Legacy Code and Tests
Legacy code isn't just what you get when the previous dev leaves. Your own code gets sucked into legacy all the time — but with automated tests, this can be prevented.
Join the DZone community and get the full member experience.
Join For FreeWhen talking about writing code, we usually assume that we've got a nice, clean slate and everything is done from scratch. And this is understandable — when you're starting a new project, you've got the opportunity to do things just right, and you apply all your accumulated experience and wisdom. It's a chance to realize your vision in code.
The problem is it's not often that you get to work on something brand new. Most of the time, we're maintaining something already built before us. When we're presented with a large and unfamiliar system, we call it legacy code, and working with it always takes more effort — invention is like going downhill, analysis is like climbing uphill.
There are excellent books on dealing with legacy code once you're thrown in at the deep end. How does it come about, though? Can we prevent it from emerging altogether? Let's try to figure that out, but first, let's define legacy code.
Definitions
Let's start with the obvious and most used ones. Legacy code is code that uses technology that is not supported anymore or code whose author isn't around.
However, those do not convey our feelings when dealing with a tangled mess of lines and using the word legacy as a curse. If we go with just this feeling, legacy code is code we don't want to touch or even code we're afraid to touch.
It's tempting to say that this is all just tantrums that it's over-sensitive people badmouthing stuff that doesn't follow the latest fad in programming. But there is an actual problem here — legacy code is code we don't understand and code that is risky and/or difficult to change.
That last one does sum up nicely the economic side of things. If the technology is obsolete, trying to change something might require major upgrades and refactoring parts of the system; if the author isn't around, we might break stuff so bad we'll be in a mess for weeks. And this is also the reason why we don't want to touch the code.
But this points us to a larger problem than changing technology or rotating authors. Because:
Legacy Code Is Useful Code
If code is useless, it will end up in the garbage disposal. Nobody is going to be working on it — thus, it will never become legacy. On the other hand, if code is useful, people will likely be adding new functionality to it. That means more dependencies, more interconnectedness between parts of the system, more complexity, and more temptations to take shortcuts. Sometimes, this is called active rot - as people work on a system, they add entropy; it takes extreme discipline and diligence to keep reversing that entropy.

This means that all useful code (=all code that people work on) tends to get sucked into the state of legacy.
This is an important point. Dealing with legacy code isn't just a one-time thing that happens when you inherit someone else's code base. Unless you take specific measures to prevent it, the code you and your team have written will also become legacy.
If we take that point of view, we can no longer explain the problems with legacy away by calling the author of the code an idiot or even saying that the problem is we can't talk to them directly. So, how do we prevent our code from becoming an unchangeable mess?
This is where we come back to another definition of legacy code, the one by Michael Feathers:
Legacy Code Is Code Without Tests
Isn't that a bit too specific? We were just talking about general stuff like the cost of change. Well, automated tests will prevent your code from becoming legacy — provided they've been properly written. So, let's explore how your code can rot, how tests can prevent it, and how we've got to write such tests.
Dealing With Creeping Legacy
OOP, functional programming, and everything in between teach us how to avoid spaghetti code, each in its own way. The general principles here are well-known. Promote weak coupling and strong cohesion and avoid redundancy; otherwise, you'll end up with a bowl of pasta. Spaghetti code means any attempt to change something causes cascading changes all over the code, and the high cost of change means legacy code.
Spaghetti code means any attempt to change something causes cascading changes all over the code, and the high cost of change means legacy code.
The point we want to make is that tests provide you with an objective indicator of how well you're adhering to those well-known best practices. It makes sense, right? To test a piece of code, you need to run it in isolation. This is only possible if that piece is sufficiently modular. If your code has high coupling, running a part of it in a test will be difficult — you'll need to grab a lot of stuff from all over your code base. If code has low cohesion, then tests will be more expensive because each tested piece will have different dependencies.
If object-oriented programming is your jam, then you know the value of polymorphism and encapsulation. Well, both of those enhance testability. Encapsulation means it's easier to isolate a piece of code; polymorphism means you're using interfaces and abstractions, which are not dependent on concrete implementations — making it easier to mock them.
The modularity of your code impacts the cost of testing it. If it is sufficiently modular, you don't need to run your entire test suite for every change; you can limit yourself to tests that cover a part of the code. If, for instance, database access only happens from inside one package dedicated to that purpose, then you don't need to re-run all tests for that package whenever changes happen elsewhere.
