Less Frequently Used HTTP Methods
Understand less frequently used HTTP methods and their significance in advanced API development to enhance API functionality and efficiency.
Join the DZone community and get the full member experience.
Join For FreeUnderstanding less frequently used HTTP methods is crucial for comprehensive API development. While widely known methods like GET and POST form the foundation of web communication, there are specialized methods that are not as commonly used. These methods have specific purposes and cater to niche functionalities, resulting in their reduced popularity. However, comprehending these methods allows developers to unlock additional capabilities and offer advanced features in their APIs. By expanding knowledge beyond the commonly used methods, developers can optimize API design, make informed decisions for different operations, and cater to specific use cases and requirements, ultimately resulting in more versatile and powerful APIs.
HTTP functions: In Martini, your request's HTTP method can be set using the dropdown box near the text field for the URL. The supported methods are: GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS, and TRACE.
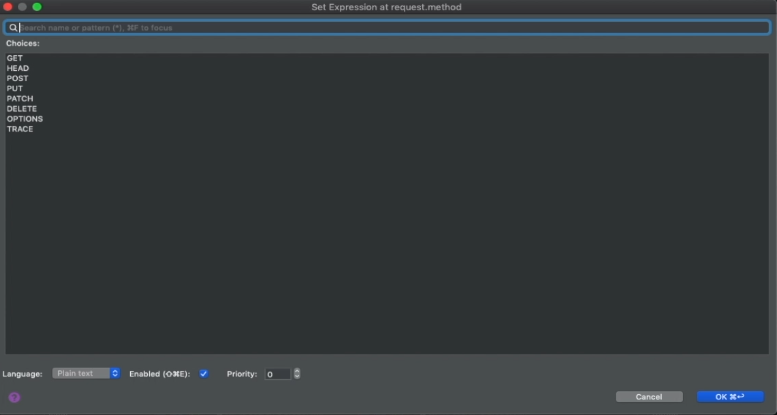
Screenshot of Martini showing supported HTTP methods
HEAD Method
The HEAD method is an HTTP method that is used to retrieve the headers of a resource without retrieving its actual content. When a client sends a HEAD request to a server, the server responds with only the headers of the requested resource, providing information such as the content type, content length, last modification date, and server-specific headers. The purpose of the HEAD method is to allow clients to obtain metadata about a resource, such as its size or availability, without the need to download the entire content. This can be useful in scenarios where the client wants to check if a resource has been modified since the last retrieval or to retrieve information about a resource before deciding whether to download it. By using the HEAD method, unnecessary data transfer can be avoided, improving efficiency and reducing bandwidth consumption.
The HEAD and GET methods in HTTP serve different purposes and provide distinct responses:
- GET is used to retrieve the complete content of a resource.
- HEAD is used to retrieve only the headers of a resource without fetching the content.
GET returns both headers and content, while HEAD returns only headers. GET is commonly used to display resource content, while HEAD is useful for obtaining metadata about a resource without downloading the entire content. GET requests can be cached for improved performance, whereas HEAD requests primarily cache headers and metadata.
The HEAD Method in HTTP Has Several Use Cases and Examples
Use Case 1: Checking Resource Availability
Example: A web crawler can send a HEAD request to check if a webpage has been modified since the last crawl by comparing the response headers (such as Last-Modified) with the previously stored values.
Use Case 2: Obtaining Resource Metadata
Example: A client application can send a HEAD request to retrieve metadata about a file, such as its size or MIME type, without downloading the entire file content.
Use Case 3: Monitoring Resource Health
Example: A monitoring tool can periodically send HEAD requests to verify the availability and responsiveness of a web server by checking the response status codes (e.g., 200 for OK or 404 for Not Found).
The HEAD method is primarily used for lightweight operations that require retrieving resource information without transferring the actual content.
PATCH Method
The PATCH method in HTTP is used to partially update a resource on a server. It allows clients to send only the changes or differences (the patch document) that need to be applied to the resource rather than sending the entire representation. This method is valuable for fine-grained updates, reducing data transfer, and minimizing conflicts when multiple clients modify the same resource. The PATCH method is commonly used in API development to update specific fields or properties of a resource while keeping the rest of it intact, providing a flexible and efficient way to modify resources.
PATCH and PUT methods are both used to update resources in HTTP, but they differ in their approach.
PATCH allows partial updates by sending only the changes to be applied, while PUT requires sending the complete updated representation, replacing the entire resource. PATCH is for partial updates, while PUT is for complete replacements.
Use Cases and Examples of the PATCH Method
Updating Specific Fields: PATCH is commonly used when you want to update specific fields of a resource without sending the entire representation. For example, if you have a user profile API, you can use PATCH to update only the user's email address or profile picture.
Example:
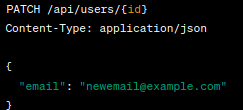
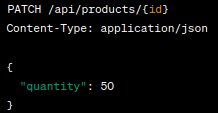
Delta Updates: PATCH is useful when you want to send only the changes made to a resource. This can be beneficial for large resources to minimize data transfer. For instance, if you have an inventory management system, PATCH can be used to update the quantity of a specific product.
Example:
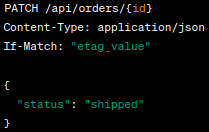
Conditional Updates: PATCH can be employed for conditional updates, where the update should occur only if certain conditions are met. This can be achieved using conditional headers like If-Match or If-Unmodified-Since.
Example:
OPTIONS Method
The OPTIONS method in HTTP is used to retrieve the available communication options for a specific resource. It allows clients to query the server and obtain information about supported methods, request/response formats, and other available options. By sending an OPTIONS request, clients can understand the capabilities and constraints of the server before making further requests. This method is valuable for creating self-descriptive and discoverable APIs, as it provides clients with the necessary information to interact effectively with the server.
Retrieving Information About a Resource Using OPTIONS:
The OPTIONS method in HTTP is used to retrieve information about a specific resource. By sending an OPTIONS request to a server, clients can obtain details about the available communication options for that resource. This includes information such as supported methods, request/response formats, and other available options. The server responds with an OPTIONS response, which provides the client with valuable insights into the capabilities and constraints of the server. This information enables clients to make informed decisions and interact effectively with the server.
Use Cases and Examples of the OPTIONS Method:
- Obtaining allowed methods: The OPTIONS method allows clients to retrieve a list of supported HTTP methods for a particular resource. Example: OPTIONS /api/users returns the allowed methods like GET, POST, and DELETE.
- CORS (Cross-Origin Resource Sharing): The OPTIONS method plays a crucial role in CORS by allowing the client to check if it is permitted to make a cross-origin request to a specific resource. Example: OPTIONS /api/data checks if the client's origin is allowed to access the /api/data resource.
- Server capabilities: OPTIONS can provide information about server capabilities or features, such as supported authentication mechanisms, supported content types, or available extensions. Example: OPTIONS /api returns server capabilities like supported authentication methods and supported media types.
- API discovery: OPTIONS can be used for discovering APIs by providing metadata about the available endpoints and their capabilities. Example: OPTIONS /api returns a list of available endpoints and their supported methods.
- Cache-control: OPTIONS responses can be used to determine cacheability of a resource or to obtain information about the freshness of cached data. Example: OPTIONS /api/resource provides cache-related headers like Cache-Control and Expires.
CONNECT Method
The CONNECT method in HTTP establishes a secure tunnel between a client and a destination server through proxies. It is primarily used to enable secure communication, particularly for HTTPS connections, by bypassing intermediaries and establishing direct, encrypted channels between clients and servers.
Establishing Network Connections Through a Proxy
The CONNECT method in HTTP is used to establish network connections through a proxy server. It allows clients to create a tunnel to a remote server, typically for secure communication purposes such as establishing HTTPS connections. Using the CONNECT method, clients can bypass intermediaries and establish direct connections to the destination server, enabling secure and private communication channels.
Use Cases and Examples of the CONNECT Method Include:
- Establishing secure connections: The CONNECT method is commonly used in HTTP proxies to establish secure connections between clients and remote servers. For example, when a client wants to establish an HTTPS connection to a server through a proxy, it can use the CONNECT method to create a tunnel and establish a secure channel.
- Proxying WebSocket connections: WebSocket is a communication protocol that allows full-duplex communication between a client and a server over a single TCP connection. The CONNECT method can be used to proxy WebSocket connections through a proxy server, enabling bidirectional communication between the client and the server.
- Tunneling other protocols: The CONNECT method can be used to tunnel other protocols through a proxy server. It allows clients to establish connections for protocols such as FTP, SMTP, or even custom protocols by creating a tunnel between the client and the server.
Example:
To establish an HTTPS connection through a proxy server using the CONNECT method, a client sends an HTTP request to the proxy server with the target server's hostname and port number in the request line. For instance:

Upon successful establishment of the tunnel, the proxy server responds with an HTTP 200 OK status code, indicating that the tunnel is established. Subsequently, the client can start sending encrypted data through the tunnel, enabling secure communication with the target server.
TRACE Method
The TRACE method in HTTP is used to retrieve the current state or track the path of a request message as it travels through intermediaries, such as proxies or gateways, to the destination server. It enables clients to see what modifications, if any, are made to the request by intermediaries along the way. The purpose of the TRACE method is primarily for diagnostic or debugging purposes, allowing developers to analyze and troubleshoot the behavior of their requests and identify any changes or issues introduced by intermediaries in the network.
Retrieving Diagnostic Traces for Debugging Purposes
The TRACE method in HTTP serves as a tool for retrieving diagnostic traces that can be helpful in debugging and troubleshooting applications. It allows a client to send a TRACE request to a server, which then responds by echoing back the received request in the response body. This enables developers to examine the request as it traverses through different network intermediaries, such as proxies or gateways. By analyzing these traces, developers can gain insights into how the request is being processed, any modifications introduced by intermediaries, and identify potential issues or unexpected behavior. This information is valuable for diagnosing and resolving problems related to request handling, identifying modifications made by intermediaries, and gaining a better understanding of the request-response cycle.
Use Cases and Examples of the TRACE Method
Here are some use cases and examples of the TRACE method in HTTP:
- Request Inspection: The TRACE method can be used to inspect the characteristics of a request as it traverses through different proxies and gateways. It helps in understanding how the request is modified or affected by intermediaries.
- Debugging and Troubleshooting: Developers can use the TRACE method to gather diagnostic information for debugging and troubleshooting purposes. By examining the echoed request in the response body, they can identify issues such as header modifications, parameter encoding, or intermediary misconfigurations.
- CORS (Cross-Origin Resource Sharing) Testing: When dealing with cross-origin requests, the TRACE method can be used to verify the CORS configuration of a server. It helps in determining whether the requested resource is accessible from the client's domain or if any CORS-related restrictions are in place.
- Security Analysis: The TRACE method can be employed to assess the security of an application or server configuration. It helps in identifying potential vulnerabilities, such as cross-site scripting (XSS) or cross-site tracing (XST), where sensitive information might be exposed through echoed requests.
Example:
To illustrate the use of the TRACE method, consider a scenario where a client sends a TRACE request to a server:

![]()
The server then responds by echoing back the received request in the response body:

![]()
The client can analyze the echoed request to gain insights into the request handling process, any modifications made by intermediaries, and other relevant diagnostic information.
COPY Method
The COPY method is an HTTP method that is used to create a copy of a resource at a specified destination. It allows clients to duplicate resources on the server side. The purpose of the COPY method is to provide a standardized way of copying resources in a web environment. It is particularly useful in scenarios where creating a copy of a resource is required, such as when implementing versioning systems or performing backups. The COPY method is defined in the WebDAV (Web Distributed Authoring and Versioning) protocol extension to HTTP.
Creating Copies of Resources on the Server
The COPY method in HTTP is designed to enable the creation of duplicate resources on the server. It provides a way for clients to make exact copies of existing resources and save them to a specified location. This method is particularly useful in situations where the replication of resources is required, such as when creating backups, implementing versioning systems, or facilitating content distribution. The COPY method is part of the WebDAV (Web Distributed Authoring and Versioning) protocol, which extends the functionality of HTTP to support advanced web applications and collaborative environments.
Use Cases and Examples of the COPY Method
Here are some use cases and examples of the COPY method in HTTP:
- Backup and Archiving: The COPY method allows clients to create backups of important resources on the server. For example, a content management system may use the COPY method to duplicate files or documents periodically for backup purposes.
- Version Control: The COPY method can be used to implement version control systems. Clients can create copies of resources to capture different versions or revisions of a document, allowing for easy retrieval and comparison of historical versions.
- Content Distribution: The COPY method enables the distribution of content across different servers or locations. For instance, a web application may use the COPY method to replicate media files or templates to multiple servers for efficient content delivery.
Example:
![COPY]()
In this example, the client sends a COPY request to copy the resource located at "/source/resource" to the destination path "/destination/resource" on the server. The server will create a duplicate of the resource at the specified destination.
LOCK and UNLOCK Methods
The LOCK and UNLOCK methods are part of the WebDAV (Web Distributed Authoring and Versioning) extension to HTTP and are used for resource locking and unlocking. Here's a brief explanation of their definition and purpose:
LOCK Method
The LOCK method is used to acquire an exclusive lock on a resource, preventing other clients from modifying it concurrently. By locking a resource, a client can ensure exclusive access for performing operations such as editing or updating the resource. Locks can be either shared (allowing multiple clients to have read access) or exclusive (restricting both read and write access to other clients).
UNLOCK Method
The UNLOCK method is used to release a lock previously acquired on a resource. When a client no longer requires exclusive access to a resource, it can send an UNLOCK request to release the lock. This allows other clients to obtain locks and modify the resource.
The LOCK and UNLOCK methods are primarily used in collaborative environments where multiple clients or users need controlled access to shared resources. They enable synchronization and coordination between clients to prevent conflicting modifications to the same resource.
It's important to note that the LOCK and UNLOCK methods are specific to WebDAV-compliant systems and may not be supported by all servers or APIs that adhere to standard HTTP.
Resource Locking and Unlocking Mechanisms
Resource locking and unlocking mechanisms manage concurrent access to shared resources. They ensure exclusive access to a resource for critical operations and allow concurrent read-only access. Time-based locks automatically release after a specified period. Different levels of granularity, such as file-level or record-level locking, can be used. Deadlock detection and resolution mechanisms handle potential deadlocks. These mechanisms maintain data integrity and enable concurrent resource access.
Use Cases and Examples of the LOCK and UNLOCK Methods
Use cases and examples of the LOCK and UNLOCK methods are as follows:
- Collaborative Editing: In scenarios where multiple users collaborate on a document or resource, the LOCK method can be used to acquire an exclusive lock on the resource while editing. This ensures that only one user can modify the resource at a time, preventing conflicts and data inconsistencies. Once the editing is complete, the user can release the lock using the UNLOCK method, allowing others to acquire the lock and make their modifications.
- Version Control: The LOCK and UNLOCK methods can be used in conjunction with version control systems. When a user wants to make changes to a version-controlled resource, they can lock the resource to indicate their intent to modify it. This prevents others from modifying the resource until the lock is released. Once the changes are made, the user can unlock the resource, allowing others to apply their changes or check out a different version.
- Concurrent Access Management: The LOCK and UNLOCK methods can be utilized to manage concurrent access to resources in distributed systems. For example, in a distributed file system, a client can lock a file while performing a critical operation, such as copying or moving it. This ensures that other clients or processes do not interfere with the operation until the lock is released.
Example:
LOCK /documents/report.doc HTTP/1.1
Host: example.com
User-Agent: MyClientApp
Authorization: Bearer <access_token>In this example, a client is acquiring a lock on the "report.doc" document hosted on "example.com." The request includes the necessary headers, such as User-Agent and Authorization, to identify and authenticate the client. Upon successful locking, the server may respond with a "200 OK" status code.
UNLOCK /documents/report.doc HTTP/1.1
Host: example.com
User-Agent: MyClientApp
Authorization: Bearer <access_token>In this example, the client is releasing the previously acquired lock on the "report.doc" document. The server responds with a "204 No Content" status code to indicate a successful unlock operation.
It's important to note that the availability and support for the LOCK and UNLOCK methods may vary depending on the server or API implementation.
Three Main Factors To Consider When Deciding To Use Less Frequently Used Methods
When deciding to use less frequently used methods in HTTP, there are three main factors to consider:
- Functionality Requirements: Evaluate whether the functionality provided by the less frequently used method aligns with your specific use case. Each method has its own purpose and behavior, so it's important to understand how it differs from commonly used methods like GET or POST. Assess if the less commonly used method offers the necessary capabilities to achieve your desired outcome.
- Server and Client Support: Check the level of support for the less frequently used method in both the server and client components of your application. Ensure that the server you are using supports the method and that it won't cause compatibility issues with client applications. Additionally, consider the broader ecosystem and libraries you are using, as they may have limitations or lack support for less commonly used methods.
- Security and Performance Implications: Understand the security and performance implications of using less frequently used methods. Some methods may introduce potential vulnerabilities if not properly implemented or secured. Additionally, consider the impact on performance, as less commonly used methods might have additional overhead or limitations that could affect the overall performance of your application. Evaluate whether the benefits of using the method outweigh any potential risks or drawbacks.
By considering these factors, you can make an informed decision about whether to utilize less frequently used HTTP methods in your application, ensuring they align with your requirements, are well-supported, and offer the necessary security and performance considerations.
Benefits and Drawbacks of These Methods in API Development
When using less frequently used HTTP methods in API development, there are several benefits and drawbacks to consider:
Benefits
- Enhanced Functionality: Less commonly used methods, such as PATCH, OPTIONS, or COPY, can provide specific functionality that may be necessary for certain use cases. They allow for more fine-grained control over the API's behavior and can enable operations that are not possible with standard methods like GET or POST.
- RESTful Design: Utilizing less frequently used methods can help adhere to the principles of REST (Representational State Transfer) architecture. These methods provide specialized actions for manipulating resources, promoting a more semantic and intuitive API design.
- Reduced Network Traffic: Some less commonly used methods, like HEAD or OPTIONS, allow clients to retrieve only metadata or available actions without fetching the entire resource. This can lead to reduced network traffic and improved performance, especially in scenarios where retrieving the full resource is unnecessary.
Drawbacks
- Limited Client Support: Not all client applications or libraries may support less frequently used methods. This can introduce compatibility issues and limit the potential audience for your API. It's crucial to ensure that the clients consuming your API can properly handle and interpret these methods.
- Complexity and Learning Curve: Working with less commonly used methods may introduce additional complexity, both in terms of implementation and understanding. Developers and API consumers need to familiarize themselves with the specific behavior and nuances of these methods, which can increase the learning curve and potentially impact development time.
- Security Considerations: Some less frequently used methods, like CONNECT or TRACE, may pose security risks if not implemented and secured correctly. These methods can expose sensitive information or introduce vulnerabilities if used improperly. It's essential to thoroughly understand and mitigate any security risks associated with these methods.
Overall, the benefits of using less frequently used methods in API development lie in their enhanced functionality, adherence to REST principles, and potential performance improvements. However, it's crucial to carefully evaluate the drawbacks, such as limited client support, increased complexity, and security considerations, to ensure that the use of these methods aligns with your specific requirements and constraints.
Five Security Considerations and Best Practices for Using These Methods
- Authentication and Authorization: Implement robust authentication mechanisms, such as API keys, OAuth, or JWT, to ensure that only authorized users can access and use the less frequently used methods.
- Input Validation and Sanitization: Validate and sanitize all user inputs to prevent injection attacks and ensure that malicious data cannot compromise the API or server.
- Role-Based Access Control: Define and enforce granular access control policies based on user roles and permissions. Limit access to sensitive methods to authorized users or administrators only.
- Rate Limiting and Throttling: Implement rate limiting and throttling mechanisms to prevent abuse and protect against Denial of Service (DoS) attacks. Limit the number of requests per user or IP address within a specified time frame.
- Logging and Monitoring: Enable comprehensive logging and monitoring of API activities, including requests made using less frequently used methods. This allows for early detection of suspicious activities, troubleshooting, and auditing.
By adhering to these security considerations and best practices, you can mitigate potential risks associated with using less common methods and ensure the integrity and security of your API.
Embrace the Power of Less Common HTTP Methods and Enhance API Flexibility and Efficiency
This section covered several less frequently used HTTP methods, including HEAD, PATCH, OPTIONS, CONNECT, TRACE, COPY, LOCK, and UNLOCK. Understanding these methods is crucial for advanced API development as they provide additional functionalities and flexibility in interacting with resources on the server. While these methods may not be used as frequently as GET and POST, they offer specific advantages in certain scenarios.
By familiarizing yourself with these methods, you can expand your toolkit for building robust and efficient APIs. Additionally, having knowledge of these methods allows you to leverage their capabilities in various use cases, such as retrieving metadata, performing partial updates, debugging, copying resources, managing resource locks, and more.
Overall, incorporating less frequently used methods into your API development enables you to design more sophisticated and versatile APIs, enhancing the user experience and providing more efficient data exchange between clients and servers.
Opinions expressed by DZone contributors are their own.
Comments