Best Practices for Evaluating LLMs and RAG Systems
Rigorous evaluation of LLM generation and retrieval systems drives robust, reliable, and ethical performance in RAG pipelines.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-augmented generation (RAG) systems have garnered significant attention for their ability to combine the strengths of information retrieval and large language models (LLMs) to generate contextually enriched responses. Through retrieved information, RAG systems address some limitations of standalone LLMs, such as hallucination and lack of domain specificity. However, the performance of such systems depends critically on two components: the relevance and accuracy of the retrieved information and the language model's ability to generate coherent, factually accurate, and contextually aligned responses.
Building on the foundational concepts of RAG systems, this article outlines robust evaluation strategies for RAG pipelines and their individual components, including the LLM, the retriever, and their combined efficacy in downstream tasks. We also explore a framework for evaluating LLMs, focusing on critical aspects such as model complexity, training data quality, and ethical considerations.
Framework for Evaluating LLMs
To evaluate large language models (LLMs), a holistic framework addressing technical, ethical, and operational dimensions is necessary. The following key areas are critical when designing and assessing an LLM system (AI Anytime 2024):
1. Model Size and Complexity
The trade-offs between model size, latency, and performance must be carefully considered. Larger models often deliver better results but require significant computational resources, affecting scalability and deployment feasibility. Evaluations should consider configurations such as quantization, pruning, and distillation to optimize deployment for constrained environments.
2. Training Data Quality and Diversity Coverage
The diversity and quality of training data are crucial for ensuring the model's adaptability across domains. High-quality datasets, curated through techniques like semi-supervised learning or expert annotation, enhance real-world utility and minimize gaps in domain knowledge.
3. Bias and Fairness
Bias evaluation involves detecting systematic favoritism and ensuring equitable outcomes for all user groups. Models should undergo rigorous tests to:
- Identify biases related to race, gender, or socioeconomic status.
- Assess performance across diverse user groups.
- Apply mitigation strategies during pre-training and fine-tuning phases.
4. Ethical Considerations and Responsible Use
LLMs must be evaluated for potential misuse, including generating harmful content or spreading misinformation. Safeguards such as content moderation and abuse detection systems should be implemented to prevent misuse and ensure responsible deployment.
5. Fine-Tuning and Transfer Learning
The adaptability of LLMs to specific domains can be assessed through fine-tuning. It is important to measure improvements in task performance while monitoring for overfitting risks. This ensures effective transfer of learning without compromising model generalizability.
6. Explainability and Traceability
Evaluating model predictions for interpretability is critical. Techniques like attention visualization or Shapley values (Zhao 2024) can help explain decisions made by the model. Additionally, maintaining detailed logs of input-output pairs and retrieval contexts ensures traceability and allows for effective auditing.
7. Robustness and Resilience to Adversarial Attacks
LLMs should be tested against adversarial attacks, such as prompt manipulations or injections designed to deceive the model. Robustness evaluations ensure that the model remains reliable under such challenges and maintains integrity in adversarial scenarios.
8. Continuous Monitoring and Improvement
LLMs require ongoing monitoring post-deployment to:
- Track performance across real-world use cases.
- Detect emerging biases or vulnerabilities.
- Identify areas for optimization and improvement.
Evaluation Methods
Evaluating the performance of retrieval-augmented generation (RAG) systems and large language models (LLMs) requires a combination of different metrics that focus on various aspects of the models' output.
Quantitative Metrics
Quantitative metrics provide objective insights into system performance, such as accuracy, precision, recall, BLEU scores, or perplexity. Modern alternatives like BERTScore or COMET can further evaluate semantic and contextual accuracy.
Qualitative Metrics
Qualitative metrics assess subjective aspects of output quality, such as coherence, relevance, factual correctness, and creativity. These metrics are often based on human judgment or domain expertise and are used to capture nuances that quantitative metrics may miss. Standardized rubrics or scoring guidelines should be provided to human evaluators to ensure consistent qualitative assessments.
The following table provides a comprehensive overview of commonly used evaluation metrics for RAG and LLM systems, categorized based on their focus areas:
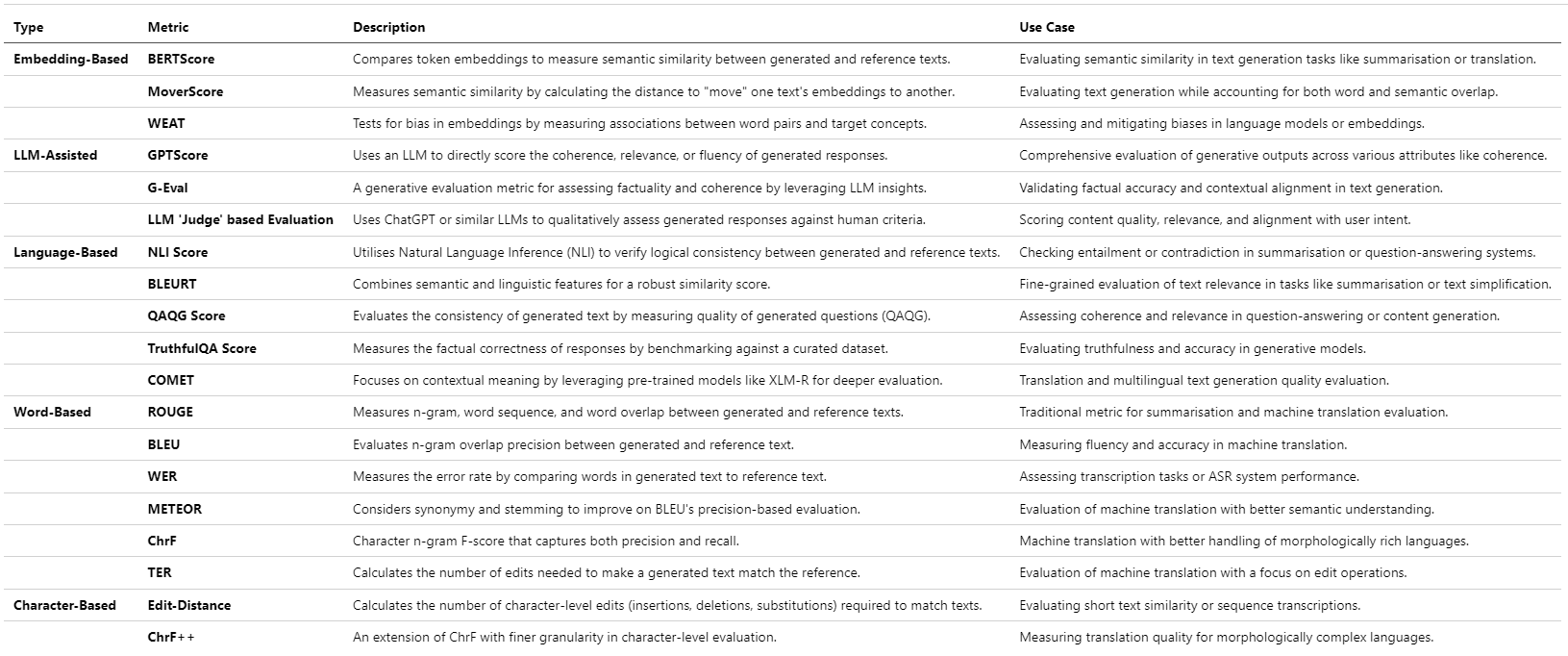
Component-Level Evaluation
Evaluating retrieval-augmented generation (RAG) systems at the component level is essential for optimizing performance. This involves assessing the retrieval and generation components to ensure they effectively work together to produce accurate and coherent results.
Retrieval Evaluation
The effectiveness of the retrieval component can be evaluated by comparing retrieved contexts to ground-truth contexts (if available) and assessing whether the most relevant and useful contexts are prioritized for a generation.
Metrics for Evaluation (Weights & Biases, 2024)
1. Ranking-Based Metrics
These metrics focus on the order in which relevant documents are retrieved:
- Hit rate: Determines whether at least one relevant document was retrieved.
- Mean reciprocal rank (MRR): Evaluates how highly ranked the first relevant document is.
- Normalized discounted cumulative gain (NDCG): Considers both the relevance and the ranking positions of all retrieved documents.
2. Predictive Quality Metrics
These metrics measure the accuracy of the retriever in identifying relevant documents:
- Precision: The proportion of retrieved documents that are relevant.
- Recall: The proportion of all relevant documents that were retrieved.
- Mean average precision (MAP): The average precision across multiple queries.
- F1-score: A balanced measure that combines precision and recall.
If ground-truth contexts are not available, an LLM can be used to assess whether the generated response is grounded in the retrieved information or if hallucinations occur. To implement this, the "judge" LLM is provided with a clear set of instructions detailing its task, such as evaluating the relevance of the retrieved contexts to a specific question-answer pair. The instructions include a rubric for scoring, for example, 0: Irrelevant, 1: Partially relevant. 2: Highly relevant. The LLM assigns relevance scores to each retrieved context based on the rubric. The mean relevance score is then calculated across all retrieved contexts. A higher average score indicates that the retriever is generally identifying and prioritizing relevant information effectively
Generation Evaluation
The objective here is to measure the LLM’s ability to generate responses that are coherent, fluent, and aligned with the retrieved information.
When a gold-standard reference is available, responses can be evaluated for their similarity to the reference using automated metrics, such as:
- BLEU: Measures n-gram overlap between the response and reference, focusing on precision.
- ROUGE: Evaluates recall by comparing overlapping sequences.
- Custom metrics: Designed to account for domain-specific requirements, such as factual correctness or technical jargon.
In the absence of ground truth, an LLM evaluator can be used to assess the generated response (Weights & Biases, 2024):
- Direct evaluation: Assess the generated response for specific properties such as toxicity, bias, or factual alignment (e.g., by verifying citations against sources).
- Pairwise comparison: Compare multiple responses for the same query, ranking them based on attributes such as coherence, informativeness, and tone. This relative ranking approach is especially useful for fine-tuning model behavior.
Bias, Fairness, and Robustness in RAG Systems
Bias and fairness in both retrieval and generation components must be regularly evaluated. Metrics like the Word Embedding Association Test (Caliskan 2017) or fairness-specific evaluations can help quantify biases. Similarly, robustness to adversarial attacks is essential for reliable performance.
End-to-End Evaluation of RAG Systems
End-to-end evaluation assesses the entire RAG pipeline by comparing final outputs to a ground truth. This approach focuses on overall quality in terms of relevance, accuracy, and informativeness. For systems without deterministic behavior, evaluation strategies must account for variability in responses, ensuring consistent performance across diverse scenarios.
Conclusion
RAG systems represent a powerful synergy of information retrieval and LLMs, addressing key challenges like hallucination and domain adaptation. However, rigorous evaluation at both component and system levels is essential for deploying reliable, robust, and ethically sound systems. Practitioners can optimize RAG pipelines for real-world applications by leveraging the outlined metrics and frameworks.
References
- AI Anytime (2024), Learn to Evaluate LLMs and RAG Approaches
- Zhao, H., Chen, H., Yang, F., Liu, N., Deng, H., Cai, H., Wang, S., Yin, D. and Du, M., 2024. Explainability for large language models: A survey. ACM Transactions on Intelligent Systems and Technology, 15(2), pp.1-38.
- Weights & Biases, 2024. RAG in Production
- Caliskan, A., Bryson, J.J. and Narayanan, A., 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), pp.183-186.
Opinions expressed by DZone contributors are their own.
Comments