"Lazy" Database Synchronization Using RabbitMQ
Join the DZone community and get the full member experience.
Join For FreeThe Problem
Obviously, there are tons of different ways to sync databases, so why should it be described again? Let's imagine that we have an unusual situation with restrictions below:
- A future system will have some Head Office (HO) and a couple of Branch Offices (BOs)
- All offices are located in different places, and some of them have difficulties with the internet connection. It could even be a situation where the internet is available for 1-2 hours per day.
- Almost all vital data is created in the HO and should be presented as read-only in BOs.
- Data exchange should be limited with appropriate permissions (for example, if an operator has created some sensitive data in the HO for BO1, only BO1 should have access to it).
- HO should have access to all information that has been created or modified in BOs.
According to all described points final decision to write own DB sync mechanism has been made.
Basic Idea
Due to connection degradation between HO and BOs, we have to sync everything within short-term sessions.
Since there is no need to send information to all branches in general cases, we should be able to orchestrate data flow.
Those thoughts bring us to the idea that we might implement some kind of RPC where an event occurs in one office, and it is reproduced (replayed) in another. Message queues (MQ) are a perfect solution to sync data between branches. RabbitMQ is my favorite MQ, so I will use it in this example. Also, this application will use the .NET stack which has a convenient API client implementation for RabbitMQ called EasyNetQ.
High Level Application Architecture
According to the idea of replaying some actions on other system instances, we should be able to divide them into single business-logic operations. The best way to achieve this it is by using the Aggregate Roots approach. The main idea is to have separated objects that are divided by domain entities, and each call to the methods of those objects is a single change to state of the business logic. For example, if we have some domain object Document and the ability to Get, Upsert, or Apply/Unapply, then we should describe its root as (pseudocode):
public class DocumentRoot
{
public Document Get(Id) { ... }
public Document Upsert(Document) { ... }
public bool Apply(Id) { ... }
public bool UnApply(Id) { ... }
}
Also, it's very important to ensure that each call will be in a transaction in order to avoid data loss. This can be achieved using simple method interception (for example Autofac + Castle.Proxy). In other worlds, the core process will look like this:
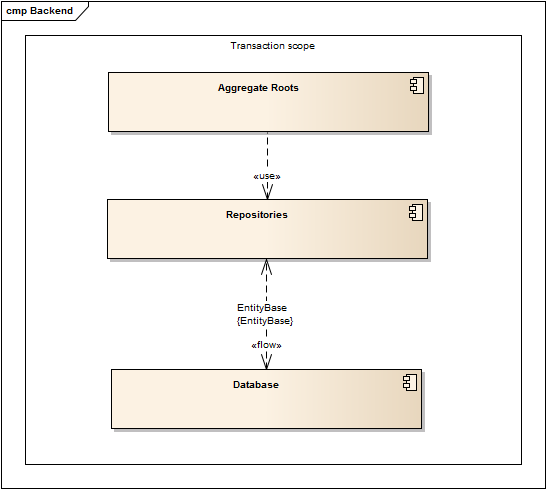
Keep in mind things as entities primary keys, because data will be populated between different system instances, and we'll need to be sure that ID's will be the same.
Also, collisions are possible while using simple auto-incrementing PK's, so our choice is GUID. With the help of a base repository, it's very simple to implement new GUID storage during object creation. Let's assume that we have an ExchangeInformation object that handles all data needed to restore a root call on a remote system. It will contain info about the method name, type name, input, and output params – this data can be obtained from a root interceptor. Also, it should have the list of new ID's, but it's not hard to get them too, even though we'll need to implement the UnitOfWork pattern on an ORM type to support transactions. This will allow us to place our ExchangeInformation in that UoF object (for example, within Entity Framework it's DbContext). Here is the implementation (using EF) of saving any changes in a domain within the base generic repository where the base entity looks like:
public class EntityBase
{
public long Id { get; set; }
public Guid Guid { get; set; }
}
public virtual void Save(T entity)
{
DbEntityEntry<T> entry = Context.Entry(entity);
if (entity.Guid == Guid.Empty)
{
try
{
Guid newGuid = Context.ExchangeInformation.IsExchangeRestore
? Context.ExchangeInformation.NewGuids[0]
: Guid.NewGuid();
if (Context.ExchangeInformation.IsExchangeRestore)
{
Context.ExchangeInformation.NewGuids.RemoveAt(0);
}
else
{
Context.ExchangeInformation.NewGuids.Add(newGuid);
}
entity.Guid = newGuid;
}
catch
{
throw new Exception("Failed to restore exchange, no guid found");
}
entry.State = EntityState.Added;
return;
}
Context.Entry(entity).State = EntityState.Modified;
}
One more important note: to avoid code duplication, it's necessary to use GUID's on clients, because if they operate any other ID's we'll need to write two different implementations of any method.
Big Picture
After preparation completion, we can proceed with architecture design. Since every system instance should be able to send and receive new data, we can declare two RMQ topics: input and output. Also, because message flow must be orchestrated, queues for each system instance should be created within the output topic. The simplest strategy for a routing implementation is to use the branch office guide as a key.
So we know how to do following at the moment :
- Save the source event in one office.
- Put this event to selected queues (selection could be made but it depends on the situation: read from the entity, call some additional method, use attributes etc.)
The next step is a solution for how to make output events from one office appear in the input queue of the other office.
RabbitMQ has two plugins for that: Federation and Shovel. They are quite similar, but shovel is working on a lower level and has more options to control the synchronization process, so that we'll use the second one to link queues. Shovel is very good with handling connection degradation and has lot of additional configurable options like message republishing properties, routing etc.
Now it's time to combine all pieces in to single picture:
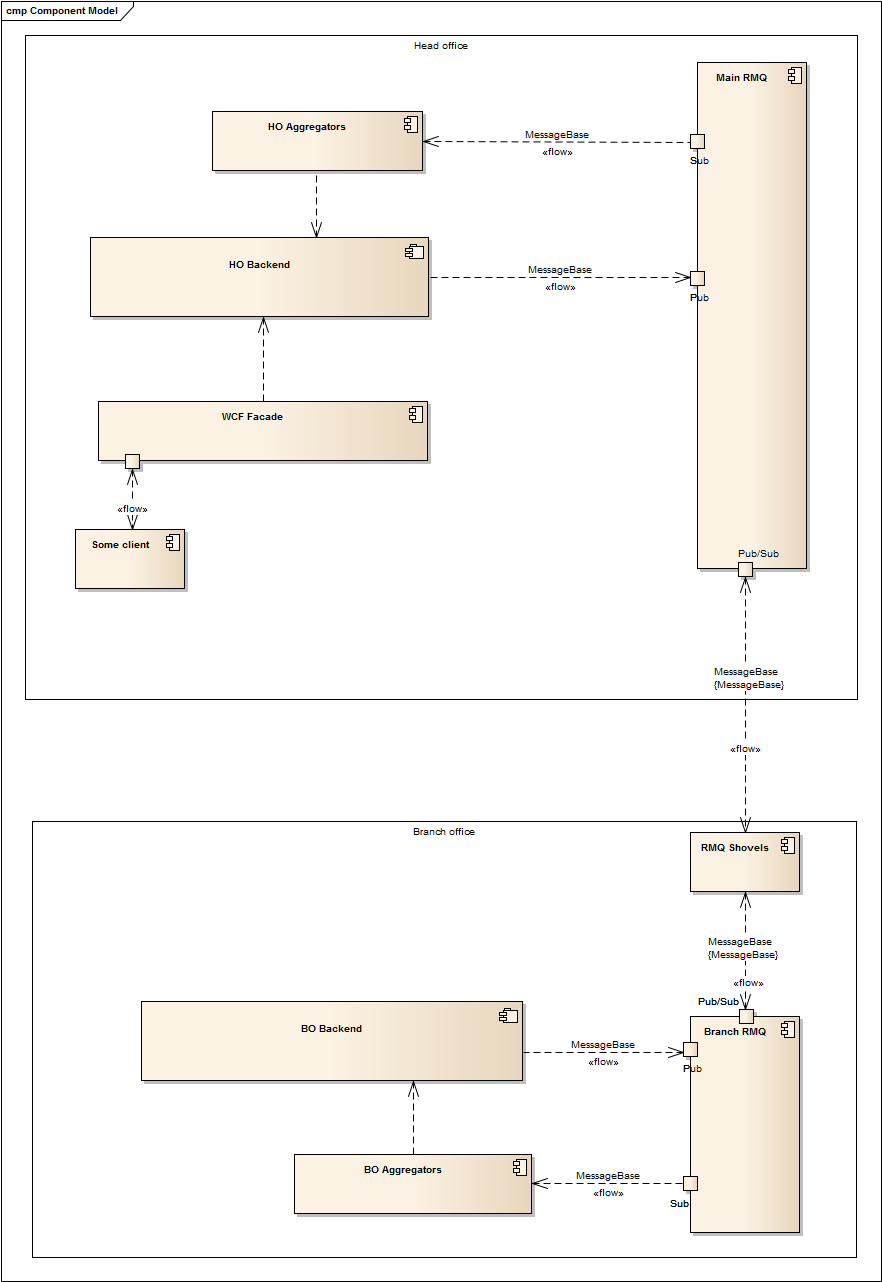
Aggregators here are simple RabbitMQ consumers that handle incoming messages from other offices and launch appropriate methods.
One other problem is restoring transferred params. From my point of view the best way is to use Json.Net with type serialization and restore them on a remote system instance with a small hack:
private object[] GetParams(MethodInfo methodInfo, ExchangeInformation information, ExchangeMessage message)
{
ParameterInfo[] methodParams = methodInfo.GetParameters();
var listParams = new List<object>();
var inputParms = JsonConvert.DeserializeObject<List<JObject>>(information.InputParamsString);
for (int ii = 0; ii < methodParams.Length; ii++)
{
var jObject = JsonConvert.DeserializeObject<JObject>(information.OutputValueString);
string typeName = jObject["$type"].ToString();
listParams.Add(jObject.ToObject(Type.GetType(typeName)));
}
return listParams.ToArray();
}
Surely appropriate conditions for params count mismatch, so valid deserialization and so on are required.
Conclusions
The approach I've described is very easy to implement and it has lots of additional places that can be customized. For example, any other method can be executed before/instead of/after restoration on a target branch to change the logic of DOM behavior.
The main issue is that collisions can occur if two BOs edit same object at the same time. Actually, it's not hard to track this situation by adding a hash to EntityBase. Nevertheless, a human's decision is needed to resolve conflicts, so a simple UI is necessary in the HO where the operator can choose which data is correct.
Opinions expressed by DZone contributors are their own.
Comments