In other words, testability is an objective external indicator of your code quality; writing tests makes your code more reliable, modular, and easy on the eyes.
Dealing With Rotating Developers and Dungeon Masters
The turnover rate of software engineers is a significant problem — they rarely keep one job for more than two years. This means the code's author often isn't around to talk to; they usually don't get to experience the consequence of their design decisions, so they don't see how a model performs outside an ideal scenario. An engineer arrives at a greenfield project or convinces people that the current system just won't do; we simply have to redo it from scratch. They don't want to work with the legacy of the half-brained individual who worked on it before them. Two years pass, the project gets just as twisted and crooked, the engineer leaves on to a higher salaried position, and when a new programmer arrives, all the problems become the previous idiot's fault. This cycle is something we've witnessed many times.
Things might take a different road, and the author of the new system - usually a genuinely talented developer — might turn into a dungeon master (Alberto Brandolini's term). In this case, the developer stays, and they are the only one who knows the system in and out. Consequently, any change in the system goes through them. This means change is costly, the processes are mostly manual, and there is a single person who is always a bottleneck. This is not the fault of that person; the problem is systemic, and paradoxically, it's the same problem as with rotation: knowledge about code only exists in the head of its creator.
How do we get it out into the world? We use tools such as code reviews, comments, and documentation. And tests. Because tests are a great way of documenting your code.
One of Python's PEPs says that a docstring for a method should basically say what we should feed it, what we should get from it, its side effects, exceptions, and restrictions. This is more or less what you can read from a well-written arrange-act-assert test, provided the assert is informative (see also this).
Javas guidelines for Javadoc distinguish between two types of documentation: programming guides and API specs. The guides can contain quite a bit of prose. They describe concepts and terms; they're not what we're looking for here. The API specs, however, are similar in purpose to tests: they are even supposed to contain assertions.
This does not mean you can do away with documenting altogether and just rely on tests (at the very least, you'll want your tests to be documented, too). If you're asking yourself why some gimmick was used in a function, you'll need documentation. But if you want to know how that function is used, a test will provide an excellent example, simulate all dependencies, etc.
In other words, if the test base for your code is well-written (if the author isn't just testing what is easiest to test), then the code is much easier to understand because you've got a whole bunch of examples of how it should be used. Thus, it won't become legacy if the person who knows the code leaves.
Dealing With Obsolete Technology and Changing Requirements
No matter how well-written your code is or how good its documentation is, sooner or later, you'll need to migrate to a new technology, the requirements will change, or you'll want to refactor everything. XKCD has the truth of it: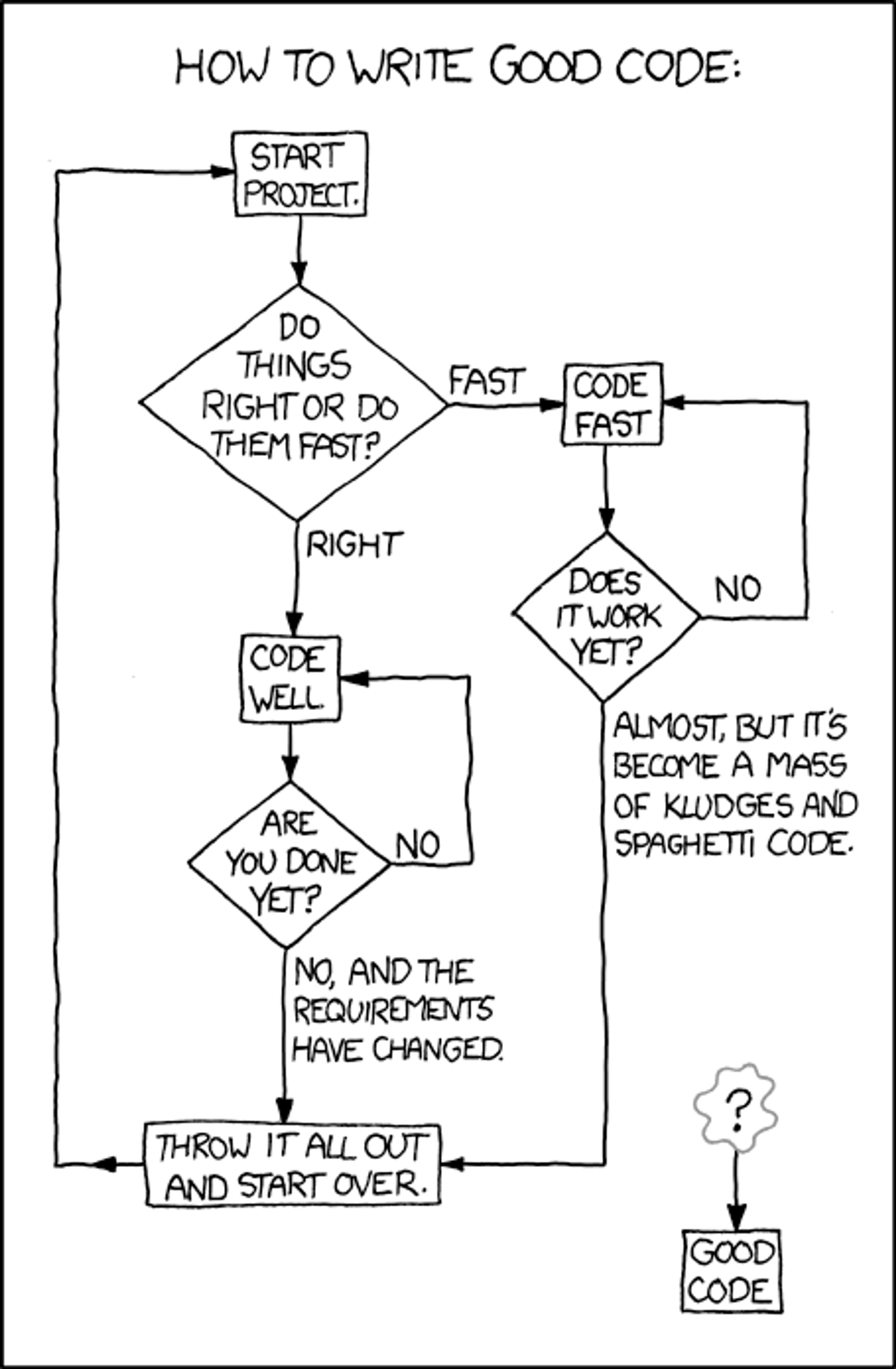
All code is rewritten at some point. And again, this is where tests can make your life easier.
There's this thing called Ilizarov surgery, when you get a metal frame installed around a damaged limb, and this both preserves the limb and helps direct the growth of fractured bones.
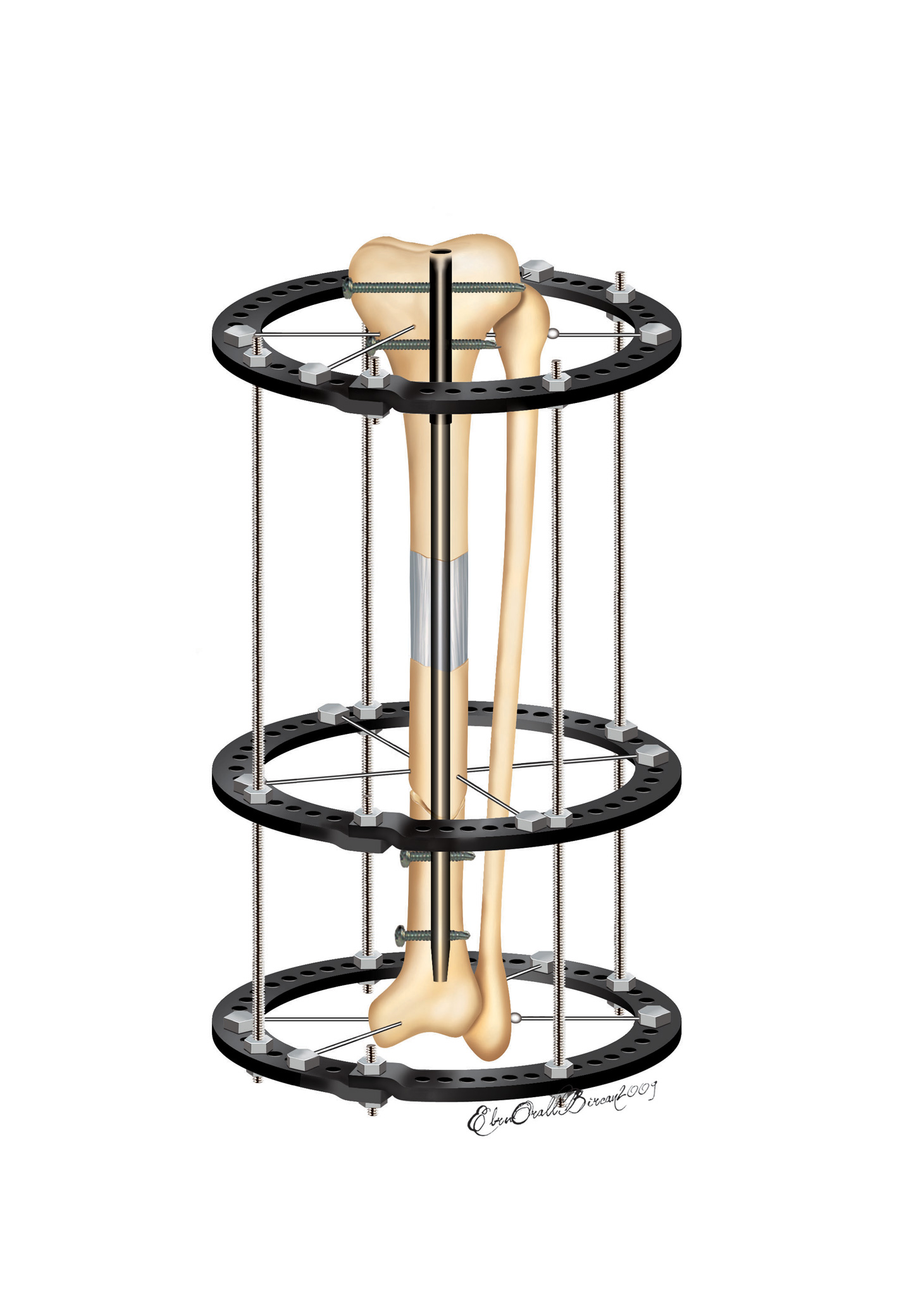 Essentially, that's what tests are. They fix the system in a particular state and ensure that whatever break you make inside doesn't affect functionality. This is how Michael Feathers defined refactoring: improving design without changing behavior. When you introduce a new technology, tests allow you to transition. When requirements change, tests preserve the rest of the functionality that hasn't changed and make sure that whatever you do to the code doesn't break what's already working. Big changes like this will always be painful, but with tests and other supporting practices, it is manageable, and your code doesn't become legacy.
Essentially, that's what tests are. They fix the system in a particular state and ensure that whatever break you make inside doesn't affect functionality. This is how Michael Feathers defined refactoring: improving design without changing behavior. When you introduce a new technology, tests allow you to transition. When requirements change, tests preserve the rest of the functionality that hasn't changed and make sure that whatever you do to the code doesn't break what's already working. Big changes like this will always be painful, but with tests and other supporting practices, it is manageable, and your code doesn't become legacy.
What This All Means for Writing Tests
So, your tests can do many things: they push you to write cleaner code, present examples of how the code is supposed to be used, and serve as a safety net in transitions. How do you write such tests?
First and foremost, writing tests should be a habit. If you've written a piece of code five months ago, and today a tester tells you it lacks testability — that's just annoyance. Now, you've got to measure the headache you get from digging into old code versus the headache from making it testable. But if you're covering your code with tests right away, it's all fresh in your mind, so zero headaches. And if you're doing this as a habit, you'll write testable code from the get-go, no changes necessary.
If your tests are to serve as an Ilizarov frame for changes, you'll need to be able to run your tests often. First and foremost, this means having a good unit test base that you can run at the drop of a hat. Ideally — it means having a proper TestOps process where all tests can be run automatically. Running tests as a habit goes hand in hand with covering code with tests as a habit, and it means it's easier to localize errors.
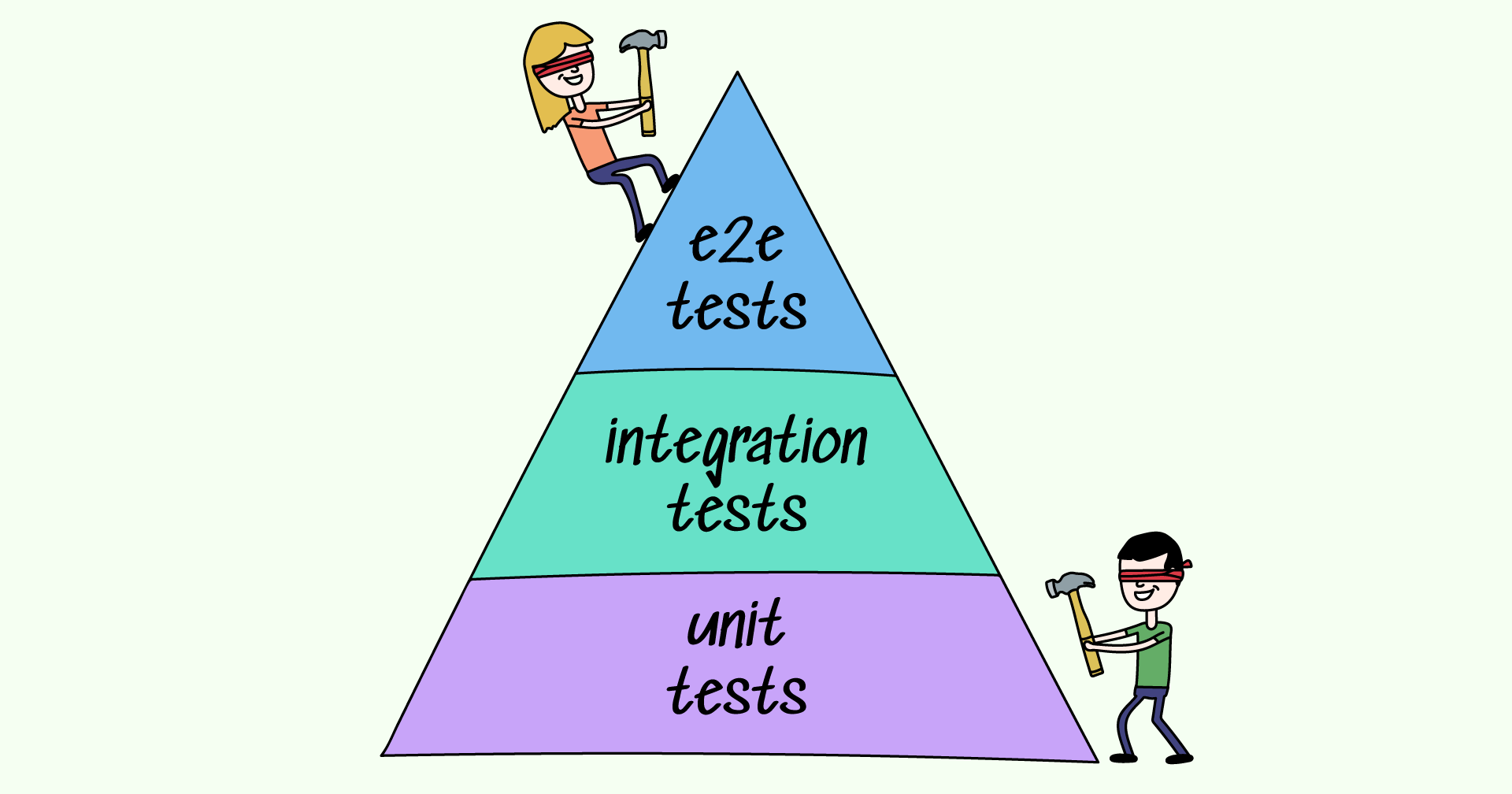
Of course, your tests need to run quickly for that to work. In addition to hardware requirements, this also means you should keep down the size of the test base. Here is where code modularity also helps, as it allows running just a part of your code base, provided that you're certain that changes won't propagate beyond that part. What also helps is keeping tests at their appropriate level of the pyramid: don't overcrowd the e2e level. It is only for testing business logic, so move everything lower if you can. If something can be run as a unit test without invoking costly dependencies - do that.
Together, these things mean that a developer has to have QA as part of their work cycle. Keep tests in mind when writing code, follow the code with tests, and run the test base after finishing a chunk of work:
It's also important that you've got the entire pyramid of tests: its different levels reinforce each other. Generally speaking, if you need the tests to be this frame that helps your code heal after a break, then the e2e tests are the ones you'll rely on most because unit tests tend to die along with the old code you're replacing. However, if you're refactoring the front end, the e2e tests will have to be replaced, but the unit- and other tests on the back end will still be of use. Also, writing new e2e tests will be easier if you're using the old ones as a guideline and not inventing everything from scratch.
Another point is that if the test base is to provide information about the purpose of your code, then the assertion statements should be informative — as precise as possible.
The traditional approach to testing is — change and then poke around to see if everything is all right. And it seems as if the more you poke, the more you care. But preventing creeping system rot is not so much about care as about using the right tools. You need a test base that is:
- Not haphazard, that covers every module and promotes modularity
- That informs you about the function of each module
- That can be run on demand to ensure the changes you're introducing don't change functionality
Legacy Is a Team Problem
Legacy code is a problem that arises when a team has to deal with code that was written "selfishly" - without following best practices regarding documentation, comments, tests, etc. How a team implements the best practices we've just discussed is also important.
As well as being a personal habit for developers, writing tests should also be accepted practice at the organization level. In particular, the definition of done when setting deadlines should include documentation and tests.
A deadline often means two completely different things for the programmer and the manager. The manager expects something polished and shiny; the programmer is happy if he can run it once and it doesn't crash. Or maybe the manager is afraid to bother the programmer too much, or maybe they think the programmer's time is more valuable than the tester's, so let's not waste it by making programmers write tests. And if the testers also live by the same deadline, then one month of developing + 1 month of testing will usually turn out to be 1.5 months of developing and then overtime for testers.
Whatever the reason is, the only way you get a stable workflow without crunch time is when deadlines are set with the knowledge that code must be shipped along with tests and documentation, maybe even Architectural Decision Records (ADRs) and Requests for Comments (RFCs) — those are excellent at conveying the context and backstory to the future reader of the code. Without all this, even the author will forget their own code once a few months have passed, and the code will become legacy.
Promoting testability is important for testers, but the ones who can actually improve it are developers. If the two departments are separate worlds, testing will always be a chore for developers, something that happens once the real work is done. And code is going to be a foreign country for testers. Everyone annoys each other, nobody is happy, and tests do very little to prevent system rot.
The thing is, developers do care about writing modular code. There is no fundamental conflict here. It's just that testers need to know how to "speak code," developers need to write tests, and both of them need to talk to each other. It's important to share expertise and have software and QA engineers participate in decisions. This can be done through code reviews and meetings - you can learn each other's practices and things that annoy the other team. There are also the RFCs we've just talked about — as a dev, write down what you're planning to do before you do it, and request comments from other teams; if there is no issue, this won't take up much time, but if QA has other ideas, you might want to hear them before getting elbow-deep in code. In any case, you'll have a record of your thought process for the future, which means it's less likely your code will become legacy.
Having a well-structured pyramid of tests requires the same things — proper communication and QA being everyone's concern. Let's talk about excessive test coverage. Of course, an individual programmer or tester can write too many tests all by themself — but very often, excessive coverage masks poor team structure and lack of expertise sharing. Say a developer has written a new piece of code. They'll also write unit tests for that code if they're diligent. Then, the testers will add integration and API tests on top of that. The unit test might already have checked all the corner cases and such in the new function, but the tester doesn't know about that, so they will redo all that work in their own tests. And then, as a final layer, you've got the end-to-end tests, which call everything from start to finish. In the end, the function gets called a dozen times every test run.
And what if we need to change that function? If its correct behavior changes, each of the dozen tests that cover it must also be changed. And, of course, you'll forget one or two tests, and they will fail, and the tester who gets the failed result probably won't know why this happened etc., etc. And if the automated testers are a separate team, who also don't know anything about what the other team is doing, the problems multiply again. A personal bugbear of ours is tickets that say — hey, we've got some changes in the code, so please change the tests accordingly. And you'll be lucky if the ticket arrives before the test suite has run and failed because of the changes.
This example shows how poor team structure and lack of visibility into each other's work can lead to cumbersome code (in this case, tests) that increases the cost of change.
Conclusion
Legacy code isn't a result of some accidental event, like a programmer leaving or technology becoming deprecated. A lot of software starts out in the head of one individual; if it's used, it inevitably outgrows that head. A large enterprise or public project might have millions of lines of code (e.g., in 2020, the size of Linux's kernel was 27.8 million lines of code). It doesn't matter how big your head is or how much you care; no single programmer can ever keep that much knowledge in. Legacy code is what you get when the hobby project approach is applied to large systems. The only way such a system doesn't collapse is if you use tools to control it and to share your knowledge with your peers. Automated tests are among the best tools for that purpose.
A well-written test base will promote sound code structure, keep a record of how the code should be used, and help you improve design without affecting functionality. All of this goes towards one thing: reducing the cost and risk of change and thus preventing your code from becoming legacy. Providing such a test base isn't a job for one person (although individual responsibilities and habits are important building blocks). It is the responsibility of the team and should be part of deadline estimations. And finally, the team itself should have clear channels of communication. They should be able to talk about the code with each other. This is how code can make a healthy journey from a vision in the head of its creator to a large system supported by a team or a community.
Published at DZone with permission of Mikhail Lankin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments