(r'\d{2}/\d{2}/\d{4}', text)
if date_matches:
if not structured_data["dob"]:
structured_data["dob"] = date_matches[0]
if len(date_matches) > 1 and not structured_data["expiry_date"]:
structured_data["expiry_date"] = date_matches[1]
doc_matches = re.findall(r'\b[A-Z]{2}\d{6,}\b', text.upper())
if doc_matches and not structured_data["document_number"]:
structured_data["document_number"] = doc_matches[0].upper()
return structured_data
# OCR function with multilingual support
def extract_text_multilang(image_path, languages='eng+fra+spa'):
image = Image.open(image_path)
text = pytesseract.image_to_string(image, lang=languages)
return text
# Main pipeline
def document_verification_pipeline(image_path):
raw_text = extract_text_multilang(image_path)
structured_data = fuzzy_extract_fields(raw_text)
structured_data["document_number"] = structured_data["document_number"].upper() if structured_data["document_number"] else None
validation_issues = validate_structured_data(structured_data)
return {
"extracted_data": structured_data,
"issues": validation_issues,
"raw_text": raw_text
}
AI Challenges and Consideration
- Data Privacy: Ensuring rigorous adherence to global and regional data protection standards, such as the General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), and jurisdiction-specific privacy mandates, is paramount. Effective AI deployment necessitates meticulous management of sensitive customer data, including anonymization, encryption, and secure data handling practices. Institutions must incorporate privacy-preserving mechanisms, including differential privacy and federated learning, alongside comprehensive data governance frameworks to proactively mitigate compliance risks and foster customer trust
- Model Bias: AI systems inherently risk perpetuating and amplifying societal and operational biases due to skewed datasets or algorithmic limitations. To address this, institutions must commit to systematic bias detection through regular algorithmic audits, deploying advanced fairness-aware machine learning techniques, explainability tools like SHAP values, and fairness frameworks. Additionally, continuous validation processes involving diverse and representative data are critical for minimizing unintended bias, thus ensuring equitable and transparent AI-driven decision-making.
- Scalability: As AI solutions scale from pilot phases to enterprise-wide deployment, maintaining optimal performance in terms of throughput, latency, and resilience becomes increasingly challenging. Robust architectural considerations—such as microservices design, containerization, and distributed computing platforms—are essential. Moreover, leveraging high-performance computing infrastructures and real-time analytics ensures that AI systems deliver consistent performance under growing data volumes and demanding operational conditions without compromising responsiveness or reliability.
- Change Management: Successfully integrating AI into existing business processes requires comprehensive organizational alignment and proactive change management strategies. Cross-functional collaboration between technical teams, compliance specialists, business stakeholders, and senior leadership is indispensable to ensure holistic understanding, stakeholder buy-in, and smooth transition. Structured training programs, clear communication of AI’s strategic benefits, and fostering an AI-driven organizational culture facilitate responsible adoption and sustainable utilization of artificial intelligence technologies
Conclusion
Integrating AI and Machine Learning into KYC is changing the game for financial compliance, offering smarter, more adaptive ways to meet regulatory demands. As demonstrated through practical implementations and empirical case studies, AI-driven solutions not only enhance operational efficiency and accuracy but also significantly elevate compliance standards and customer experience. In an era characterized by heightened regulatory scrutiny and growing customer expectations, the adoption of AI-enabled KYC systems is indispensable for institutions aiming to achieve both regulatory excellence and competitive differentiation. Institutions that proactively embrace and strategically deploy these advanced technologies will secure a critical advantage, ensuring robust compliance, fostering trust, and driving sustained growth in the dynamic global financial landscape.
Opinions expressed by DZone contributors are their own.
Comments