Lakehouse: Starting With Apache Doris + S3 Tables
This is the first article in the “Lakehouse: What’s the Big Deal?” series, where I will periodically discuss Lakehouse. Your comments and discussions are welcome.
Join the DZone community and get the full member experience.
Join For FreeAmong the numerous AI products launched at the AWS re:Invent 2024 conference, Amazon S3 Tables might have seemed inconspicuous. However, for database professionals, the emergence of S3 Tables signifies that the era of modular data analytics has arrived.
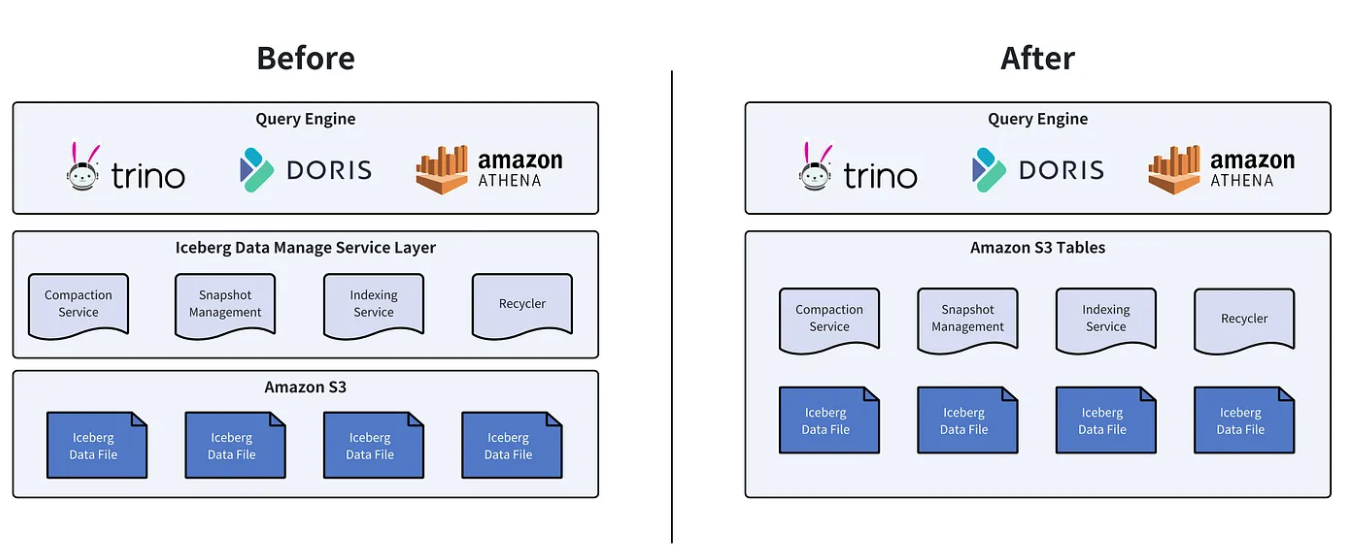
S3 Tables are a special type of S3 Bucket with built-in support for Apache Iceberg. They stand alongside the previously introduced General Purpose Bucket and Directory Bucket, collectively referred to as Table Bucket. This means you can now create a table bucket as easily as you would create a standard S3 Bucket.
S3 Tables come with the Iceberg table format pre-integrated and are compatible with Iceberg’s APIs externally. Beyond the table format, they also include built-in table management services that automatically optimize and organize table data. For instance, tasks like merging small files, which previously required Spark, can now be directly handled by S3 Tables (though, of course, at a cost). If we consider standard S3 Buckets as rough, unfinished houses, then table buckets are like fully furnished, move-in-ready homes.
According to the official website, S3 Tables offers the following features:
- Scalability. With a simple purchase, you can acquire a table storage system that rivals the scalability and availability of S3.
- Fully-managed. Built-in table management services, such as compaction, snapshot management, garbage file cleanup, and more, automatically optimize query efficiency and cost over time.
- Enhanced performance. Compared to storing Iceberg tables in general-purpose S3 buckets, query performance can be up to 3 times faster, and transactions per second can be up to 10 times higher.
- Seamless integration. Seamless integration with AWS Glue and commonly used query and analytics engines.
It seems like things have suddenly become much simpler:
- Purchase a table bucket.
- Launch a query engine.
“Congratulations, you now have a Lakehouse!”
“However, is it really that simple?”
“Yes, but not entirely.”
Next, I’ll walk you through how to seamlessly build a simplified version of a Lakehouse using Apache Doris + S3 Tables. After that, we’ll circle back to our main topic: “Lakehouse: What’s the Big Deal?”
Hands-on Guide of Apache Doris + S3 Tables
S3 Tables are compatible with the Iceberg API, and Apache Doris already has robust support for the Iceberg table format. Therefore, only minimal code modifications are required. However, due to the limited documentation available for S3 Tables, I encountered a few unexpected issues along the way.
Official support for S3 Tables in Apache Doris is scheduled to be released in the Q1, 2025.
1. Purchase a Table Bucket
This step is very simple. Click to create, give it a name, and you’re done.

Once created, you will receive an ARN, which will later serve as the warehouse address for Iceberg.
Currently, almost no operations can be performed on a table bucket through the AWS console. You can’t even delete it or view its contents. All operations must be carried out via the AWS CLI or analytical components like Amazon EMR, Athena, or Redshift (and some of these only support read operations, not table creation or writes).
However, we will soon have another option: Apache Doris.
2. Launch an Apache Doris Cluster
There is a quick-start guide for Apache Doris. But the supporting for S3 Tables is not released yet, so here I run Doris in my own dev branch.
3. Embark on the S3 Tables Journey
From here on, things become incredibly straightforward. All operations can be completed using SQL within Doris.
Creating Catalog
CREATE CATALOG iceberg_s3 PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 's3tables',
'warehouse' = 'arn:aws:s3tables:us-east-1:169698000000:bucket/doris-s3-table-bucket',
's3.region' = 'us-east-1',
's3.endpoint' = 's3.us-east-1.amazonaws.com',
's3.access_key' = 'AKIASPAWQE3ITEXAMPLE',
's3.secret_key' = 'l4rVnn3hCmwEXAMPLE/lht4rMIfbhVfEXAMPLE'
);Creating Database
SWITCH iceberg_s3;
CREATE DATABASE my_namespace;
SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| my_namespace |
| mysql |
+--------------------+Creating Table, Inserting, and Querying
CREATE TABLE partition_table (
`ts` DATETIME COMMENT 'ts',
`id` INT COMMENT 'col1',
`pt1` STRING COMMENT 'pt1',
`pt2` STRING COMMENT 'pt2'
)
PARTITION BY LIST (day(ts), pt1, pt2) ();INSERT INTO partition_table VALUES
("2024-01-01 08:00:00", 1000, "us-east", "PART1"),
("2024-01-02 10:00:00", 1002, "us-sout", "PART2");
SELECT * FROM partition_table;
+----------------------------+------+---------+-------+
| ts | id | pt1 | pt2 |
+----------------------------+------+---------+-------+
| 2024-01-02 10:00:00.000000 | 1002 | us-sout | PART2 |
| 2024-01-01 08:00:00.000000 | 1000 | us-east | PART1 |
+----------------------------+------+---------+-------+Time Travel
We can insert another batch of data and then use the iceberg_meta() table function to view the snapshots in Iceberg:
INSERT INTO partition_table VALUES
("2024-01-03 08:00:00", 1000, "us-east", "PART1"),
("2024-01-04 10:00:00", 1002, "us-sout", "PART2");SELECT * FROM iceberg_meta(
'table' = 'iceberg_s3.my_namespace.partition_table',
'query_type' = 'snapshots'
)\G
*************************** 1. row ***************************
committed_at: 2025-01-15 23:27:01
snapshot_id: 6834769222601914216
parent_id: -1
operation: append
manifest_list: s3://80afcb3f-6edf-46f2-7fhehwj6cengfwc7n6iz7ipzakd7quse1b--table-s3/metadata/snap-6834769222601914216-1-a6b2230d-fc0d-4c1d-8f20-94bb798f27b1.avro
summary: {"added-data-files":"2","added-records":"2","added-files-size":"5152","changed-partition-count":"2","total-records":"2","total-files-size":"5152","total-data-files":"2","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0","iceberg-version":"Apache Iceberg 1.6.1 (commit 8e9d59d299be42b0bca9461457cd1e95dbaad086)"}
*************************** 2. row ***************************
committed_at: 2025-01-15 23:30:00
snapshot_id: 5670090782912867298
parent_id: 6834769222601914216
operation: append
manifest_list: s3://80afcb3f-6edf-46f2-7fhehwj6cengfwc7n6iz7ipzakd7quse1b--table-s3/metadata/snap-5670090782912867298-1-beeed339-be96-4710-858b-f39bb01cc3ff.avro
summary: {"added-data-files":"2","added-records":"2","added-files-size":"5152","changed-partition-count":"2","total-records":"4","total-files-size":"10304","total-data-files":"4","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0","iceberg-version":"Apache Iceberg 1.6.1 (commit 8e9d59d299be42b0bca9461457cd1e95dbaad086)"}Use the FOR VERSION AS OF syntax to query a specific snapshot:
SELECT * FROM partition_table FOR VERSION AS OF 5670090782912867298;
+----------------------------+------+---------+-------+
| ts | id | pt1 | pt2 |
+----------------------------+------+---------+-------+
| 2024-01-04 10:00:00.000000 | 1002 | us-sout | PART2 |
| 2024-01-03 08:00:00.000000 | 1000 | us-east | PART1 |
| 2024-01-01 08:00:00.000000 | 1000 | us-east | PART1 |
| 2024-01-02 10:00:00.000000 | 1002 | us-sout | PART2 |
+----------------------------+------+---------+-------+SELECT * FROM partition_table FOR VERSION AS OF 6834769222601914216;
+----------------------------+------+---------+-------+
| ts | id | pt1 | pt2 |
+----------------------------+------+---------+-------+
| 2024-01-02 10:00:00.000000 | 1002 | us-sout | PART2 |
| 2024-01-01 08:00:00.000000 | 1000 | us-east | PART1 |
+----------------------------+------+---------+-------+Of course, the data written by Doris can be queried by other engines like Spark:
scala> spark.sql("SELECT * FROM s3tablesbucket.my_namespace.`partition_table` ").show()
+-------------------+----+-------+-----+
| ts| id| pt1| pt2|
+-------------------+----+-------+-----+
|2024-01-02 10:00:00|1002|us-sout|PART2|
|2024-01-01 08:00:00|1000|us-east|PART1|
|2024-01-04 10:00:00|1002|us-sout|PART2|
|2024-01-03 08:00:00|1000|us-east|PART1|
+-------------------+----+-------+-----+So far, we have completed the initial experience of Doris + S3 Tables. Regarding more features of S3 Tables, such as auto-compression, snapshot management, etc., I will share them with you after further exploration.
As can be seen in this scenario, Doris only serves as a stateless query engine. The metadata and data (referring to that of S3 Tables here) are all stored in the table bucket. Not only do we not need to worry about cumbersome control actions and status information like storage space, replicas, and data balancing, but we can also easily share this data with other systems (such as Spark) to perform different query load tasks.
Lakehouse: What Is the Big Deal? (1)
OK, after this brief experience, let’s get back to the topic: “Lakehouse: What’s the Big Deal?”
Since Databricks proposed this concept, Lakehouse has almost become a common commodity. Virtually all analytical databases and query engines claim to be Lakehouse (including Doris). So, what exactly is Lakehouse? What problems is Lakehouse actually solving? I hope to share with you my understanding of Lakehouse by summarizing my observations and thoughts in the relevant fields over the years.
With the launch of S3 Tables, let’s first talk about two features of Lakehouse: Data Sharing, Diverse Workloads and Collaboration.
Data Sharing
From distributed systems to cloud-native, the most significant change in architecture is the shift from complete Shared-Nothing to Shared-Data. The core idea of Shared-Nothing is to divide and conquer. It makes full use of multiple “small” nodes to form a large distributed cluster. At the same time, it moves computing tasks closer to data storage nodes. Nodes process data orthogonally, avoiding network transmission, reducing mutual dependencies, and maximizing concurrent data processing. In the big data era, Shared-Nothing solved the problems of high-priced and non-scalable computing power.
However, with the improvement of cloud infrastructure, especially the emergence of object storage represented by S3, which features low cost, 99.999999999% of availability, and nearly unlimited storage expansion capabilities, it has become the standard storage infrastructure in the cloud era.
Data can be shared, which benefits from two aspects. First, storage systems represented by S3 serve as the foundation, enabling One Data, Access Everywhere. Object storage provides a unified access endpoint, allowing any system to access the same data from any location.
Second, the diversity of storage formats enables different types of data to be stored on S3. From using the most basic PUT and GET operations to read and write files with object semantics, to file system semantics encapsulated based on S3 such as the S3A protocol, and now S3 Tables providing services with table semantics, S3 fully meets the storage requirements of data lakes for data diversity.
Therefore, whether it is a single AI training file, audio or video data file, log, or two-dimensional relational table data, it can be stored in a unified system and provided with shared services.
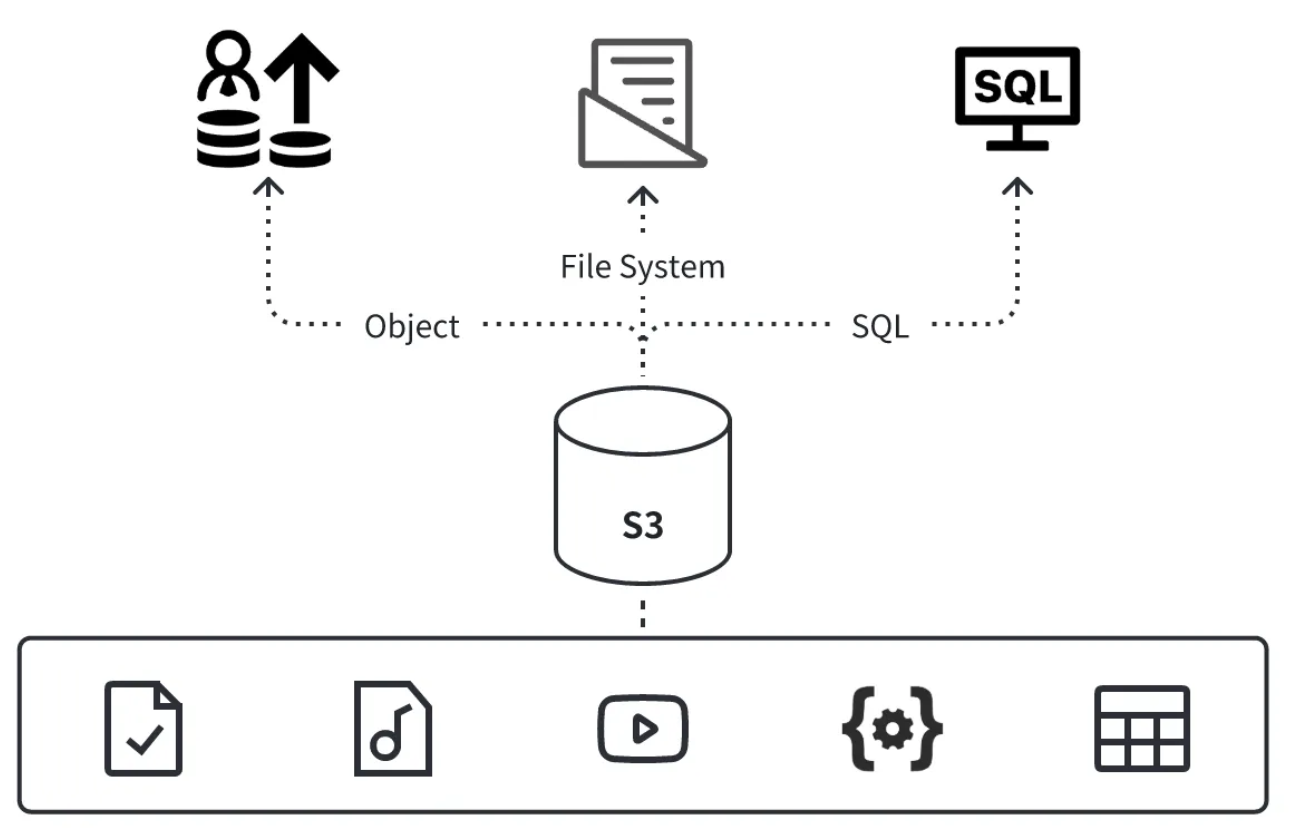
Data sharing addresses issues such as data consistency among different systems, as well as the conversion costs and timeliness of data transfer back and forth. It enables the achievement of a Single Source Of Truth.
Diverse Workloads and Collaboration
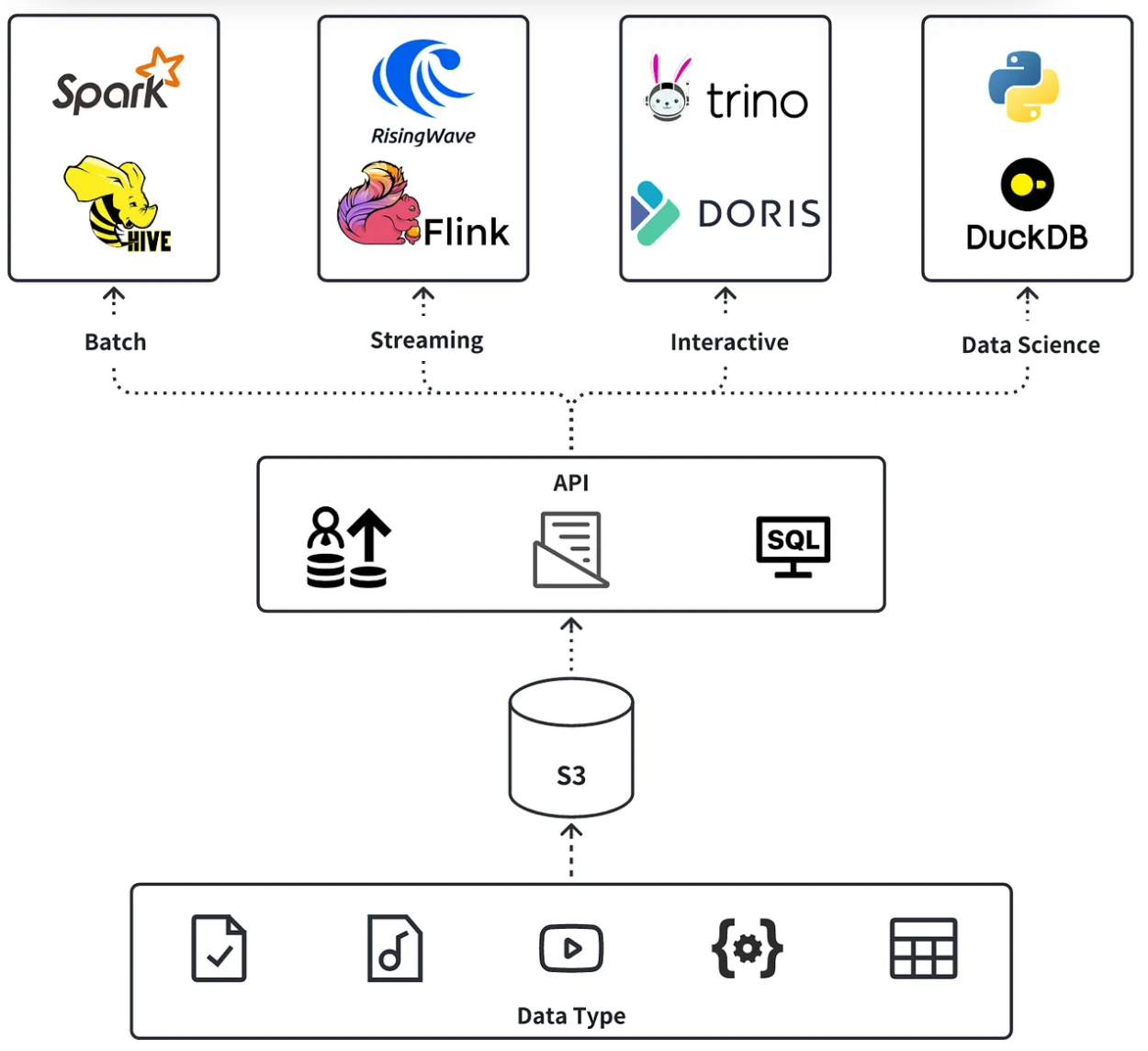
When we talk about Iceberg, we usually discuss its features as an upgraded replacement for Hadoop. Naturally, it is also related to how distributed computing engines such as Spark, Doris, and Trino handle large-scale data. However, as we encounter more Iceberg application scenarios, we find that Iceberg is no longer limited to the storage and processing of distributed and massive data in the big data era. Instead, by combining data-sharing capabilities, it makes it possible for diverse analytical workloads and collaborative processing.
For example, in big data processing, users can use Spark/Hive to perform batch data processing on Iceberg; use Flink/RisingWave to stream OLTP database changes into Iceberg through CDC or conduct stream processing; and use Doris/Trino to perform interactive query analysis on Iceberg.
On the other hand, users can also use DuckDB/Daft to access Iceberg on their Macs at any time and explore the data they are interested in. They can also process AI training data on Iceberg through the PyIceberg project. Excitingly, all of this happens on the same dataset. We no longer need to rebuild clusters, create tables, and import data for temporary data analysis needs. Nor do we need to worry about data credibility and inconsistent data quality. Everything becomes quite natural and flexible.
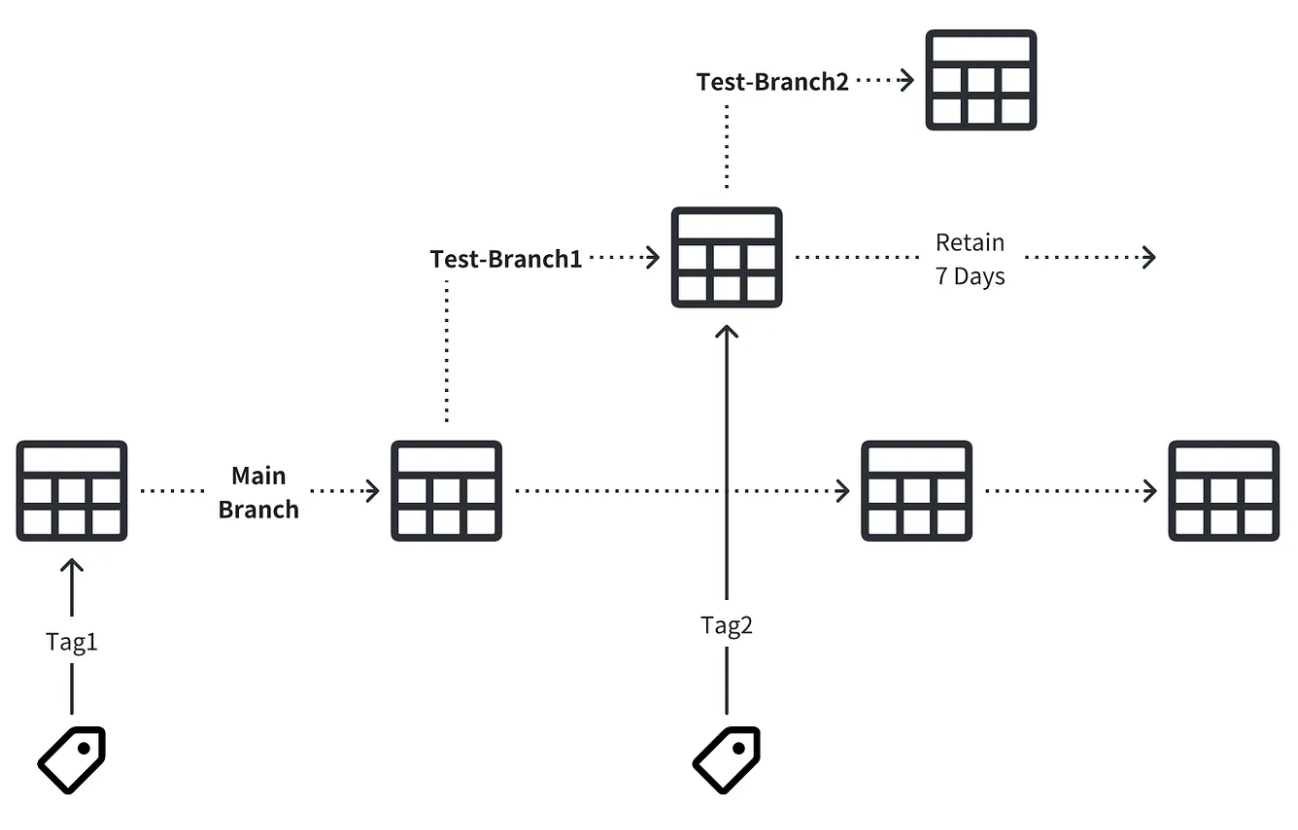
On the other hand, in addition to organizing originally scattered and low-quality data in a standardized way through table semantics, Iceberg further enhances the ability of collaborative data processing through version management. Readers of this article should be familiar with Git and have surely used GitHub. GitHub is the most typical case of achieving multi-person collaborative development through version management. Through branches, tags, and MVCC (Multi Version Concurrency Control), we can collaboratively complete the same project without interfering with each other.
Iceberg also provides functions similar to Branch and Tag, allowing users to create snapshots and branches on tabular data (instead of redundantly storing multiple data copies), and complete different data processing on branches without affecting the main data.
For example, a DBA can create a branch to independently verify the performance of different data indexes, and another can create a snapshot that only retains data for 30 days for historical data analysis.
To Be Continued
Based on data sharing, diverse workloads, and collaboration, Lakehouse has brought us a new paradigm for data analysis. S3 Tables further simplify the setup and maintenance of underlying storage facilities on this basis, achieving a nearly out-of-the-box effect.
In the follow-up, I will continue to discuss more features of Lakehouse, as well as the positioning of real-time data warehouses and real-time query engines like Doris in this architecture. Everyone is welcome to leave comments and communicate.
Opinions expressed by DZone contributors are their own.
Comments