Learning to Read x86 Assembly Language
How does your code talk to the machine? Assembly doesn't have to be only for debugging, but its syntax can be hard to wrap your head around.
Join the DZone community and get the full member experience.
Join For Freewriting assembly language is something best left for the experts. to write code that runs directly on your microprocessor, you need to know how memory segmentation works, what the intended use of each register is, how code executes in real and protected modes, and much, much more. and, of course, modern compilers will usually produce faster, more optimized code than you ever could, without making any mistakes.
reading assembly language, on the other hand, isn’t nearly as difficult and can be a useful skill to have: someday, you might need to debug code without having the original source. you’ll begin to understand what a microprocessor can and can’t do by reading its language directly. and you’ll appreciate and understand your favorite programming language even more after seeing your own code translated into low-level machine instructions.
but most importantly, learning about assembly language can be a lot of fun.
usually, reading assembly language is no fun at all
unfortunately, most of us only see assembly language after something has gone wrong, terribly wrong, when we encounter something like this:
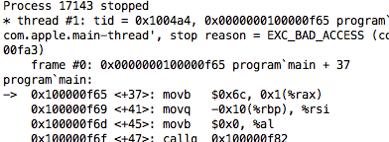
this is what a segmentation fault looks like in a debugger. the debugger shows me assembly language because it doesn’t know what else to show me. a “segmentation fault” means one of the assembly language instructions. for example, the movb $0x6c, 0x1(%rax) line above, has tried to write to a portion of memory that it is not allowed to.
it’s no wonder that most of us dislike reading low-level code like this. we only ever see it when we’re in the midst of debugging something, when the language and tools we normally rely on have let us down. we never see assembly language under happier circumstances; it is always the bearer of bad news.
converting my own code to assembly language
this week, i had some free time and decided to read some assembly language just for fun. i wanted to read low-level code that was working properly, not code that was overwriting some other process’s memory. i wanted to see if i could understand it like any other programming language. to make things easier, i decided to translate some of my own code into assembly language so i could focus on the assembly language syntax. it was easier to figure out what the instructions meant because i knew what they were doing.
i’m a ruby developer, and so i was interested in knowing how my ruby code would look translated into assembly language. unfortunately, the ruby interpreter (at least the standard “mri” version of ruby) never does this. instead, the ruby interpreter itself is compiled into machine language and runs my code using a virtual machine. but i wanted to see what a real machine would do, not a virtual one.
instead, i decided to use crystal , a variation on ruby that uses llvm to compile ruby to native machine language before running it. and because the llvm system can also produce an assembly language version of the code it produces, using crystal was the perfect way for me to see my ruby code translated so a microprocessor could understand it.
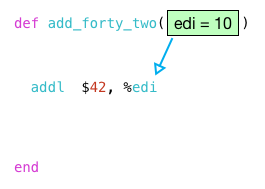
i started by writing an extremely simple program that adds 42 to a given integer:
def add_forty_two(n)
n+42
end
puts add_forty_two(10)
this was both ruby code:
$ ruby add_forty_two.rb
52
and crystal code:
$ crystal add_forty_two.rb
52
both produced the same result, of course. but only crystal could produce a copy in assembly language:
$ crystal build add_forty_two.rb --emit asm
this created a file called add_forty_two.s, which contained tens of thousands of lines of assembly language code. (most of this was the compiled version of the crystal runtime library.) i opened add_forty_two.s in a text editor and searched for “add_forty_two,” the name of my function. first i found the call site, the code that calls my add_forty_two function:

i’ll return to this a bit later. searching again, i found the x86 assembly language version of my function:
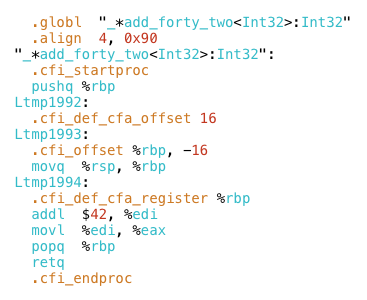
next, i deleted all of the assembler directives, such as .globl and .cfi_offset. someday it would be interesting to learn about these, but i wanted to focus on the actual machine instructions. and finally, i pasted the the remaining code inside my ruby function.
then, i saw what my computer actually does when it executes add_forty_two:

x86 assembly language: almost easy to read
this code is almost easy to follow. i can guess what each instruction means: push, add, move, etc., but i can’t quite follow what’s going on here. mov probably means to move, but what is the computer moving? and from where to where?

was x86 assembly language designed in hungary?
the problem is that x86 assembly language was designed by hungarians. i don’t mean that literally; in fact, i have no idea who designed x86 assembly language. i mean that x86 code reminds me of the hungarian language.
i lived in budapest for about a year in 1992 and managed to become conversational in hungarian, although i’ve forgotten all of it since. a beautiful language, hungarian is notoriously difficult for foreigners to learn. related only to finnish and estonian, its grammar doesn’t resemble italian, french, or other romance languages; nor does it resemble russian or any of the other slavic languages from eastern europe.
the one bit of hungarian grammar i still remember is that instead of using separate words for prepositions, such as inside, outside, etc., you append different suffixes to the target word. for example “inside the house” would be a házban . house is ház while inside is ban . similarly “in budapest” would be budapesten – the en suffix means “in.” x86 assembly language code reminds me of hungarian. you don’t use mov to move something; you use movq. you don’t add something; you use the addl instruction.
it turns out tha x86 assembly is much simpler than hungarian; there are only a few simple suffixes that refer to the size of the data you are operating on. here are two examples:

the addl instruction really means “add long,” where “long” refers to a 4-byte or 32-bit value. in crystal, it corresponds to the int32 type, which is the default integer type and the type my add_forty_two method uses.
here’s another example:

the letter q refers to a “quad” word, or an 8-byte or 64-bit value. most x86 code these days works with 64-bit or 32-bit values, so you’ll most often see instructions that end with q or l . other suffixes are w for word (16 bits or 2 bytes) or b for 1 byte or 8 bits.
x86 registers
but what about all of the operands of the instructions? why do they all have a “%” prefix, such as %rsp or %edi? reading x86 assembly language also reminds me of reading perl code. lots of punctuation symbols for no apparent reason. similar to perl, x86 assembly language uses sigils or magical punctuation characters to indicate the type of each operand value.
here are my two example instructions again:

here, the “$” symbol means the 42 is a literal or “immediate” value. as you might guess, this is the line of code that adds 42 to something. but what does it add it to? from the “%” character, we can see the x86 code is adding 42 to the edi register.
and what is a register? in a nutshell, the microprocessor inside your computer uses registers to hold values while your code is running. so the instruction above adds 42 to whatever value is contained in the edi register and saves it back into edi.
here’s the second example again:

this instruction, movq, refers to two registers: rsp and rbp. as you can guess, it moves whatever value is found in the rspregister to the rbp register.
how many registers are there? what are they called? let’s look at them using lldb:
(lldb) register read
general purpose registers:
rax = 0x0000000100300268
rbx = 0x0000000000000000
rcx = 0x00007fffd8132201 libsystem_kernel.dylib`__shmsys + 9
rdx = 0x0000000000000000
rdi = 0x000000000000000a
rsi = 0x00007fff5fbff898
rbp = 0x00007fff5fbffa30
rsp = 0x00007fff5fbff908
r8 = 0x0000000100014b60 add`sigfault_handler
r9 = 0x0000000100400000
r10 = 0x0000000000000000
r11 = 0x0000000000000206
r12 = 0x0000000000000000
r13 = 0x0000000000000000
r14 = 0x0000000000000000
r15 = 0x0000000000000000
rip = 0x0000000100013cd0 add`*add_forty_two:int32
rflags = 0x0000000000000202
cs = 0x000000000000002b
fs = 0x0000000000000000
gs = 0x0000000000000000
you can see there are over 20 registers inside my mac’s intel cpu, each containing a 64-bit or 8-byte value. lldb shows the values in hexadecimal. i don’t have time today to explain what all of these registers are used for, but here are a few highlights:
- rax, rbx, rcx, and rdx are general purpose registers used to hold on to intermediate values loaded from memory or used during a calculation of some kind.
- rsp is the stack pointer, which holds the memory location of the top of the stack.
- rbp is the base pointer, which holds the memory location of the base of the current stack frame
- rip is the instruction pointer, which holds the memory location of the next instruction to execute
- and rflags holds a series of flags, used by comparison instructions for example.
in fact, there are many more registers in a modern x86 microprocessor; lldb is only showing me the most commonly used registers. for a complete explanation, the definitive guide to all of this is the intel software developer’s manual . fortunately, my function’s assembly language code only uses a few registers. i don’t need to understand them all.
 registers available in the x86 instruction set
registers available in the x86 instruction set
(source:
immae via wikimedia commons
)
but wait a minute. why does my addl instruction refer to the edi register? this isn’t in the list of registers shown by lldb. where does this add operation occur? what register does it use?
it’s those hungarian designers again. it turns out that x86 assembly language also decorates the register names to indicate their sizes, similar to what we saw above with the instruction name suffixes. but for register names x86 syntax uses prefixes, not suffixes. (in c programming, hungarian notation actually refers to the practice of using prefixes on variable names to indicate their type.)
what? this is a crazy! why would any programming language use prefixes to indicate data size in one place, but then use suffixes to indicate the same thing somewhere else? to understand this, you have to remember that assembly language syntax wasn’t developed overnight. instead, it gradually evolved over the course of many years. originally, the registers used simple two letter names: ax, bx, cx. dx, sp, and ip. these were the registers on the original 8086 16-bit microprocessor from the 1970s. later, in the 1980s, when intel built 32-bit microprocessors, starting with the 80386, they renamed (or extended ) the ax, bx, cx, etc., registers to become eax, ebx, ecx, etc. these were later renamed again to rax, rbx etc. for 64-bit processors.
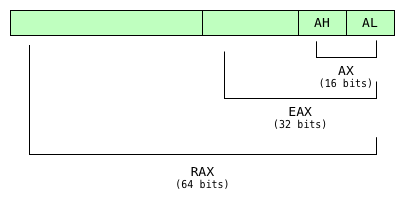
as you can see here, even today, x86 assembly code can refer to the same register using many different names. for example, works for alor ah for 8-bits, ax bit 16 bits, eax for 32 bits and rax for 64 bits.
x86 assembly language: reads left to right, except when it reads right to left
returning to the move instruction from above, how do we know which way the move happens?
that is, does this instruction move data from rsp to rbp? or from rbp to rsp? does it read left to right, or right to left?
it could be either! it turns out there are two versions of x86 syntax: “at&t or gnu assembler (gas)” syntax, which i’ve been using until now, and also “intel” syntax. gas reads left to right:
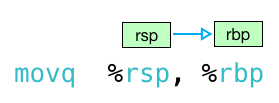
at&t/gas syntax
but equally valid and common is the intel syntax, which reads right to left:
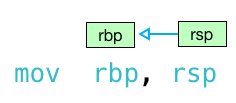
intel syntax
if you see perl-like sigils (%rsp and %rbp, for example) then you’re reading gas syntax and values will move from left to right. if you don’t see any “%” or “$” signs, then you have intel syntax and values move right to left. also, notice the intel syntax doesn’t append “q” or “l” on to the instruction names. this article does a great job explaining the differences between the two>
what a train wreck! it’s hard to imagine a more confusing state of affairs. but again, remember all of this has evolved over the course of 40 years. it wasn’t designed by any single person at any one time. there’s a tremendous amount of history behind each x86 assembly language instruction.
executing my simple program
now that i understand the basics of x86 assembly language syntax, i’m ready to return to my add_forty_two code and to try to understand how it works. here it is again:
reading the 6 instructions inside of add_forty_two, there are three different operations going on. first, we setup a new stack frame for our function:

the stack frame is an area of memory that my code can use to save local variable and other information. i won’t spend time on this today because my code is so simple it doesn’t use any local variables. the last two instructions clean up this stack frame and return to the calling code:

i won’t cover this today either. in my next article, i’ll go through a slightly more complicated example containing local variables and explain how x86 assembly code accesses them on the stack.
for today, i want to focus on the two instructions in the middle which actually implement add_forty_two:

we’re down to two assembly language instructions, but it’s still far from obvious what this code means! the key to understanding these two instructions is to realize that the argument to my function, n, is passed in using a register:

we can see this is true by returning to the call site in the add_forty_two.s file, to the code which calls my function:
note how the first movl instruction copies the value 10 into the edi register (the lower 32 bits of the rdi register):
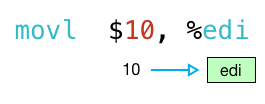
next, the callq instruction calls my function with 10 in edi:
so when the addl instruction runs, it will add 42 to the argument 10.
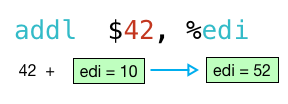
next, the movl instruction runs and copies the result 52 from edi to eax:
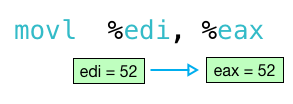
this, in turn, becomes the return value from my function:
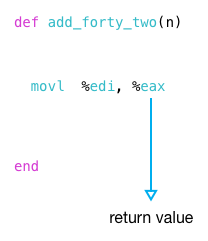
again, we can see this is the case by reading the call site code again:
what happens after add_forty_two returns? it moves %eax, the return value, to %edi where it becomes the argument to a second function call, the call to puts.
i’m not sure whether this pattern of using the %edi and %eax registers to hold the function arguments and return values is a x86 standard convention. my guess is that instead, it’s a pattern the llvm code generator uses. it may be that llvm only uses this technique for a single argument and single return value function like add_forty_two.
next time
i haven’t done much, but already i’m beginning to understand x86 assembly language. almost unintelligible when i first saw it, now i can start to follow what the machine instructions do when my code is executed. the key was learning how the instruction and register names change depending on the size of the value they operate on.
there’s much more to learn, of course. in my next article, i’ll take a look at how an x86 microprocessor uses the stack to save values, and how this maps to ruby using a slightly more complex example. along the way, i’ll learn about a few more important syntax rules of x86 assembly language.
Published at DZone with permission of Pat Shaughnessy. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments