The Power of LLMs in Java: Leveraging Quarkus and LangChain4j
This post attempts to demystify the use of LLMs in Java, with Quarkus and LangChain4j, across a ludic and hopefully original project.
Join the DZone community and get the full member experience.
Join For FreeSince its public release in November 2022, ChatGPT continues to fascinate millions of users, raising their creative power while, at the same time, catalyzing tech enthusiasts and their attention on its possible drawbacks, or even weaknesses.
ChatGPT, and similar chatbots, are a special type of software called large language models (LLMs) that have dramatically metamorphosed the natural language processing (NLP) field in order to provide newer and less common tasks like question answering, text generation and summarization, etc. All these terms really sound very complicated and, while it's a long way from this post's ambitions to elucidate the LLM's quantum leap, we're trying to look here at how they work and, specifically, how could they be used in Java, highlighting their compelling possibilities, as well as some potential problems. Let's go!
A Brief History of LLMs
NLP refers to building machines that are able to recognize, understand, and generate text in human languages. It might sound like a new technology to many of us, but it's actually as old as computers themselves. As a matter of fact, automatically translating one human language to another was the dream of any programmer at the beginning of the information age.
In 1950, Alan Turing published a paper stating that a machine could have been considered as "intelligent" if it could produce responses indistinguishable from those of a human. This method, called the Turing test, is now considered an incomplete case of the allegedly machines' "intelligence," since it's easily passed by modern programs, which are created to mimic human speech.
The first NLP programs have adopted a simple approach of using sets of rules and heuristics in order to imitate conversations. In 1966, Joseph Weizenbaum, professor at MIT, released the first chatbot in history, Eliza. Based on common language pattern matching, this program created the illusion of a conversation by asking open-ended questions and giving generic responses, like "Please go on," to sentences that it didn't "understand."
Over the next several decades, rules-based text parsing and pattern matching remained the most common NLP approach. By the 1990s, an important paradigm shift had taken place in NLP, consisting of replacing rule-based methods with statistical ones. As opposed to the old models trying to define and construct grammar, the new ones were designed to "learn" language patterns through "training." Thousands of documents were now being used to feed data to NLP programs in order to "teach" them a given language model. So, people started to "train" programs for text generation, classifications, or other natural language tasks, and in the beginning, this process was based on input sequences that the model was splitting into tokens, typically words or partial words, before being converted into the associated mathematical representation given by the training algorithm. Finally, this particular representation was converted back into tokens to produce a readable result. This back-and-forth tokenization process is called encoding-decoding.
In 2014, NLP researchers found another alternative to this traditional approach of passing sequences through the encoder-decoder model, piece by piece. The new approach, which was called attention, consisted of having the decoder search the full input sequence and trying to find the pieces that were the most relevant from the language model point of view. A few years later, a paper titled Attention Is All You Need was published by Google. It showed that models based on this new principle of attention were much faster and parallelizable. They were called transformers.
Transformers marked the beginning of LLMs because they made it possible to train models of much larger data sets. In 2018, OpenAI introduced the first LLM called Generative Pre-Trained Transformers (GPT). This LLM was a transformer-based one that was trained using a massive amount of unlabeled data and then could be fine-tuned to specific tasks, such as machine translation, text classification, sentiment analysis, and others. Another LLM introduced this same year, BERT (Bidirectional Encoder Representation Transformer), by Google, used an even larger amount of training data, consisting of billions of words and more than 100 million of parameters.
Unlike previous NLP programs, these LLMs aren't intended to be task specific. Instead, they are trained simply to predict the token that fits the best given the model's particular context. They are applied to different fields and are becoming an integral part of our everyday lives. Conversational agents, like Siri from Apple, Alexa from Amazon, or Google Home, are able to listen for queries, turn sounds into text, and answer questions. Their general purpose and versatility result in a broad range of natural language tasks, including but not limited to:
- Language modeling
- Question answering
- Coding
- Content generation
- Logical reasoning
- Etc.
Conversational LLMs
The LLMs' undertaking consists in their capacity to generate text, in a highly flexible way, for a wide range of cases, which makes them perfect in talking to humans. Chatbots are LLMs specifically designed for conversational use. ChatGPT is the most well-known, but there are many others like:
- Bard from Google
- Bing AI from Microsoft
- LLaMa from Meta
- Claude from Anthropic
- Copilot from GitHub
- Etc.
Embedded in enterprise-grade applications, conversational LLMs are ideal solutions in fields like customer service, education, healthcare, web content generation, chemistry, biology, and many others. Chatbots and virtual assistants can be powered by being given access to conversational LLM capabilities. This kind of integration of LLMs in classical applications requires them to expose a consistent API. And in order to call these APIs from applications, a toolkit is required, which is able to interact with the AI model and facilitate custom creation.
LLM Toolkits
There have been so many rapid developments in AI since ChatGPT hit the scene, and among all these new tools, LLM toolkits have seen a veritable explosion. Some of the most known, like AutoGPT, MetaGPT, AgentGPT, and others, have attempted to jump on the bandwagon and strike while the iron was hot. But there is no doubt that the one which emerged as the most modern and, at the same time, the most discussed, is LangChain. Available in Python, JavaScript, and TypeScript, LangChain was launched in 2022 as an open-source library, originally developed by Harrison Chase, which shortly after its inception, turned out to be one of the fastest-growing projects in the AI space.
But despite its growing popularity, LangChain had a major drawback: the lack of Java support. So in order to address this drawback, LangChain4j emerged in early 2023 as the Java implementation of the LangChain Python library. In the demonstration below, we will use LangChain4J to implement enterprise-grade Java services and components powered by the most dominant and influential LLMs.
The Project
In order to illustrate our discourse, we'll be using a simple Java program that performs a natural language task. The use case that we chose for this purpose is to implement an AI service able to compose a haiku. For those who don't know what a haiku is, here is the Britannica definition:
"Unrhymed poetic form consisting of 17 syllables arranged in three lines of 5, 7, and 5 syllables respectively."
As you can see, the usefulness of such a task isn't really striking and, as a matter of fact, more than a veritable use case, it's a pretext to demonstrate some LangChain4j features, while using a ludic and hopefully original form.
So, our project is a maven multi-module project having the following structure:
- A master POM named
llm-java - A JAX-RS module, named
haiku, exposing a REST API which invokes the LLM model - An infrastructure module, named
infra, which creates the required Docker containers
The Master POM
Our project is a Quarkus project. Hence, the use of the following Bill of Material (BOM) is as follows:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-bom</artifactId>
<version>${quarkus.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>It uses Quarkus 3.8.3, Java 17, and LangChain4j 0.25.0.
The JAX-RS Module
This module, named haiku, is using the quarkus-resteasy-reactive-jackson Quarkus extension in order to expose a REST API:
@Path("/haiku")
public class HaikuResource
{
private final HaikuService haikuService;
public HaikuResource(HaikuService haikuService)
{
this.haikuService = haikuService;
}
@GET
public String makeHaiku(@DefaultValue("samurai") @RestQuery String subject)
{
return haikuService.writeHaiku(subject);
}
}As you can see, this API defines an endpoint listening for GET HTTP requests, accepting the haiku subject as a query parameter, which containers the default value: "samurai." The module also uses the quarkus-container-image-jib Quarkus extension to create a Docker image that runs the AI service. The attributes of this Docker image are defined in the application.properties file, as shown below:
...
quarkus.container-image.build=true
quarkus.container-image.group=quarkus-llm
quarkus.container-image.name=haiku
quarkus.jib.jvm-entrypoint=/opt/jboss/container/java/run/run-java.sh
...These attributes state that the newly created Docker image name will be quarkus-llm/haiku and its entrypoint will be the run-java.sh shell script located in the container's /opt/jboss/container/java/run directory.
This project uses the Quarkus extension quarkus-langchain4j-ollama, which provides integration with the LangChain4j library and the Ollama tool. Ollama is an advanced AI streamlined utility that allows users to set up and run locally large LLMs, like openai, llama2, mistral, and others. Here, we're running llama2 locally. This is configured again in the application.properties using the following statement:
quarkus.langchain4j.ollama.chat-model.model-id=llama2:latestThis declaration states that the LLM used here, in order to serve AI requests, will be llama2 for its last version. Let's have a look now at our AI service itself:
@RegisterAiService
public interface HaikuService
{
@SystemMessage("You are a professional haiku poet")
@UserMessage("Write a haiku about {subject}.")
String writeHaiku(String subject);
}And that's it! As you can see, our AI service is an interface annotated with the @RegisterAiService annotation. The annotation processor provided by the Quarkus extension will generate the class that implements this interface. In order to be able to serve requests, any conversational LLM needs a defined context or scope.
In our case, this scope is the one of an artist specialized in composing haikus. This is the role of the @SystemMessage annotation: to set up the current scope. Last but not least, the @UserMessage annotation allows us to define the specific text that will serve as a prompt to the AI service. Here, we're requesting our AI service to compose a haiku on a topic that is defined by the input parameter subject of type String.
The Infrastructure Module
After having examined the implementation of our AI service, let's see how could we set up the required infrastructure. The infrastructure module, named infra, is a maven sub-project using the docker-compose utility to start the following Docker containers:
- A Docker container named
ollamais running an image taggednicolasduminil/ollama:llama2. This image is simply the official Ollama Docker image, which has been augmented to include thellama2LLM. As explained earlier, Ollama is able to locally run several LLMs, and in order to make these LLMs available, we need to pull them from their Docker registries. This is why, when running the Ollama official Docker container, one typically needs to pull the chosen LLM. In order to avoid this repetitive operation, I have extended this official Docker container to already include thellama2LLM. - A Docker container named
haikuis running the image taggedquarkus-llm/haiku, which is precisely our AI service.
Here is the associated docker-compose.yaml file required to create the infrastructure described above:
version: "3.7"
services:
ollama:
image: nicolasduminil/ollama:llama2
hostname: ollama
container_name: ollama
ports:
- "11434:11434"
expose:
- 11434
haiku:
image: quarkus-llm/haiku:1.0-SNAPSHOT
depends_on:
- ollama
hostname: haiku
container_name: haiku
links:
- ollama:ollama
ports:
- "8080:8080"
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jarAs you can see, the ollama service runs on a node having the DNS name of ollama and listens on the TCP port number 11434. Our AI service, hence, needs to be configured appropriately to connect to the same node/port. Again, its file application.properties is used for this purpose, as shown below:
quarkus.langchain4j.ollama.base-url=http://ollama:11434This declaration means that our AI service will send its requests to the URL: http://ollama:11434, where ollama is converted by the DNS service into the IP address, which was allocated to the Docker container with the same name.
Running and Testing
In order to run and test this sample project, you may proceed as follows:
Clone the repository:
Shell$ git clone https://github.com/nicolasduminil/llm-java.gitcdto the project:Shell$ cd llm-javaBuild the project:
Shell$ mvn clean installCheck that all the required containers are running:
Shell$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 19006601c908 quarkus-llm/haiku:1.0-SNAPSHOT "/opt/jboss/containe…" 5 seconds ago Up 4 seconds 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp haiku 602e6bb06aa9 nicolasduminil/ollama:llama2 "/bin/ollama serve" 5 seconds ago Up 4 seconds 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp ollamaRun the open-api interface to test the service. Fire your preferred browser at: http://localhost:8080/q/swaggerui. In the displayed Swagger dialog labeled
Haiku API, click on theGETbutton and use theTry itfunction to perform tests. In the text field labeledSubject, type the name of the topic in which you want our AI service to compose a haiku or keep the default one, which issamurai. The figure below shows the test result:
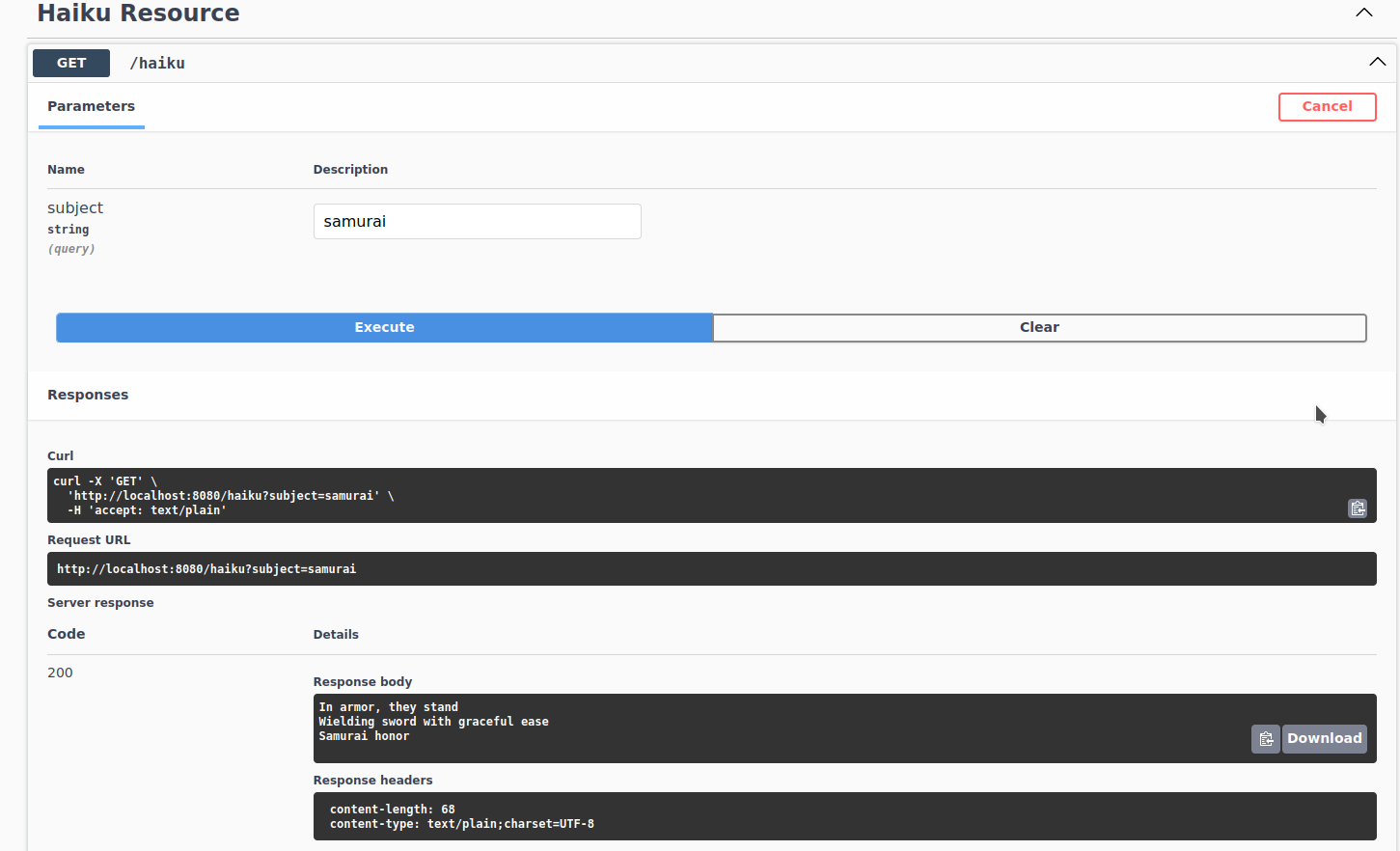
You can also test the project by sending a GET request to our AI service using the curl utility, as shown below:
$ curl http://localhost:8080/haiku?subject=quarkus
Quarkus, tiny gem
In the cosmic sea of space
Glints like a starWrapping Up
In the demonstration above, we explored the history of LLMs and used LangChain4J to implement enterprise-grade Java services and components powered by the most dominant and influential LLMs.
We hope you enjoyed this article on LLMs and how to implement them in the Java space!
Opinions expressed by DZone contributors are their own.
Comments