Lakehouse: Manus? MCP? Let’s Talk About Lakehouse and AI
This is the second article in the “Lakehouse: What’s the Big Deal?” series, where I will periodically discuss Lakehouse. Your comments and discussions are welcome.
Join the DZone community and get the full member experience.
Join For FreeSince OpenAI launched ChatGPT in late 2022, AI has become an unavoidable topic in every field. Many companies have even transformed into AI companies overnight. The data analytics domain is no exception — Databricks, Snowflake, and Elasticsearch have all redefined themselves as AI data platforms or AI-ready data analytics and search products. Setting aside the “hype”, in today’s article, we’ll explore what relationship actually exists between Lakehouse and AI.
Before diving into this topic, let’s start with a simple example demonstrating the connection between data and AI.
First Experience With Apache Doris MCP Server
What Is MCP?
Model Context Protocol (MCP) is a standard for how applications provide context to large language models (LLMs), proposed by Anthropic in late 2024. In MCP’s official introduction, this protocol is compared to a USB-C interface for AI applications, making it convenient for AI models to connect with different data sources and tools.
MCP adopts a client-server architecture with the following core concepts:
- MCP client. Client programs that access MCP servers, such as Cursor, Claude Desktop, IDEs, etc.
- MCP server. A lightweight program that provides specific functional interfaces through the standardized MCP protocol.
- Local data sources and remote services. Resources that can be accessed by MCP servers, such as local files, web links, remote services, etc.
The following diagram shows the relationship between these concepts: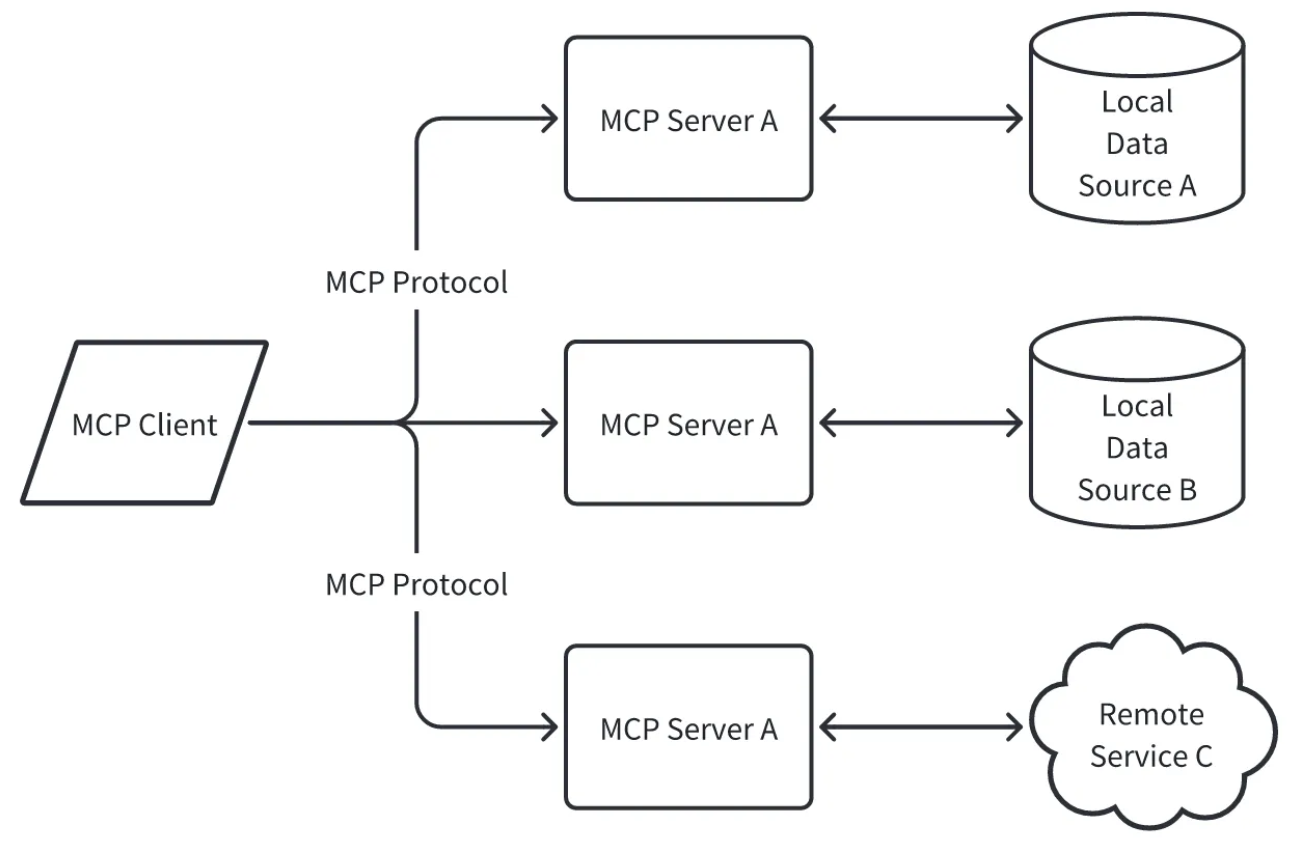
Overall, MCP provides a scalable interface between large models and data sources through a standardized communication protocol, allowing users to easily implement different AI agents to collaborate. The recently viral Manus AI is essentially unleashing the power of large models through the packaging and productization of AI Agents.
As of February 2025, more than 10 tools, including Claude Desktop, have integrated MCP, with community contributions exceeding 1,000 MCP servers covering multiple domains. Gartner predicts that by 2026, 30% of enterprise AI projects will adopt standardized protocols similar to MCP.
Apache Doris + MCP
Apache Doris is an open-source analytical database product. Apache Doris MCP Server is an MCP server that can access Doris data services. Through Apache Doris MCP Server, we can allow LLM to directly access and explore data stored in Doris. Let me demonstrate this briefly.
Let’s assume we have already installed the latest version of Cursor IDE locally and have an accessible Doris cluster. Additionally, we need a uv runtime environment locally.
The complete code can be found at: https://github.com/morningman/mcp-doris
1. Adding Doris MCP Server
Open the Cursor Settings page, click on the “MCP” tab, and click “Add new MCP server.”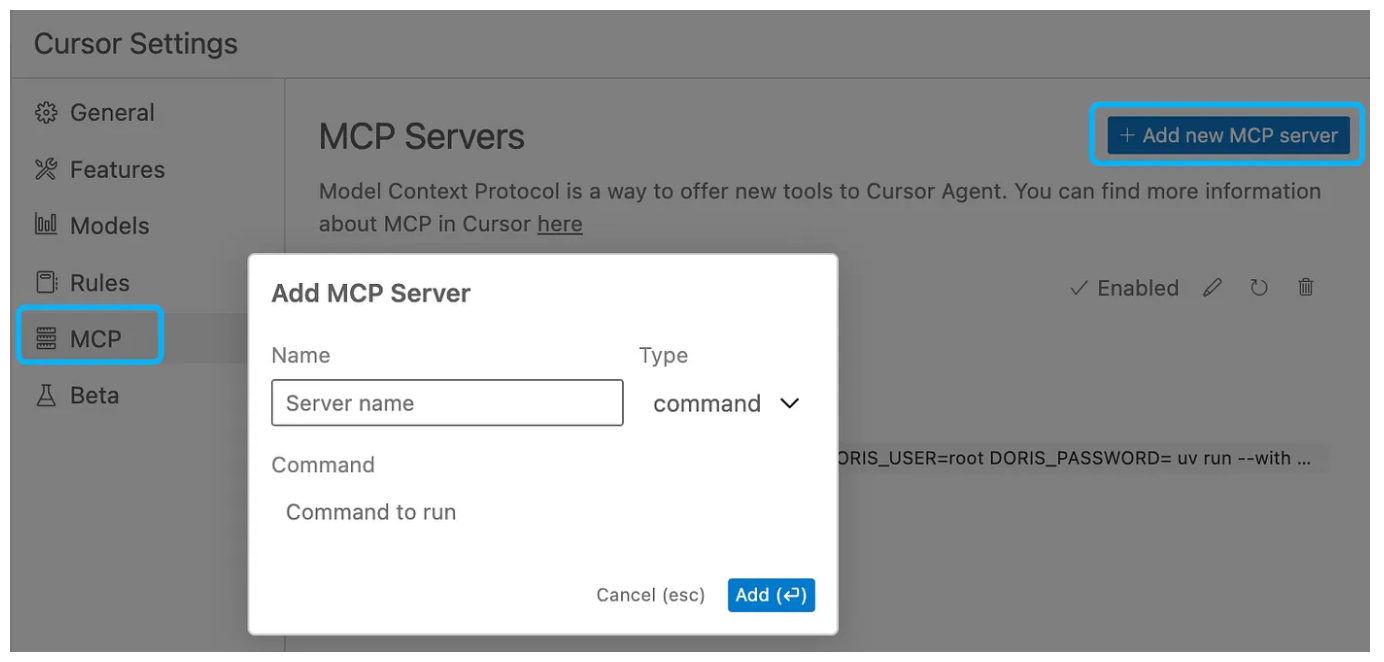
In the opened dialog, fill in the following information:
- Name: The name of the MCP server, which can be filled in arbitrarily.
- Type: Select “command.”
- Command: Fill in the following content:
env DORIS_HOST=<doris-host> DORIS_PORT=<query-port> DORIS_USER=<doris-user> DORIS_PASSWORD=<doris-pwd> uv run --with mcp-doris --python 3.13 mcp-dorisThen, click “Add” to add an Apache Doris MCP Server. A small green dot indicates that the MCP server is running normally.
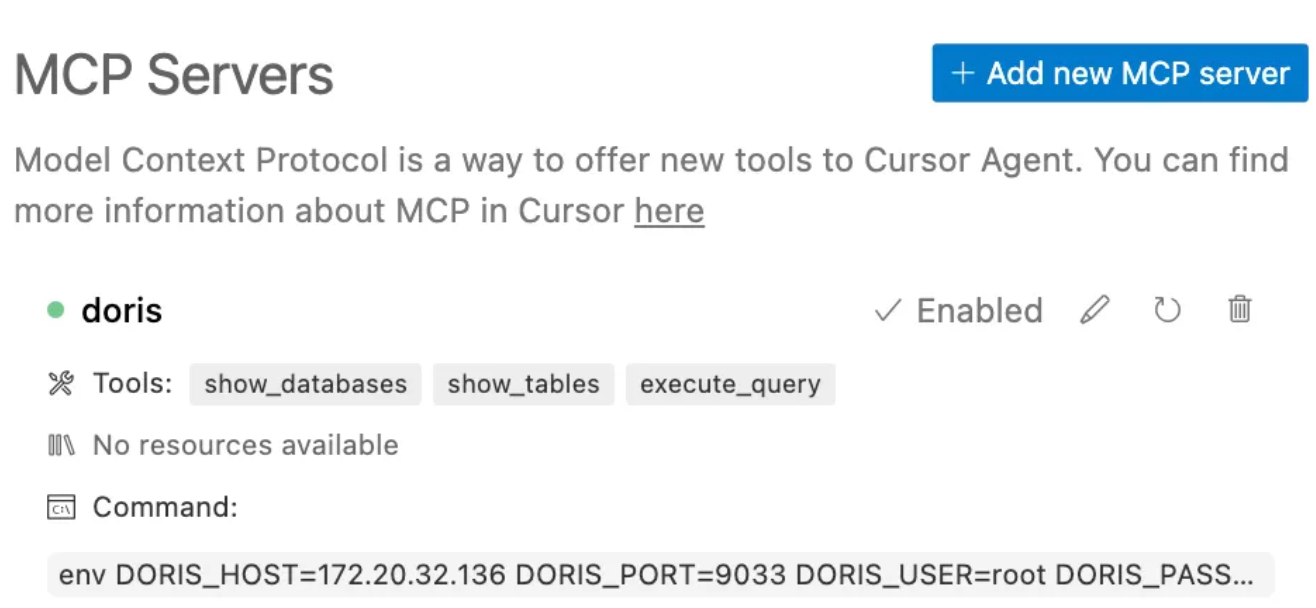
2. Interacting With Doris MCP Server
The currently implemented Doris MCP Server is relatively simple, only implementing the ability to list databases, tables, and execute query SQL. Now we can open Cursor’s “Chat” page and switch to “Agent” mode.
Note that if you’re using an older version of Cursor, you’ll need to open the “Composer” page to interact with the MCP server.
Next, we can interact with the Doris database using natural language.
In the video demonstration, I asked Cursor to list the databases in Doris and analyze the contents of the TPCH database, and finally, I used natural language to ask a question about the TPCH dataset:
In TPCH database, find which supplier should be selected to place an order for a given part in a given region.
Cursor, through multiple interactions with the MCP server, ultimately provided and executed an SQL example:
SELECT
s.s_suppkey,
s.s_name,
s.s_address,
s.s_phone,
p.p_partkey,
p.p_name,
ps.ps_supplycost,
ps.ps_availqty,
n.n_name AS nation,
r.r_name AS region
FROM
tpch.supplier s
JOIN tpch.nation n ON s.s_nationkey = n.n_nationkey
JOIN tpch.region r ON n.n_regionkey = r.r_regionkey
JOIN tpch.partsupp ps ON s.s_suppkey = ps.ps_suppkey
JOIN tpch.part p ON ps.ps_partkey = p.p_partkey
WHERE
r.r_name = 'REGION_NAME' AND -- Replace with desired region
p.p_partkey = PART_KEY -- Replace with desired part
ORDER BY
ps.ps_supplycost ASC, -- Primary: lowest cost
ps.ps_availqty DESC -- Secondary: highest availability
LIMIT 1;As we can see, through the MCP server, we quickly implemented capabilities similar to ChatBI. Additionally, we can add more MCP servers with different capabilities, and Cursor can simultaneously use these servers’ capabilities to complete complex combined tasks.
We can further enrich the capabilities of the Doris MCP Server by providing interfaces for querying system information to help us diagnose the operation issues of the Doris cluster. We can also allow the MCP server to read database, table, and field comments to better understand the meaning of data in the database and provide more accurate answers.
Lakehouse: What Is the Big Deal?
Returning to our main topic, let’s discuss the relationship between Lakehouse and AI. And why Lakehouse can become the data foundation in the AI era.
Actually, the MCP server example above doesn’t showcase any particular advantages of Lakehouse or analytical databases in this scenario. It seems we could achieve similar capabilities by replacing Doris with MySQL or other systems with data access capabilities. So what exactly are the advantages of Data Lake and data analytics engines like Doris in the AI domain?
Lakehouse in the AI Era
First is the Data Lake. In my previous article, I mentioned two core points: data sharing and diverse workloads and collaboration. It allows different compute engines to work collaboratively on shared data and integrates seamlessly with various tools and platforms. This means that during AI development, data scientists and engineers can conveniently use familiar tools to process data without complex data migration and format conversion, ensuring data consistency and real-time access, driving efficient AI workflow operation.
On the other hand, support for diverse data format storage is also an important factor that enables Data Lake to serve AI scenarios. Beyond tabular data, storage of unstructured data and vector data allows us to confidently meet the data requirements of complex scenarios like Manus, which requires multiple capabilities and data collaboration.
Of course, the widely applied open lake formats such as Iceberg, Paimon, etc., essentially still belong to the structured and semi-structured tabular format category, which is just a part of the entire data lake storage capability. I will discuss how a unified catalog service manages all data on the lake in future series articles.
Next is the data analytics engine. For analytics engines like Apache Doris, on the surface, it seems that from the data era to the AI era, the main functionality they provide hasn’t changed significantly: data analysis through SQL language. However, in the AI era, application scenarios place higher demands on the capabilities of analytics engines:
Higher Performance
From the MCP server demonstration earlier, we can see that when we pose questions to LLM using natural language, the model breaks down the problem into multiple sub-problems to process. With DeepSeek’s popularization of deep thinking capabilities, a complex problem implies a longer chain of thought and more sub-problems.
If readers carefully observe the model’s processing of the problem in the example, they can see that it repeatedly interacts with the MCP Server (or Doris) to eventually arrive at the solution through exploration. Behind a model solving a problem are numerous data interaction actions, even explosive request generation.
Therefore, the response capability of the backend data source directly affects the user experience. Analytics engines like Doris, with their ultra-high performance and concurrent processing capabilities, make these interactive AI scenarios possible with an acceptable user experience.
Richer SQL Expression Capabilities
SQL language provides reliable problem expression capabilities based on relational algebra. From the development trajectory of SQL to NoSQL and back to SQL in the big data field, we can see that SQL remains one of the most important capabilities in the data analytics domain.
On the basis of two-dimensional relational data, through UDFs, we can extend more capabilities, such as the ability to analyze unstructured data or the ability to call LLM to analyze data. The remote UDF provided by Apache Doris further decouples “server-side computing capabilities” and “client-side computing capabilities,” enabling more flexible data analysis functions.
Open Data API or Open Data Format?
In mainstream open data lakehouse architectures, data is typically presented in its openness in the form of Open Data Format. Representative projects include Iceberg, Hudi, Paimon, Delta Lake, etc. These projects usually start from a storage perspective, designing a unified format standard for upstream systems to interface with.
On the other hand, compute engines or data warehouse systems represented by BigQuery and Redshift expose their stored data externally through Open Data API.
The following table lists the differences between these two “Open” forms:
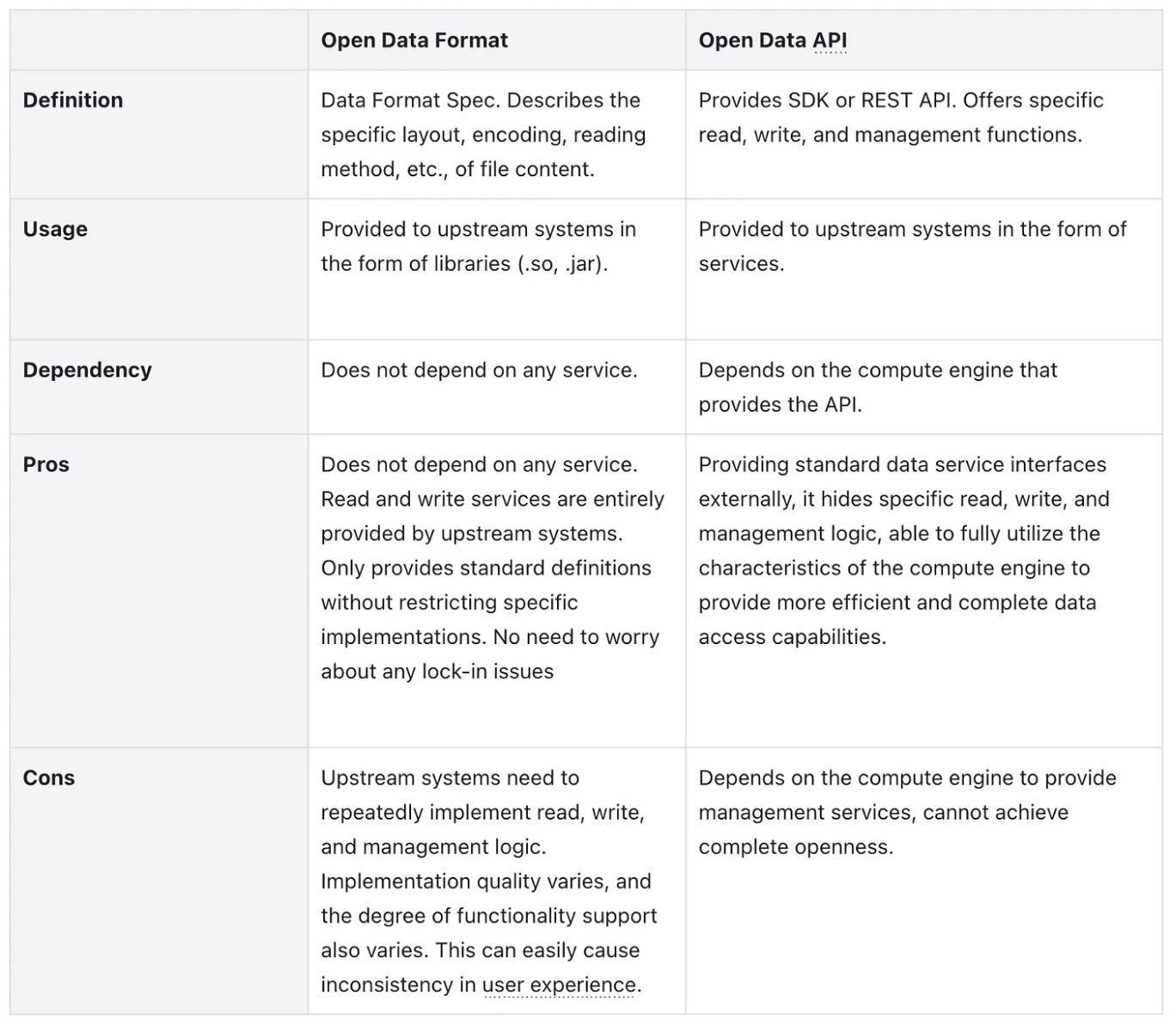
As we can see, in terms of openness, Open Data Format has the edge, while in terms of functional completeness, Open Data API performs better.
Therefore, as a data analytics engine in the AI era, it needs to support both open standards simultaneously to meet the requirements of different scenarios. Apache Doris, as a pioneer in this aspect, not only supports access to mainstream open data formats such as Iceberg, but also provides its own open data API based on Apache Arrow Flight, enabling seamless integration of statistical analysis and model training.
To Be Continued
This article used MCP server + Doris as a starting point to explore how Lakehouse supports AI applications in terms of unity, openness, functionality, and high performance in the AI era. Essentially, AI is born from the results of data analysis and understanding, while AGI produces results by acting on data. Returning to first principles, powerful data analysis capabilities remain the prerequisite for everything.
In future articles, I will continue to discuss more features of Lakehouse, as well as the positioning of real-time data warehouses and real-time query engines like Doris in this architecture. Feel free to leave comments.
Opinions expressed by DZone contributors are their own.
Comments