Using LLMs to Automate Data Cleaning and Transformation Pipelines
Data cleaning is brittle and time-consuming; LLMs introduce a semantic layer that makes workflows more resilient and easier to maintain.
Join the DZone community and get the full member experience.
Join For FreeA new paradigm, not a replacement of data engineering, but a fundamental shift in where engineering effort concentrates.
If you were to ask a data engineer about their week, I am sure they would not speak about anything exciting. Most of their time is spent on data wrangling, messy upstream data, inconsistent date formats, null values that are not really null, and vendor exports that rename columns without noting those changes in the documentation. These are the kinds of data engineering tasks that nobody actually wants to do, yet they end up occupying the majority of their week.
The classical approaches to data engineering, like schema validation, manually coded transforms, and algorithmic outlier detection, are good but reactive to change. As a consequence, pipeline crisis management is an endless priority for senior engineering roles, and valuable analytical work is pushed down the queue.
The new paradigm of large language models is not a data processing engine. Instead of Spark and dbt, we still perform that. It acts as a kind of intelligent coordination layer that knows data in terms of meaning, not merely structure. In this article, we explain what that looks like, the relevant scope, and how to implement it in runnable form.

An LLM would analyze a column labeled "rev_usd" containing entries like 1200.5, -1, and “n/a” and assume that this column represents revenue in US currency, that -1 is perhaps a sentinel value, and that “n/a” is a representation of missing data. It would do this without any prior rules being written. LLMs also have the unique ability to generate the appropriate cleaning code. LLMs can also generate code-cleaning data and respond with a justification in plain English. This is something that cannot be done with a regex that identifies patterns and captures generic null representations.
An LLM would analyze a column labeled "rev_usd" containing entries like 1200.5, -1, and “n/a” and assume that this column represents revenue in US currency, that -1 is perhaps a sentinel value, and that “n/a” is a representation of missing data. It would do this without any prior rules being written. LLMs also have the unique ability to generate the appropriate cleaning code. LLMs can also generate code-cleaning data and respond with a justification in plain English. This is something that can’t be done by a regex that is able to identify patterns and capture generic null representations.
The 4 Integration Points That Actually Matter
LLMs can't be used generically or to replace ETL. They have high latency and high costs, and the results are not deterministic. The best approach is a surgical one: use them in the four areas that clearly show semantic comprehension that is superior to anything that could be described using a rules-based approach.
1. In the area of schema inference and mapping, LLMs can be used to provide a raw CSV or JSON document and can, without any field documentation, provide column semantics, suggest appropriate data types, and provide a mapping to the canonical target schema. This is the arena in which time savings can be best realized. A new vendor integration that previously required a data engineer to spend half a day can now be completed in seconds.
2. Generation of transformation code. Engineers write a cleaning rule for the LLM, which generates code for Pandas or SQL, including unit tests and comments. This output is a code artifact subject to version control, code review, and execution on your own infrastructure, plus the associated costs of a hot-path black-box API call to your service.
3. Anomaly classification with contextual awareness. The rule engines fail to classify the values of “-1,” "unknown", or “0” — these can be missing data, sentinel values, or legitimate records. LLMs consider the context and reasoning, which helps eliminate quality alert false positives.
4. Automated documentation and flow narration. With LLMs, documenting the transformations and the reasons for the changes becomes trivial, greatly improving the maintenance of the pipelines. For organizations with high engineering turnovers or complicated compliance requirements, this alone justifies the integration cost.
Reference Architecture
Permitting any leeway on operational constraints is impossible: LLMs will never interact with complete production datasets. These models will only ever use metadata or small samples, which are statistically representative of the larger set. The data transformation is done mostly by deterministic models, which are fast, auditable, and inexpensive.
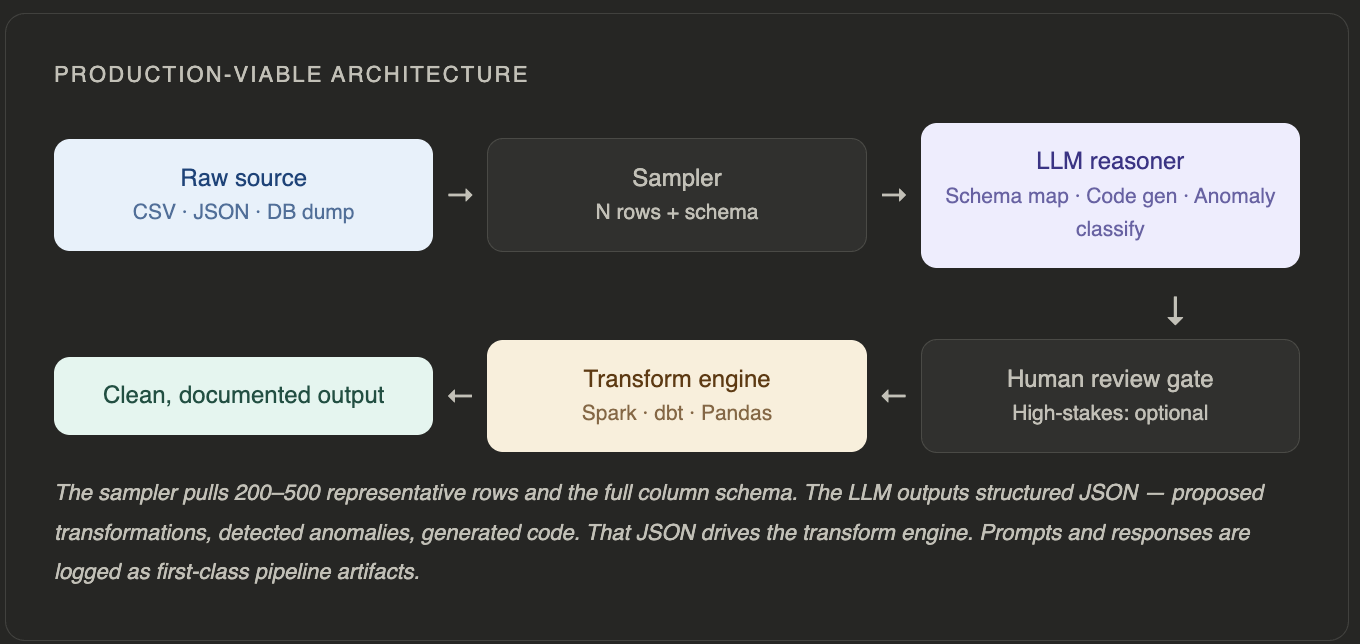
Given this, LLM calls will be made only during the initial phases of the data processing pipeline or upon triggering of the schema event changes. The steady-state operational costs are zero since you only incur costs due to LLM model calls if there is truly something 'new' that requires processing.
Implementation: Schema Mapping
Among all the components, let's first develop the schema mapper, which takes a sample DataFrame and a target schema and produces column mappings in structured JSON format. The objective is to get the model to reason about column semantics rather than rely solely on the nomenclature. Cust_id and customer_identifier should link to customer_id, and a column that is unlabelled should also link if the values in the column behave identically to customer IDs.
import pandas as pd
import json
def llm_schema_mapper(
source_df: pd.DataFrame,
target_schema: dict,
sample_size: int = 100
) -> dict:
"""
Infers column mappings from source to target schema using an LLM.
Returns: { source_col: target_col_or_None }
The LLM reasons about column semantics — not just name similarity.
'cust_id', 'CustomerID', and 'id_customer' all map to 'customer_id'.
"""
client = anthropic.Anthropic()
sample = source_df.head(sample_size).to_json(
orient="records", indent=2
)
dtypes = source_df.dtypes.to_dict()
null_rates = (
source_df.isnull().mean().round(3).to_dict()
)
prompt = f"""You are a senior data engineer performing schema mapping.
SOURCE COLUMN METADATA:
{json.dumps({
"columns": list(source_df.columns),
"dtypes": {k: str(v) for k, v in dtypes.items()},
"null_rates": null_rates,
}, indent=2)}
SAMPLE ROWS ({sample_size} rows):
{sample}
TARGET SCHEMA:
{json.dumps(target_schema, indent=2)}
Map each source column to the most semantically appropriate target
field. Consider: column name, data type, value patterns, and null
rates. If no target mapping is appropriate, use null.
Respond ONLY with a valid JSON object in this exact shape:
{{
"column_mapping": {{"source_col": "target_col_or_null"}},
"confidence": {{"source_col": 0.0_to_1.0}},
"notes": {{"source_col": "brief_reasoning_if_ambiguous"}}
}}"""
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
temperature=0, # Deterministic for schema work
messages=[{"role": "user", "content": prompt}]
)
result = json.loads(response.content[0].text)
# Surface low-confidence mappings for human review
low_confidence = {
col: result["notes"].get(col, "—")
for col, conf in result["confidence"].items()
if conf < 0.7
}
if low_confidence:
print(f"⚠ Low-confidence mappings flagged for review: {low_confidence}")
return result["column_mapping"]
# ─── Usage ───────────────────────────────────────────────────────
source = pd.DataFrame({
"cust_id": ["C001", "C002", "C003"],
"full_name": ["Alice Johnson", "Bob Smith", "Carol Wu"],
"dob": ["1990-04-12", "1985-11-03", "1992-07-22"],
"rev_usd": [1200.5, -1, 980.0], # -1 is a sentinel value
"src_sys": ["CRM", "CRM", "ERP"], # source system tag — no mapping
})
target = {
"customer_id": "string — unique customer identifier",
"name": "string — full name",
"date_of_birth": "date — ISO 8601 (YYYY-MM-DD)",
"revenue": "float — USD, null if unknown",
}
mapping = llm_schema_mapper(source, target)
print(json.dumps(mapping, indent=2))
# → {
# "cust_id": "customer_id",
# "full_name": "name",
# "dob": "date_of_birth",
# "rev_usd": "revenue",
# "src_sys": null ← correctly excluded
# }Note temperature=0 — for schema mapping, you want the same answer every time. Also note the confidence scoring: mappings below 0.7 are surfaced for human review before the pipeline runs.
Implementation: Generating Transformation Code
Code generation is the second and higher-value primitive. The engineer explains the intended cleaning in simple terms. The LLM generates an executable Python function, complete with comments. Crucially, the function is checked into version control and tested before it ever sees production data; this is not an active LLM call into your data pipeline.
import pandas as pd
import textwrap, ast
def generate_transform(
description: str,
sample_df: pd.DataFrame,
validate: bool = True
) -> str:
"""
Generates a validated `transform(df) -> df` function from a
natural-language description of the cleaning rules required.
Args:
description: Plain-English cleaning instructions
sample_df: Representative sample for type/value context
validate: Parse-check the generated code before returning
Returns:
A string containing a complete Python function definition,
ready to be written to disk and reviewed before execution.
"""
client = anthropic.Anthropic()
prompt = f"""You are a senior data engineer. Write production-ready
Python code to clean a pandas DataFrame.
DATAFRAME SCHEMA:
{sample_df.dtypes.to_string()}
SAMPLE (5 rows):
{sample_df.head(5).to_string()}
CLEANING REQUIREMENTS:
{textwrap.dedent(description)}
Write a function with this signature:
def transform(df: pd.DataFrame) -> pd.DataFrame:
Rules:
- Use only pandas (stdlib ok, no third-party imports)
- Handle NaN and edge cases explicitly — never assume clean input
- Add a one-line comment on each non-trivial step
- Return a copy, never mutate the input DataFrame
- Raise ValueError with a descriptive message for unrecoverable data issues
Respond with ONLY the function definition. No markdown, no imports,
no test code. The function must be importable as written."""
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=2000,
temperature=0,
messages=[{"role": "user", "content": prompt}]
)
code = response.content[0].text.strip()
if validate:
try:
ast.parse(code) # syntax check
except SyntaxError as e:
raise ValueError(f"LLM produced invalid Python: {e}") from e
return code
# ─── Usage ───────────────────────────────────────────────────────
sample = pd.DataFrame({
"cust_id": ["C001", "C002"],
"full_name": [" Alice Johnson ", "bob smith"],
"dob": ["4/12/1990", "1985-11-03"],
"rev_usd": [1200.5, -1],
})
fn_code = generate_transform("""
1. Rename: cust_id → customer_id, full_name → name,
dob → date_of_birth, rev_usd → revenue
2. Strip leading/trailing whitespace from all string columns
3. Title-case the 'name' column
4. Parse 'date_of_birth' to datetime, handling both M/D/YYYY
and YYYY-MM-DD input formats
5. Replace revenue values of -1 or below 0 with NaN
(these are sentinel 'unknown' values, not real negatives)
""", sample)
print(fn_code)
# → def transform(df: pd.DataFrame) -> pd.DataFrame:
# df = df.copy()
# # Rename to canonical target schema
# df = df.rename(columns={...})
# ...
# Save for review, then execute:
with open("transforms/vendor_a_clean.py", "w") as f:
f.write(fn_code)
# → PR review → merge → pipeline picks it up on next runThe generated function is written to disk, reviewed in a pull request, and merged before it touches any production data. The LLM is a code-generation assistant, not a runtime dependency.
Traditional vs. LLM-Augmented Pipelines
The operational difference is most apparent when a new data source is introduced or an existing one is updated. For a traditional pipeline, this would involve a support ticket, a sprint story, and several hours of engineering work. For an LLM-augmented pipeline, the process is simply re-running the schema mapper and reviewing a pull request for the generated transformation function.

Real-World Use Cases
Over the various industries where the pattern has begun to emerge, there is a common theme of having a high variety of data sources, rapidly changing systems, and a requirement for clear, human-readable justification for automated decision-making.
- Multi-vendor data integration: A growing number of vendors are integrated into data ingestion systems in the finance and health care industries. Schema mapping that previously demanded a week of integration effort is now completed in less than a day.
- Self-healing pipelines: An LLM is able to analyze the stack trace and upstream schema to determine the cause of the failure, suggest a patch, and route it for human approval before the pipeline is re-executed.
- Data quality narration: Simplifying and summarising the output of Great Expectations to convert technical assertion failures into a call to action for stakeholders without a technical background.
- Modernizing legacy ETL: LLMs are capable of reading and converting legacy code into both dbt SQL and the associated documentation, converting and translating decades-old COBOL or PL/SQL transformation logic into documented, testable dbt models.
- The extraction of unstructured data: Data captured in records that are structured by parsing free-text fields, emails, PDFs, etc. Includes transforming medical notes to FHIR and contracts to structured obligation tables.
- Dynamic feature engineering: The time between having raw data and deriving it into a set of features that are ready for modeling is greatly reduced by the automatic proposing and generating of features that transform the data for ML pipelines.
Integrating With Your Existing Stack
You won't need to reconstruct your data platform to implement this approach, as LLM augmentation integrates with data tools that your teams already use.
DBT: LLMs can be used to create SQL for dbt models from free text descriptions of the business transformations or to populate description fields in your schema YAML files. The LLM will read your source models and other relevant documentation to generate documentation that is consistent and accurate.
AIRFLOW: LLM schema inference can be encapsulated as a separate task in the upstream node of your Directed Acyclic Graph (DAG). Downstream tasks can access the structured JSON produced by this task as XCom (cross-communication) values. If changes to the schema are detected, a human-approval gate should be triggered prior to allowing the rest of the DAG to execute.
GX: Once LLM schema inference has been completed, automatically create expectation suites for Great Expectations that align with the inferred types, value ranges, and nullability expectations. This will result in your data contracts being in sync with your expectations without additional effort.
SPARK: LLMs can also be used to create transformation functions in PySpark for new source schemas, which can be executed within your existing Spark jobs. This means that only the transformation functions will be new, while the rest of the orchestration layer will remain the same.
Challenges You Need to Solve Before Shipping
All of this costs money. Five forms of failure will come back to haunt you if you apply LLM-generated code to sensitive data without addressing these issues.
- Risk of hallucination: LLMs can generate erroneous column mappings or generate transformations that are syntactically valid but semantically incorrect. Mandatory transform code validation, unit tests, sample data tests, output schema tests, and high-stakes mappings require human review. The confidence score in the schema mapper exists to prompt human review.
- Non-determinism: The same prompt may produce different outputs. Version control can be used to replicate models. Set the code and schema generation tasks to a temperature of 0. You should keep the prompt and response and every artifact produced by the LLM so you can replicate the reasoning.
- Data privacy: You are not allowed to send live production datasets to external LLM APIs due to data privacy. Use metadata and small anonymized samples to keep data samples. Use a self-hosted model or a compliant data processing agreement for secure data compartments for sensitive data.
- Cost and latency at scale: Costs and processing delays are issues. An LLM call can add processing time and costs. Limit LLM use to the initialization of the processing pipeline, schema changes, and error handling. The design above incorporates this.
- Auditability and governance: Auditability and governance: A common \ question posed by regulators and data governance teams is regarding the reasons for implementing a transformation. As such, prompt and completion logs should be treated like the data lineage of a pipeline and be considered first-class pipeline artifacts. In LLMs' regulated settings, changes made to code by LLMs will always require a human review and sign-off prior to code deployment, just as you would for any code that interacts with sensitive data.
What This Means for Data Engineering as a Discipline
Data pipeline scenario that consists of LLMs (Large Language Models) will require data engineering skills to build as a data pipeline that consists of LLMs (Large Language Models) will require engineering skills to build around the LLM system.
What is the best way to sample data so that the LLM system is able to analyze representative edge case examples in a statistical model? What are the passing criteria for test suites that every LLM (Large Language Model) generated transformation function should have prior to being merged? How is it that good human review gates for schema mapping are established? Given the context of transformation models, what is the meaning of auditability?
There are system design issues, not system implementation problems. Implementation is increasingly shifted to the model. The architecture, the engineer's contracts, guardrails, and validation harnesses become more valuable when models take on more boilerplate work.
The paradigm shift is not "LLMs replace data engineers." The shift is "LLMs take over the specification layer, and data engineers engineer the frameworks to make LLM outputs safe, auditable, and reliable."
Key Takeaways
- Use LLMs as a semantic coordination layer, not as substitutes for Spark, dbt, or Pandas. Apply them at the four leverage points: schema mapping, code generation, anomaly detection, and documentation.
- The privacy and cost rationale for this constraint is wholly non-negotiable.
- The generated code should be treated as an untrusted dependency: validate, test with untrusted sample data, version, and subject to human review before it interacts with any sensitive, regulated, or high-stakes data.
- Always set temperature=0 and pin model versions for schema and code generation. Treat all prompts and completions as first-class artifacts of the pipeline for logging and audit reproducibility.
- In this paradigm, the data engineers who design the validation harnesses, review gates, and audit systems that make LLM-generated outputs production safe will be the most valuable.
Opinions expressed by DZone contributors are their own.
Comments