Making of Unreliable Systems
You can’t ignore reality and go very far! You must understand how the real world works to model and create reliable systems.
Join the DZone community and get the full member experience.
Join For FreeKnowing anti-patterns and pitfalls is often more useful than knowing patterns when designing a system, so I decided to write this blog post about factors that I think will lead to producing unreliable systems from my experiences in designing (mostly) distributed enterprise applications.
I’ll be pleased to know your related experiences and comments on the matter.
What Is Modeling?
The human brain is a pattern-seeking device. However, it’s a costly process, and the main goal of thinking is to terminate/resolve what caused this process to start in the first place; so it has developed several mechanisms to prevent it from happening too often; the one related to our discussion here is the mental model. Reality is complex, chaotic, and too messy for our limited brain capabilities and resources to comprehend as it is (if that’s even possible); so our minds will try to create an alternative reality which is very simple and (most of the time) easily understandable, and that’s what modeling is all about! from how we think about how nature works, in science for example, to proper social behavior, to what to be afraid of or seek for, all are the results of our mental model. It is noteworthy that models are neither objective reality nor meant to be so!
All models are wrong, but some are useful.
In general, there are two kinds of models:
- Not useful (in a context)
- Useful (in a context)
The context part is of extreme importance here, take, for example, Newton’s theory (by the way, theories are models, too!) of gravitation vs. the theory of general relativity, both are useful in different contexts (flat space-time in low speeds vs. near-light speeds in a possibly curved space-time) and one does not replace the other as some journalists in history tried to convince people that it was the case and science had changed its mind! An unbiased sense of context is crucial to designing successful, reliable systems (IMHO).
What Is Reliability?
There is no globally accepted definition of what is meant by software reliability; some people say it’s about operational reliability, some say it’s about what customer experiences, some emphasize the correctness of programs, and some confuse it with fault-tolerance and availability! (however, these might be some of the factors in certain cases) So I need to define what I mean by reliability in the context of this article. I use reliability as we use in English; a reliable system is one that we can trust to do what we mean as perfectly as possible and not do anything we don’t want it to do. It might seem like correctness at first, but I think it’s a super-set of it; for example, you won’t rely on a slow system that crashes every minute but will do its job if given enough time!
How Does Modeling Affect Reliability of Systems?
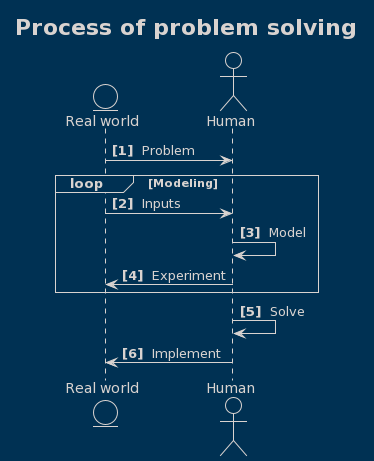
You can’t ignore reality and go very far! The reasoning here is really intuitive but somewhat overlooked most of the time.
Let me explain:
We want to make things easier for ourselves, eliminating any cost, money, or mental energy.
- We start treating our conditions as a problem to solve.
- To solve that problem, we need to gather data.
- Map the reality to a simpler model to fit in our minds.
- Define the problem to solve, then start experimenting with the model.
- Hopefully, we will solve the problem after some iterations.
- We need to find a way to implement the solution in reality to achieve our first goal.
When we want to implement a solution, in reality, we have many options. One of the most common approaches (and the one we’re interested in here) is leveraging computer systems by programming.
The only reason your thinking might solve problems in the real world is that there is a relation between your mental model where it originates and the real world, so You can’t start implementing without any model if you didn’t pay enough attention to modeling; it means that you are implementing a naive model implicitly, which raises the chance of facing serious issues we’re talking about in this article, and also decreases correlation of model with reality drastically. You will end up in fantasy land, for example!
Having a model that does not resemble reality with sufficient precision is also a burden, as reality behaves in unexpected ways in the model above. For example, Ptolemy’s geocentric model of the solar system, which was even more precise than the Heliocentric model with circular orbits but had a lot of trouble describing other parts of reality that had been unknown in his era, while the Heliocentric model with elliptic orbits solved those issues, as it was both more straightforward and had described reality with more precision. Note that this is not to say that there is a correct model, and other models are wrong! as mentioned in previous sections, models are merely devices for our understanding and problem-solving. We should not confuse them with reality.
Ptolemy himself, in his Almagest, points out that any model for describing the motions of the planets is merely a mathematical device. Since there is no way to know which is true, the simplest model that gets the right numbers should be used.
Ignoring Business
Back to the software industry, if you are designing an enterprise software system, you are modeling an existing model of a system built on people communication, organization structures, and business processes (which are too complex by themselves!); creating another model that has any logical and conceptual mismatch increases complexity and decreases life happiness simultaneously, very rapidly.
You can’t solve business problems with more technical efforts!
This is where Domain-driven design comes to help in modeling. By DDD, I mean strategic patterns and ideas, not tactical ones like entity and repository, which teaches us to discover existing business models instead of trying to create another model with possible mismatches, thus decreasing overall complexity and considering overall socio-technical factors.
This is especially the case when existing models are businesses that have been around for some time and are mature.
Overly Simplified System
Everything should be made as simple as possible, but not simpler.
— Albert Einstein
A system that tries to oversimplify reality loses some important business concepts at best or in the wrong direction in the worst case.
My favorite example of this phenomenon is when software developers try to introduce more consistency than is required, so the end result always lacks an important concept which is then needed to handle conflicts possible in a business process and also creates horrible pieces of software that are slow and spaghetti in nature. For example, in a bank transaction, assets are not transferred immediately (in an atomic fashion), and there is a time when the asset is in a soft state, which means it is neither in the source account nor in the destination account; trying to model that in an atomic fashion will require 2PC which is (almost) always the sign of bad modeling. Or, for that matter, a more common one is shopping carts trying to do the warehousing in an atomic fashion, which suffers from the same problem by not taking into account the possibility that warehousing has run out of stock or items are adjusted after an accident that caused some of the goods to become waste!
This kind of modeling problem almost always ends up in race conditions!
There are no race conditions in the real world unless you miss a concept!
Over-Abstraction

Another case of bad modeling would be the case of over-abstraction, which also loses important concepts; for example, while we can replace a method call with a remote call from a mathematical point of view, this would implicitly assume that the network is reliable, which is not! And complicates a lot of error handling at best or introduces errors that are impossible to handle correctly due to ignoring the nature of distributed systems.
Explaining the former, you can’t know whether the method in question was performed in a remote location and the response did not arrive in time, or it never reached the destination; this is a fundamental problem, and it is trying very hard to tell us it can’t be solved in this way!
Another common example is modeling an asynchronous interaction in nature as a synchronous one. This only complicates stuff, as you are shrinking possible scenarios to a problem space that is not sufficiently large, so you will either ignore problems or try to do very hard to understand heuristics to partially mitigate the issues that are not related to your main problem, but the problem that a bad model introduces!
This is why RPC is almost always a bad idea when designing reliable distributed systems.
Ignoring Physics
When you introduce concurrency or any distribution, you are changing your laws of physics about how your programs run; you are changing the nature of time from a Newtonian worldview, where there is a unique global clock, to multi-body physics in general relativity, where every object has its own relative clock; you are also changing your plain logic to temporal logic, where you can’t conclude without considering time behavior.
Your problems are getting more complex by several orders of magnitude, and you can’t ignore those problems and continue your work for more than a few days at most! Add distributed systems to the mix; you will end up with even more orders of magnitude of complexity!
Not understanding how distributed/concurrent systems differ from what most developers are used to is the cause of many business failures and pain and suffering for the people involved.
My First Law of Distributed Object Design: Don’t distribute your objects.
This is such a broad topic that requires a book to scratch the surface! But I will mention some common fallacies:
- Time: As I mentioned earlier, time and all of its derivatives (such as speed, …) are relative to observers, and there is no global time, which means that in a distributed system, you can’t compare times and total ordering is undefined.
- Ordering: You must model your ordering explicitly, as there is no implicit one, the most common approach is by using correlation IDs which will create partial order, which can solve all the problems mentioned before by replacing time with what we mean by using time, which is causality.
- Synchrony: In a distributed system, you are asynchronous; you can’t decide otherwise, as nature is asynchronous; think of it this way, even light, electricity, and nuclear forces are all event-driven :) As they are transmitted by sending tiny particles (such as photons, gluons, W and Z bozons) as messages, there is no synchronous behavior after we leave the quantum realm.
Note that by asynchronous, I don’t mean using message brokers, but asynchronous communication! That can be implemented using HTTP, for example, pulling vs. push-and-wait, as in Atom feeds vs. RPC. - Delivery: a consequence of the above properties is that we can ensure neither exactly once delivery nor ordering of messages. as humorously stated in the following quote:
There are only two challenging problems in distributed systems:
2. Exactly-once delivery
1. Guaranteed order of messages
2. Exactly-once delivery
- Latency: Computers are fast! But unfortunately, nothing can travel faster than light, and while it’s extremely fast, it’s not immediate, and even light is not fast enough to cover bad modeling errors!
Other Factors
Ignoring Organization
Modeling real-world applications is a complex task, and every system of significant size requires a significant amount of teamwork and is way beyond the capabilities of individuals. Teamwork is hard; it must be mastered like any other skill, but it does not seem so natural to many people, so it usually needs mentorship and good management to make it happen. It’s a complicated task as it requires both management skills and correct conditions to use them, and it’s mostly out of the zone of control for most individuals and even teams.
But when it happens to be the case, it seems that reliable systems are made in reliable organizations, where there is a continuous improvement culture and open communication structure, where teams are built around capabilities and have enough autonomy to do what is required, and can influence and improve the organization as a whole when needed. Rigid organizations can’t create reliable systems, as it’s an effort of iterative improvement that can’t be implemented in those kinds of organizations. For example, organizations shaped around authority are in the exact opposite shape of what will result in good results because there is no autonomy. People do not make decisions with the most related information and skills.
According to Conway’s law:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
— Melvin E. Conway
We can conclude that organizational structure plays a vital role in deciding what the system will look like. By adding that organizations are systems of people, we can infer that ignoring people’s needs and backgrounds and managing badly is the most guaranteed way to create unreliable systems; garbage in, garbage out!
Ignoring People and Teams
While it might sound trivial or too obvious, not every team or individual has the relevant skills required for developing or designing all kinds of systems. People have different skills, various backgrounds, and unique motivations. At the same time, most software development efforts seem to be simple CRUD applications (at least from outside!) that most developers are familiar with, but most of the critical systems that reliability is the most important concern are not!
Forcing teams or individuals that are not interested or lack the required skills is the recipe for creating unreliable systems, failures, and a possibly high employee turnover.
You can choose which people to make the team with, but you can’t shape a well-gelled team artificially. You can’t fake it; there are no shortcuts; you need to put in a lot of effort and invest in teams and individuals for quite some time, and if you are lucky enough, you will have the correct people and some well-gelled teams.
Last but not least, speaking of management in a knowledge worker setting, people are not human resources and are not factorizable from equations (man hour, for example); thinking otherwise is the exact problem of the mismatching mental model we have discussed above, but in the realm of social systems!
Ignoring Goals
Focusing on tools instead of modeling the actual problems is way too common! Most of the time, you can hear it as something like the following from inexperienced architects or when there are no architects at all!
We can solve this problem by introducing Kafka there, MongoDB there, and Django here and deploying all of this on a highly available k8s cluster in three continents in case of the apocalypse!
— A resume-driven design approach to design an e-commerce shopping site with ten visiting users a month
This is primarily due to Shiny Object Syndrome or Résumé-Driven Development, which has its manifesto!
This won’t end with even near good results.
Ignoring Maintenance and Evolution
It’s fine to apply workarounds sometimes, where necessary and urgent, but losing the big picture will kill the model in the long run; having the most useful and brilliant designs human beings ever had is of no use when it’s going to be ignored.
Software is supposed to be soft, malleable, and easy to change. It is also complex as it mostly tries to solve complex problems as easy problems were solved in the past. We are solving more complex problems increasingly as technology advances. one of the pitfalls of designing a complex system is that you can’t figure out how things are related to each other easily, so you can’t plan how to do it. Some will try to solve complex problems with complex systems.
It won’t work as if one could build a complex system in a single shot; it means that she can understand it completely, so it was not complex in the first place! Complex systems are always the result of incremental and iterative changes to simpler working systems.
A Complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and can't be patched up to make it work. You have to start over with a simple working system. — Gall’s law
However, ignoring evolution and iterative design, and continuous improvement often won’t result in unreliable systems, as it takes almost infinite time to reach the design, and by the time it’s ready (if it will!), it’s of no use anymore; and won’t produce any system at all, whether it is reliable or not!
Published at DZone with permission of Hossein Naderi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments