LDA for Text Summarization and Topic Detection
Let's look at LDA for text summarization and topic detection.
Join the DZone community and get the full member experience.
Join For FreeLatent Dirichlet Allocation
Machine learning clustering techniques are not the only way to extract topics from a text data set. Text mining literature has proposed a number of statistical models, known as probabilistic topic models, to detect topics from an unlabeled set of documents. One of the most popular models is the latent Dirichlet allocation (LDA) algorithm developed by Blei, Ng, and Jordan [i].
LDA is a generative unsupervised probabilistic algorithm that isolates the top K topics in a data set as described by the most relevant N keywords. In other words, the documents in the data set are represented as random mixtures of latent topics, where each topic is characterized by a Dirichlet distribution over a fixed vocabulary. “Latent” means that topics have to be inferred rather than directly observed.
The algorithm is defined as a generative model [ii], which means that it relies on some a priori statistical assumptions [iii], i.e.:
- Word order in documents is not important.
- Document order in the data set is not important.
- The number of topics has to be known in advance.
- The same word can belong to multiple topics.
- Each document in the total collection of D documents is seen as a mixture of K latent topics.
- Each topic has a multinomial distribution over a vocabulary of words w.
The generative process for LDA is given by:
θj ∼ D[α], Φk ∼ D[β], zij ∼ θj , xij ∼ Φzij
where:
- θj is the mixing proportion of topics for document j, and it is modeled by a Dirichlet distribution with parameter α.
- A Dirichlet prior with parameter β is placed on the word-topic distributions Φk.
- zij= k is the k topic drawn for the ith word in document j with probability θk| j.
- Word xij is drawn from topic zij, with xij taking on value w with probability Φw|zij.
Let’s have a look at the learning phase (or posterior computation). We have selected a fixed number K of topics to discover, and we want to learn the topic representation for each document and the words associated with each topic. Without going into too much detail, the algorithm operates as follows:
- At first, the algorithm randomly assigns each word in each document to one of the K topics. This assignment produces an initial topic representation for all documents and an initial word distribution for all K topics.
- Then, for each word w in document d and for each topic t, the algorithm computes:
- p(topic t | document d), which is equal to the proportion of words in document d currently assigned to topic t.
- p(word w | topic t) which corresponds to the proportion of assignments to topic t over all documents containing this word w.
- Reassign word w to a new topic t, based on probability p(topic t | document d) * p(word w | topic t).
- It then repeats the previous two steps iteratively until convergence.
There are several variations and extensions of the LDA algorithm, some of them focusing on better algorithm performance [iv].
Text Summarization
A classic use case in text analytics is text summarization; that is the art of extracting the most meaningful words from a text document to represent it.
For example, if we have to catalog the tragedy of “Romeo and Juliet” by Shakespeare with, let’s say, five keywords only, “love,” “death,” “young,” “gentlemen,” and “quarrel” might be sufficiently descriptive. Of course, the poetry is lost but the main topics are preserved via this keyword-based representation of the text.
To obtain this kind of text summarization, we can use any of the keyword extraction techniques available in the KNIME Text Processing extension: Keygraph keyword extractor, Chi-square keyword extractor, or keyword extraction based on tf*idf frequency measure. For a detailed description of the algorithms behind these techniques, refer to Chapter 4 in “From Words to Wisdom” [v].
Another common way to perform summarization of a text is to use the LDA algorithm. The node implementing the LDA algorithm in KNIME Analytics Platform is the Topic Extractor (Parallel LDA) node.
If we apply the Topic Extractor (Parallel LDA) node to the “Romeo and Juliet” tragedy (Figure 1), when searching for three topics, each one represented by 10 keywords, we find one dominant topic described by “love,” “death,” “lady,” “night,” and “thou” and two minor topics described respectively by “gentlemen,” “pretty,” “lady,” and “quarrel,” and by “die,” “youth,” “villain,” and “slaughter.” The topic importance is quantified by its keyword’s weights. If we report those topics’ keywords via a word cloud and we apply their weight to the word size, we easily see that topic 0 in red is the dominant one (Figure 2).
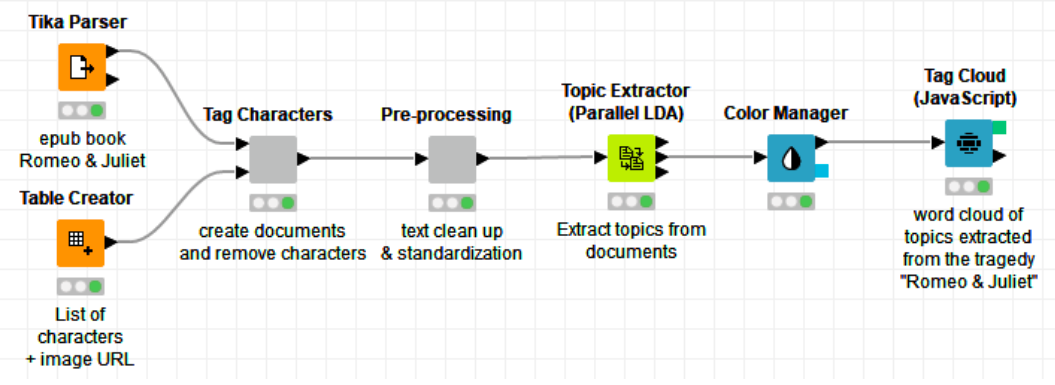
Figure 1. Summarizing “Romeo and Juliet” tragedy with 10 keywords x three topics with a Topic Extractor (Parallel LDA) node, implementing the LDA algorithm.
Note. The Tika Parser node, used here to read the epub document of the play “Romeo and Juliet” is a very versatile node to read a number of different formats for text documents: from .epub to .pdf, from .pptx to .docx, and many more.

Figure 2. The resulting three topics — in green, blue and red — summarizing “Romeo and Juliet.” Keyword weight defines keyword size in the word cloud. Note the dominant red topic of “love” and “death.”
Topic Detection
The LDA algorithm actually performs more than just text summarization; it also discovers recurring topics in a document collection. In this case, we talk of topic detection.
The LDA algorithm extracts a set of keywords from each text document in the collection. Documents are then clustered together to learn the recurring keywords in groups of documents. These sets of recurring keywords are then considered a topic common to a number of documents in the collection.
Where is topic detection used?
Let’s suppose we have a series of reviews for a product, a restaurant or a tourist location. By extracting a few topics common to review groups, we can discover the features of the product/restaurant/tourist location that have impressed the reviewers the most.
Let’s suppose we have a confused set of pictures with descriptions. We could reorganize them based on the topics associated with their description texts.
Let’s suppose we have a number of newspapers, each reporting on a set of news: Detecting the common topics helps to identify the journal orientation and the trend of the day.
You get the point. I am sure you can come up with a number of similar use cases involving topic detection.
To implement a topic detection application via the LDA algorithm, you first need a collection of text documents, not necessarily labeled. LDA is a clustering technique: No labels are necessary. For this example, we have used a collection of 190 news articles from various newspapers. The goal is to label each news item with a topic.
The central piece of a workflow that implements topic detection is the LDA node. After preparing the data, we feed the text documents into the LDA node. We then set the LDA node to report n topics (for example, ) and to describe each of these topics with m words (for example, ). Again, another word cloud of the topic keywords, where size proportional to the keyword weights, has been built and can be seen in Figure 3.
Note. Here, simple document-based representation is sufficient. Word/term extraction or text vectorization here is not necessary. The Topic Extractor (LDA) node performs all such operations internally.

Figure 3. Word cloud of 10 keywords x seven topics in the news data set. The journal news all seems to relate to sports and BBQ.
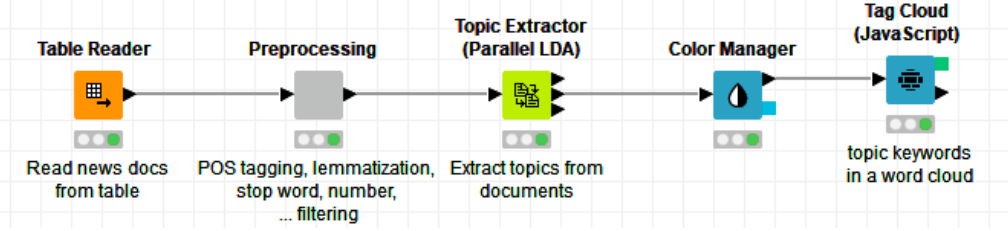
Figure 4. Workflow extracting seven topics — each one described by 10 keywords — on the news data set with the Topic Extractor (Parallel LDA) node, implementing the LDA algorithm.
Several topics emerge from the word cloud, for example, one shown in purple about BBQ recipes, one in green about reading sports news, followed by other topics concerning sports and grilling. It is obviously a collection of news articles about outdoor cooking and watching sports.
In the first output table of the LDA node, each news article from the input data set has been assigned to one of the discovered topics. The news articles are subsequently grouped into seven topic groups, as was the goal of this small project.
There is no deployment for this use case. Indeed, the LDA node works only on one set of text documents. To calculate the distance between a word/keyword-based representation of a text and that of the detected topics, it would be really hard — if not impossible — mainly because of the reduced topic keyword dictionary. Indeed, it is very unlikely that a new document will contain many, if any, of the few keywords used to describe the topics.
A frequently asked question is “How many topics shall I extract to have minimal coverage of the data set?” As for all clustering optimization questions, there is no theory-based answer. A few attempts have been proposed. Here we refer to one using the elbow method to optimize the number of LDA topics [vi].
Conclusions
We have shown here two practical applications of the latent Dirichlet allocation algorithm: one for text summarization and one for topic detection on a text collection.
LDA algorithm and other text processing functions were implemented using the graphical user interface of KNIME Analytics Platform. The workflows implementing the applications are shown respectively in Figures 1 and 4.
Workflows are available for free download on the KNIME public EXAMPLES server under EXAMPLES/08_Other_Analytics_Types/01_Text_Processing/25_Topic_Detection_LDA.
Sources
[i] Blei, Ng, and Jordan (2003) Latent Dirichlet Allocation. Journal of Machine Learning Research, 993-1022
[ii] A generative model describes how data are generated, in terms of a probabilistic model (https://www.ee.columbia.edu/~dpwe/e6820/lectures/L03-ml.pdf).
[iii] Newman, Asuncion, Smyth and Welling (2009) Distributed Algorithms for Topic Models. JMLR
[iv] Yao, Mimno and McCallum (2009) Efficient Methods for Topic Model Inference on Streaming Document Collections, KDD
[v] Tursi, Silipo “From Words To Wisdom,” KNIME Press (2018) https://www.knime.com/knimepress/from-words-to-wisdom
[vi] K. Thiel and A. Dewi “Topic Extraction. Optimizing the Number of Topics with the Elbow Method” KNIME blog (2017)
Opinions expressed by DZone contributors are their own.
Comments