Persistent Memory for AI Agents Using LangChain's Deep Agents
Most AI agents forget you when the session ends. deepagents fixes that — persistent per-user memory across sessions, no vector database.
Join the DZone community and get the full member experience.
Join For FreeAI agents have a memory problem. Not the kind that we all hear daily — hallucination, wrong answers, but a much quieter and fundamental problem. When you start a new conversation with the agent, it forgets who you are. It doesn't know what you have already worked on, what you have clarified multiple times across sessions, or what is common across all the sessions. You start from scratch every single time.
While this does sound good in a way, in case you weren't getting what you wanted out of the agent, it does pose some challenges. LLMs are capable of maintaining a rich context of a conversation. The problem is more architectural: most of the agents designed the scope to include all state files, memory, and history into a single thread. When that thread ends, so does the state. This results in an intelligent agent but amnesiac across sessions.
LangChain's deepagents have a solution with three components that work together:
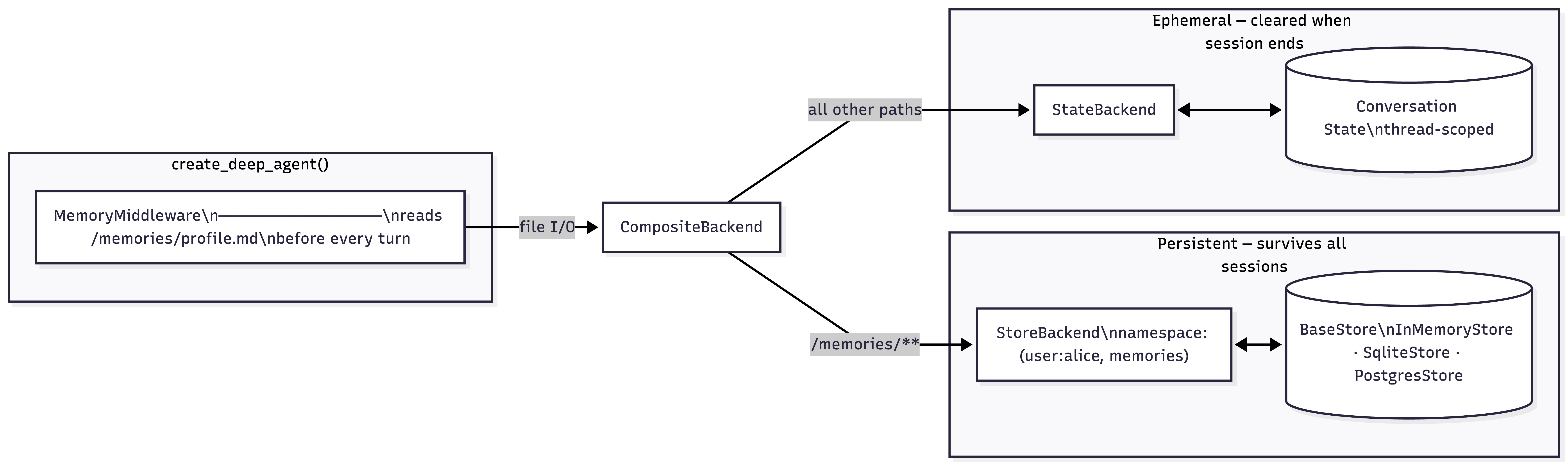
- StoreBackend – stores files outside the conversation thread in LangGraph's BaseStore
- CompositeBackend – routes specific file paths to persistent storage while also keeping everything else ephemeral
- MemoryMiddleware – loads memory into the agent's context automatically before any run.
By the end of this article, you will learn how to create a working personal assistant remembering your preferences, provides feedback across sessions, has per-user isolation, and a clear path from local SQLite to production Postgres.
Why Persistent Memory Matters for AI Agents
Consider a case of a customer support agent. A customer chats with the agent, and just like how they converse with a normal human, they try to bring up something that they brought up during the last conversation, but the agent has no idea about this. This creates friction and a poor user experience. There are other such scenarios, like a coding assistant that does not remember your team's conventions and coding patterns and gives generic answers, or a personal assistant that asks for your timezone every time the agent is asked to schedule a meeting.
LangChain's deepagents approach is notable because it doesn't require a vector database, an embeddings pipeline, or any kind of retrieval step at query time. Memory is a pure file. Loading memory means reading a file. Agent updates it the same way it edits any file, just like a human. The complexity comes in the routing and persistence layer, which CompositeBackend and Storebackend handle independently of the agentic loop.
The Problem
Conversations are stateless by default. In deep agents, every file that the agent reads or writes goes through a backend. The default is StateBackend. This stores files inside the LangGraph conversation state, which is scoped to a thread_id.
Starting a new conversation? new thread_id. New state. Files gone. The fix requires separating two distinct storage concerns:
- Working files, scratch notes -> scope is usually session -> this shouldn't be in the memory.
- User profile, preferences -> this is scoped at the user level -> this should survive in the memory.
Deepagents handles this with three cooperating primitives: StoreBackend, CompositeBackend, and MemoryMiddleware, and there are two storage primitives -> conversation thread, which is scoped to thread_id, and BaseStore, which is a key-value store that exists independently of threads.
StateBackend reads and writes from the conversation state. StoreBackend reads and writes from BaseStore. The key difference is where the agent reads from.
Setting Up the Persistent Memory Assistant
Installation
uv add deepagents langchain-anthropic langgraph
Backend Wiring
from deepagents.backends.composite import CompositeBackend
from deepagents.backends.state import StateBackend
from deepagents.backends.store import StoreBackend
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
store_backend = StoreBackend(
store=store,
namespace=lambda rt: (f"user:{user_id}", "memories"),
)
backend = CompositeBackend(
default=StateBackend(),
routes={"/memories/": store_backend},
) The namespace lambda is what can isolate users. Consider a case where there are two users: Alice and Bob. Alice's memory lives at ("user:alice", "memories") and Bob's at ("user:bob", "memories").
Agent Creation
from deepagents import create_deep_agent
from langchain_anthropic import ChatAnthropic
from langgraph.checkpoint.memory import InMemorySaver
agent = create_deep_agent(
model=ChatAnthropic(model="claude-sonnet-4-6"),
system_prompt=SYSTEM_PROMPT,
memory=["/memories/profile.md"],
backend=backend,
checkpointer=InMemorySaver(),
) The memory parameter is all MemoryMiddleware needs. It reads that path along with the configured backend. At the start of the session, the content is cached in state and is then injected into the system prompt before model calls within the session. If the file does not exist, then it injects "(no memory loaded)" so the agent knows to create a new one.
Architecture
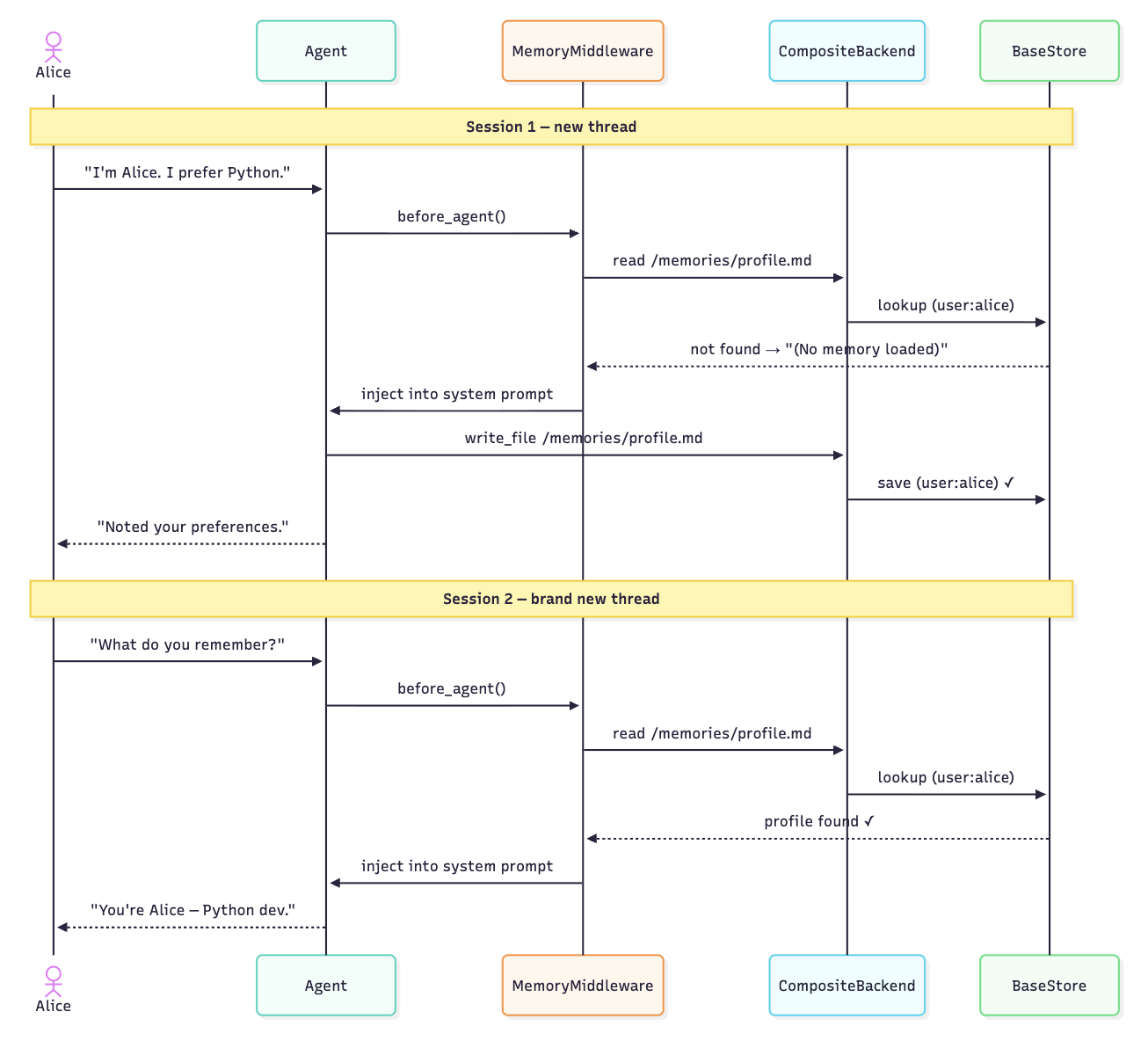
The System Prompt Contract
The agent needs to know when to update the memory and how to update this memory. The system prompt decides this contract:
SYSTEM_PROMPT = """You are a personal assistant with persistent memory.
Your persistent memory file lives at /memories/profile.md and survives
across all conversations.
When to update memory:
- User shares name, role, or background
- User mentions ongoing projects or goals
- User states a preference (language, tools, response format)
- User corrects you or gives explicit feedback
How to update:
- First conversation: write_file to create /memories/profile.md
- Later conversations: edit_file to update it
Keep the file concise — bullet points, not prose.
Never store credentials.
""" MemoryMiddleware also appends its own guidelines, which include heuristics for what not to save.
Multi-User Isolation
Now you might be wondering. Having this agent sounds amazing, but how to scale it for multiple people? Do we need to create separate instances for each user? The answer is no!. The namespace lambda is the only thing that separates users:
namespace=lambda rt: (f"user:{user_id}", "memories")
In the CLI, user_id is a flag. In LangGraph deployment, this can be derived from the request context.
namespace=lambda rt: (rt.server_info.user.identity, "memories")
Different Storing Backends
In this example, I experimented with in-memory store, SQLite, and PostgreSQL.
#In-memory (demos):
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
#Resets when the process exits. Good for demo runs.
#SQLite (local development, survives restarts):
import sqlite3
from langgraph.store.sqlite import SqliteStore
conn = sqlite3.connect("assistant_memory.db", isolation_level=None)
store = SqliteStore(conn)
store.setup()
#Note: isolation_level=None (autocommit) is required by SqliteStore.
#PostgreSQL (production, multi-instance):
import os
from langgraph.store.postgres import PostgresStore
with PostgresStore.from_conn_string(os.environ["DATABASE_URL"]) as store:
store.setup()
#Set DATABASE_URL to a standard Postgres connection string.
Advantages
LangChain's deepagents framework provides several advantages, such as:
- Cross-session continuity – memory injected into the system prompt directly - no search, no embedding lookup, no extra latency.
- Per-user isolation – easier namespacing using StoreBackend.
- Explicit, inspectable memory – it's a plain markdown file. You can read it, edit it, and audit it without any special tooling.
- Adaptable with existing middleware – MemoryMiddleware is part of the middleware stack along with permission checks and logging. Adding persistent memory is additive and not a total rewrite.
Disadvantages
While there are several advantages to using LangChain's deepagents, it does come with some limitations:
- Context window consumption – Since the memory files are injected into the system prompt every time, it could become really large, and it could exceed the context budget. The system prompt needs to be clear and concise on what to save and what not to save.
- Agent manages its own memory – A poorly prompted agent may over-save, under-save, or save the wrong things. The system prompt contract is very important.
- Not suitable for large-scale memory – For a compact user-profile, this sounds perfect — a few hundred words. But applications that need to remember several past interactions, a RAG-based approach with a vector store makes much more sense. It doesn't scale to large memory corpora.
Extending the Pattern
Multiple memory files — separate concerns:
memory=[
"/memories/profile.md", # identity and background
"/memories/projects.md", # active work
"/memories/preferences.md", # style and tool preferences
] Write-scoped permissions — prevent the agent from writing outside /memories/:
from deepagents import FilesystemPermission
permissions=[
FilesystemPermission(operations=["write"], paths=["/memories/**"]),
FilesystemPermission(operations=["write"], paths=["/**"], mode="deny"),
] Shared team context alongside per-user memory:
backend = CompositeBackend(
default=StateBackend(),
routes={
"/memories/": StoreBackend(store=store, namespace=lambda rt: (f"user:{user_id}", "memories")),
"/shared/": StoreBackend(store=store, namespace=("team:engineering", "shared")),
},
) Running the Example
git clone -b feat/permissions-execute-task https://github.com/NinaadRao/deepagents
cd examples/persistent-memory-assistant
uv venv && source .venv/bin/activate
uv pip install -e .
export ANTHROPIC_API_KEY=your_key
# Built-in two-session demo
python assistant.py --demo
# Interactive with SQLite persistence
python assistant.py --store sqlite --user alice "I prefer Python and FastAPI"
python assistant.py --store sqlite --user alice "What do you know about me?"
# Different user — isolated memory
python assistant.py --store sqlite --user bob "I build data pipelines in Spark"
python assistant.py --store sqlite --user alice "What do you know about me?" # Alice only Conclusion
Most agent memory problems trace back to two things: conversation and the user's context. Keeping them separate in the storage layer and not the application code is what makes the solution clean. The three-component design in deep agents, i.e., StoreBackend + CompositeBackend + MemoryMiddleware, handles this without coupling any layer to the others. You can change the model, store, or routing rules independently of each other, which makes it a good use case for abstraction.
Opinions expressed by DZone contributors are their own.
Comments