Mastering Reactive Streams (Part 1): Publisher
Rule 1 of Reactor Club: Don't write your own Publisher. But if you ignore that rule, there are others to follow, as we'll see as we make our own Publisher implementation.
Join the DZone community and get the full member experience.
Join For Free
Disclaimer: Rule number 1 of the Reactor club: Don’t write your own Publisher. Even though the interface is simple, the set of rules about interactions between all these reactive streams interface is not.— Simon Baslé (Pivotal, Project Reactor).
I believe that most readers have already seen the Reactive Streams specification with an understandable four interfaces. At first glance, it seems that the implementation those interfaces should be simple. Maybe everyone tried, or wished to try, to create their own implementation of those interfaces despite the fact that there are already a few reactive implementations such as Project Reactor or RxJava.
In fact, it is not recommended, without in-depth knowledge, to implement interfaces declared in Reactive Streams. The main pitfalls are hidden behind the huge list of rules that specify strict behaviors for interfaces.
Nonetheless, during the writing of one of the chapters for my book “Reactive Programming with Spring 5”, I decided to create my own implementations of Publisher, Subscriber, Subscription, and Processor, and now I'm sharing the process. Throughout this topic, I will share basics coding steps, pitfalls, and patterns that will be useful for future implementors.
In the first part of this topic, we will implement the Publisher interface. The initial idea that came to me was creating the Publisher wrapper for Java 8 Streams. The first naive implementation with which we will start looks like this:
public class StreamPublisher<T> implements Flow.Publisher<T> {
private final Supplier<Stream<T>> streamSupplier;
public StreamPublisher(Supplier<Stream<T>> streamSupplier) {
this.streamSupplier = streamSupplier;
}
@Override
public void subscribe(Flow.Subscriber<? super T> subscriber) {
}
}Here, we just implement a Flow.Publisher<T> interface and override the subscribe() method. As you might notice from the example, instead of the Reactive Streams specification, here we are using JDK9's Flow API. Since both interfaces are identical, it does not matter which will be used as a base. The other point that should be noticed is the behavior of our Publisher. In our case, there is no dynamic data streaming. Thus, the original behavior of Publisher is cold. That means that each Subscriber will receive the same data.
To satisfy that requirement, the implementation should create a new instance of java.util.stream.Stream<T> for each new Subscriber. A good candidate to achieve that behavior is to have a Supplier<T> of a Stream instead of a plain Stream instance. That is why the constructor receives Supplier<T> as a parameter and stores it in the final field.
Now that we have an essential understanding of Publisher behavior, we can move forward to its functional implementation. Let’s try to pass some data to a subscriber naively. The next example shows the implementation of the subscribe() method:
public class StreamPublisher<T> implements Flow.Publisher<T> {
private final Supplier<Stream<T>> streamSupplier;
public StreamPublisher(Supplier<Stream<T>> streamSupplier) {
this.streamSupplier = streamSupplier;
}
@Override
public void subscribe(Flow.Subscriber<? super T> subscriber) {
try {
Stream<T> stream = streamSupplier.get();
stream.forEach(subscriber::onNext);
subscriber.onComplete();
} catch (Throwable e) {
subscriber.onError(e);
}
}
}In line 12, the Stream is pushing data to the onNext() method of our Subscriber. The next line calls onComplete() after a successful iteration. Otherwise, we move to the line that calls the onError() method.
Now, let’s create a simple verification that our solution works:
public static void main(String[] args) {
new StreamPublisher<>(() -> Stream.of(1, 2, 3, 4, 5, 6))
.subscribe(new Flow.Subscriber<>() {
@Override
public void onSubscribe(Flow.Subscription subscription) {
}
@Override
public void onNext(Integer item) {
System.out.println(item);
}
@Override
public void onError(Throwable throwable) {
System.out.println("Error: " + throwable);
}
@Override
public void onComplete() {
System.out.println("Completed");
}
});
}And finally, if we run our solution, we will see the following output:
1
2
3
4
5
6
CompletedIt seems that it works! However, is it a truly working solution from the specification's perspective? And how do we verify that all the specified rules are properly incorporated? It is not an easy job to prove it. Just correctly building a corresponding test suite may take much more time than an implementation of the working code for Reactive Streams.
However, luckily, the toolkit for that purpose has already been implemented by Konrad Malawski and got the name Reactive Streams Technology Compatibility Kit, or simply TCK. TCK defends all Reactive Streams statements and tests corresponding implementations against specified rules. TCK includes a few useful test classes that cover all corner cases for all defined interfaces. In our case, will be helpful for the next abstract class:
org.reactivestreams.tck.PublisherVerification<T>.
Let's create a test to verify our StreamPublisher<T> implementation:
public class StreamPublisherTest extends PublisherVerification<Integer> {
public StreamPublisherTest() {
super(new TestEnvironment());
}
@Override
public Publisher<Integer> createPublisher(long elements) {
return ReactiveStreamsFlowBridge.toReactiveStreams(
new StreamPublisher<Integer>(() -> Stream.iterate(0, UnaryOperator.identity()).limit(elements))
);
}
@Override
public Publisher<Integer> createFailedPublisher() {
return ReactiveStreamsFlowBridge.toReactiveStreams(
new StreamPublisher<Integer>(() -> {
throw new RuntimeException();
})
);
}
}To get a better understanding of this test, it would be nice to have a brief overview of the conceptual points of the verification before we have run it. To correctly execute the test, we mandated that we override two abstract methods and, correspondingly, provide instances of the working Publisher. In the first case, our Publisher should produce some data and complete successfully. Also, we should consider the incoming parameter elements, which represents the amount of generated data. Along with the success, the test asks to provide a failed Publisher, which should produce an error result. That is the basic, minimum configuration of the test suite we need before we start.
Ok, after a brief intro to TCK, it will be nice to check the test results:
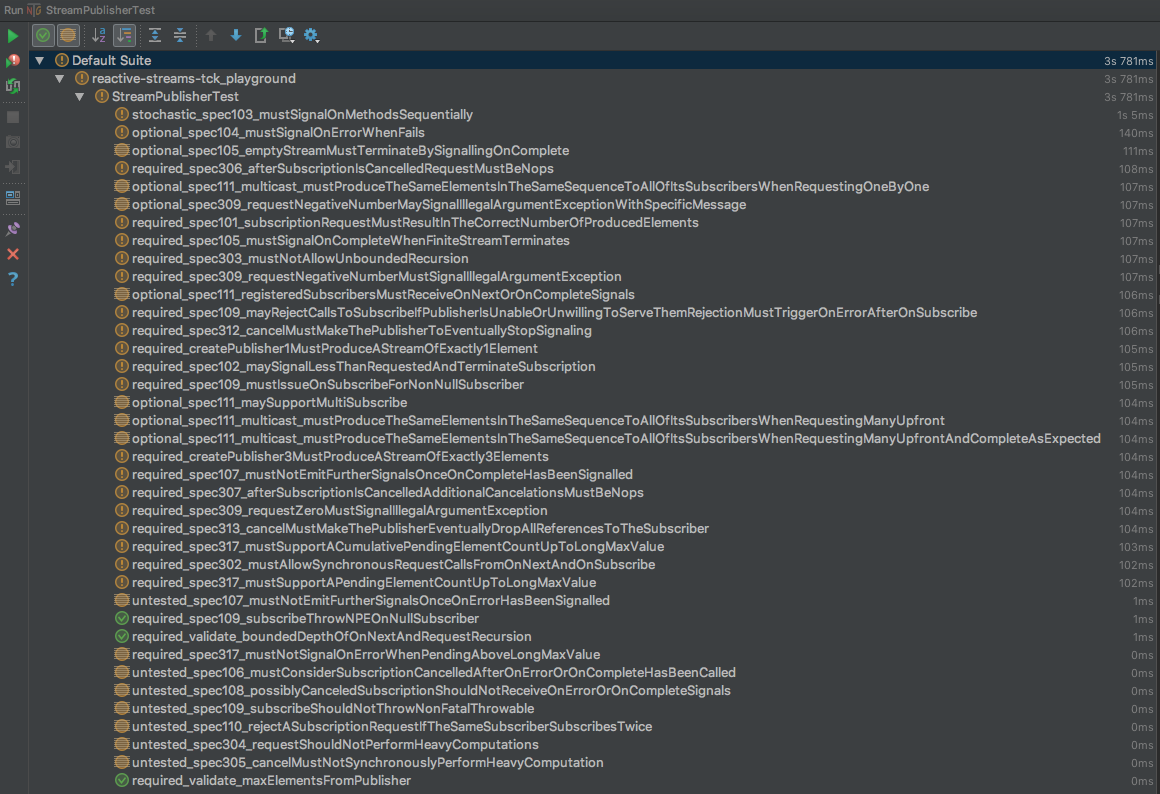
Yup, it looks terrible. 38 tests were run, 15 tests of those were skipped, 20 tests were failed, and only three were accidentally passed. Now, the implementation looks completely incorrect.
Nevertheless, let’s try to fix them all and appropriately implement our publisher. Let’s start with the simplest test, which calls required_spec109_mustIssueOnSubscribeForNonNullSubscriber. The three digits after 'spec' stand for the 1.09 rule:
Publisher.subscribeMUST callonSubscribeon the providedSubscriberprior to any other signals to thatSubscriberand MUST return normally, except when the providedSubscriberis null in which case it MUST throw ajava.lang.NullPointerExceptionto the caller, for all other situations the only legal way to signal failure (or reject theSubscriber) is by callingonError(after callingonSubscribe).
To satisfy this rule, we need to call the onSubscribe method before any other calls. Let's implement this:
@Override
public void subscribe(Flow.Subscriber<? super T> subscriber) {
subscriber.onSubscribe(null);
try {
Stream<T> stream = streamSupplier.get();
stream.forEach(subscriber::onNext);
subscriber.onComplete();
} catch (Throwable e) {
subscriber.onError(e);
}
}After running the test, you might have found that the implementation is still incorrect, even though the method call is added. The problem still exists because it is illegal to pass a null Subscription to Subscriber. So, it will be good to implement a minimum valuable Subscription and pass it to the Subscriber:
@Override
public void subscribe(Flow.Subscriber<? super T> subscriber) {
subscriber.onSubscribe(new Flow.Subscription() {
@Override
public void request(long n) {
}
@Override
public void cancel() {
}
});
try {
Stream<T> stream = streamSupplier.get();
stream.forEach(subscriber::onNext);
subscriber.onComplete();
} catch (Throwable e) {
subscriber.onError(e);
}
}Great, that change has fixed our test. However, we still have a lot of failed verifications. Now, let’s move to the rules with a bit more complexity. One of the central concepts of Reactive Streams is to provide transparent backpressure control. For that purpose, the specification introduced the new interface, which is called Subscription.
Here, 'new' emphasizes that this interface was missed in the initial implementation of the Observable-Observer model in RxJava.
Subscription has one important method to inform Publisher about its demand. This method is called request() and is an important feature of Reactive Streams. Along with standard Push model, it allows us to mix Push and Pull model.
The current implementation of StreamPublisher<T> supports only the Push model. To satisfy this hybrid model, we need to provide some mechanism that may push data only on a corresponding demand. To find the correct place to fit this mechanism, we need to analyze the Specification. An appropriate rule, which may hint where the logic should occur, is rule 3.10, which states:
While the Subscription is not cancelled,Subscription.request(long n)MAY synchronously callonNexton this (or other) subscriber(s).
Regarding that statement, the best place to put the logic is in Subscription#request itself. That way, it can be reasoned by the current idea of our Publisher, which aims to merely wrap Stream<T> without additional parallelization. Also, it's a good technique to put our Subscription implementation as an internal class. The next code snippet shows the new iteration in our Publisher implementation:
public class StreamPublisher<T> implements Flow.Publisher<T> {
private final Supplier<Stream<? extends T>> streamSupplier;
public StreamPublisher(Supplier<Stream<? extends T>> streamSupplier) {
this.streamSupplier = streamSupplier;
}
@Override
public void subscribe(Flow.Subscriber<? super T> subscriber) {
subscriber.onSubscribe(new StreamSubscription(subscriber));
}
private class StreamSubscription implements Flow.Subscription {
private final Flow.Subscriber<? super T> subscriber;
private final Iterator<? extends T> iterator;
StreamSubscription(Flow.Subscriber<? super T> subscriber) {
this.subscriber = subscriber;
this.iterator = streamSupplier.get().iterator();
}
@Override
public void request(long n) {
for (long l = n; l > 0 && iterator.hasNext(); l--) {
subscriber.onNext(iterator.next());
}
if(!iterator.hasNext()) {
subscriber.onComplete();
}
}
@Override
public void cancel() {
}
}
}Here, we created an internal class that is responsible for handling Subscriber demand and pushing data. Since each new Subscriber receives a new Subscription, it is valid to store some progress or state inside Subscription. Also, we need to somehow push data to Subscriber.
Unfortunately, Stream does not have an explicit API to allow fetching data in a ‘give me next’ fashion. That is exactly why it is unreasonable to store Stream instances explicitly. The only logical way is extracting Iterator and using its API for that purpose. Thus, we will save Iterator<T> as the local state.
All right, we got a basic understanding of the state, which will be stored inside Subscription. Now it is time to move to the request method. Here, we create a for-loop that allows us to handle the onNext method of our Subscriber. Then, when demand is satisfied, we check if the iterator has not finished yet and then notify the subscriber about the completion if the statement is true. Now, let's run the tests to recheck our code:
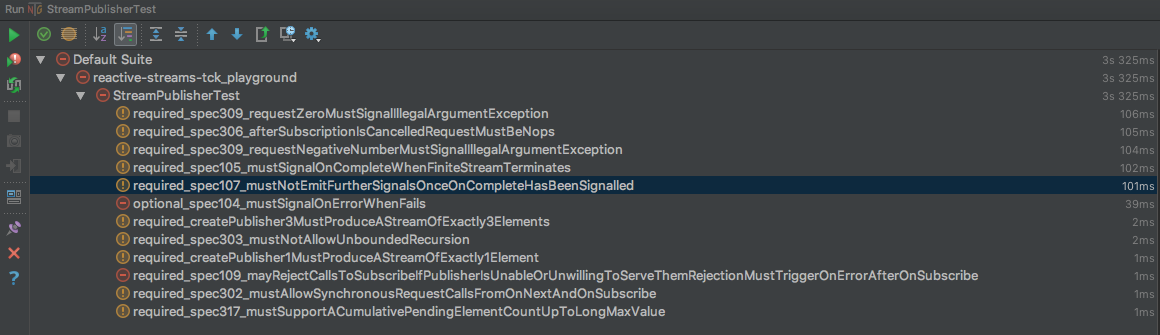
Just by analyzing the failed tests, one missing thing may be noticed here. That thing is a violation of rules 1.07 and 3.06, which say that a terminal signal must be emitted only once. Thus, we should implement a flag that will be responsible for termination state indication:
private class StreamSubscription implements Flow.Subscription {
private final Flow.Subscriber<? super T> subscriber;
private final Iterator<? extends T> iterator;
private final AtomicBoolean isTerminated = new AtomicBoolean(false);
StreamSubscription(Flow.Subscriber<? super T> subscriber) {
this.subscriber = subscriber;
this.iterator = streamSupplier.get().iterator();
}
@Override
public void request(long n) {
for (long l = n; l > 0 && iterator.hasNext() && !isTerminated(); l--) {
subscriber.onNext(iterator.next());
}
if (!iterator.hasNext() && !terminate()) {
subscriber.onComplete();
}
}
@Override
public void cancel() {
terminate();
}
private boolean terminate() {
return isTerminated.getAndSet(true);
}
private boolean isTerminated() {
return isTerminated.get();
}
}In the code above, we have introduced two additional methods and an AtomicInteger field. In that case, an extra field is responsible for preserving the current state of our Subscription and controls concurrent access via atomic behavior. The terminate() method is reliable for termination of the Subscription and returns the previous state.
The returned result may be useful for checking if the Subscription has not already been terminated — thereby preventing a violation of rule 1.07. Just by adding this additional flag and modifying the code a bit, we may resolve at least six tests! Also, let's fix some minor issues related to rules 3.09 and 1.04. The first rule, and the easiest one, says that negative or zero demand should complete with onError termination. To satisfy it, just add the next part of the code to the request method:
if (n <= 0 && !terminate()) {
subscriber.onError(new IllegalArgumentException("negative subscription request"));
return;
}In turn, rule 1.04 is more complicated. It says that all Publisher errors should be emitted via onError and should be emitted only after the onSubscribe method has been called. Regarding our implementation of the failed Publisher, the only place when an error may be thrown before onSubscribe is in Subscription constructor:
iterator = streamSupplier.get().iterator();To postpone error throwing and emitting, we need to wrap the statement in a try-catch block and store exceptions in the local field. Since an error should be thrown immediately after subscription, we should handle it manually, after our onSubscribe call:
@Override
public void subscribe(Flow.Subscriber<? super T> subscriber) {
StreamSubscription subscription = new StreamSubscription(subscriber);
subscriber.onSubscribe(subscription);
subscription.doOnSubscribed();
}Moreover, since the iteration may be a potential point of failure, it will be useful to wrap subscriber.onNext(iterator.next()); in a try-catch block as well. With the mentioned improvements, StreamSubscription will look like this:
private class StreamSubscription implements Flow.Subscription {
private final Flow.Subscriber<? super T> subscriber;
private final Iterator<? extends T> iterator;
private final AtomicBoolean isTerminated = new AtomicBoolean(false);
private final AtomicReference<Throwable> error = new AtomicReference<>();
StreamSubscription(Flow.Subscriber<? super T> subscriber) {
this.subscriber = subscriber;
Iterator<? extends T> iterator = null;
try {
iterator = streamSupplier.get().iterator();
} catch (Throwable e) {
error.set(e);
}
this.iterator = iterator;
}
@Override
public void request(long n) {
if (n <= 0 && !terminate()) {
subscriber.onError(new IllegalArgumentException("negative subscription request"));
return;
}
for (long l = n; l > 0 && iterator.hasNext() && !isTerminated(); l--) {
try {
subscriber.onNext(iterator.next());
} catch (Throwable e) {
if (!terminate()) {
subscriber.onError(e);
}
}
}
if (!iterator.hasNext() && !terminate()) {
subscriber.onComplete();
}
}
@Override
public void cancel() {
terminate();
}
void doOnSubscribed() {
Throwable throwable = error.get();
if (throwable != null && !terminate()) {
subscriber.onError(throwable);
}
}
private boolean terminate() {
return isTerminated.getAndSet(true);
}
private boolean isTerminated() {
return isTerminated.get();
}
}All right, now we come to the final point — there are only two failed tests are. Both tests failed due to the same root cause — recursive calling between request()->onNext()->request()->onNext(). To avoid recursion, we mandate a check of the state of execution and verify if the request is called from the onNext method. When I tried to solve this problem, the simplest idea that came to mind was creating a separate field, which would be responsible for preserving demand and indicating a recursion state at the same time. Before we go into details, let’s take an overview of the solution:
private class StreamSubscription implements Flow.Subscription {
private final Flow.Subscriber<? super T> subscriber;
private final Iterator<? extends T> iterator;
private final AtomicBoolean isTerminated = new AtomicBoolean(false);
private final AtomicLong demand = new AtomicLong();
private final AtomicReference<Throwable> error = new AtomicReference<>();
StreamSubscription(Flow.Subscriber<? super T> subscriber) {
this.subscriber = subscriber;
Iterator<? extends T> iterator = null;
try {
iterator = streamSupplier.get().iterator();
} catch (Throwable e) {
error.set(e);
}
this.iterator = iterator;
}
@Override
public void request(long n) {
if (n <= 0 && !terminate()) {
subscriber.onError(new IllegalArgumentException("negative subscription request"));
return;
}
if (demand.get() > 0) {
demand.getAndAdd(n);
return;
}
demand.getAndAdd(n);
for (; demand.get() > 0 && iterator.hasNext() && !isTerminated(); demand.decrementAndGet()) {
try {
subscriber.onNext(iterator.next());
} catch (Throwable e) {
if (!terminate()) {
subscriber.onError(e);
}
}
}
if (!iterator.hasNext() && !terminate()) {
subscriber.onComplete();
}
}
@Override
public void cancel() {
terminate();
}
void doOnSubscribed() {
Throwable throwable = error.get();
if (throwable != null && !terminate()) {
subscriber.onError(throwable);
}
}
private boolean terminate() {
return isTerminated.getAndSet(true);
}
private boolean isTerminated() {
return isTerminated.get();
}
}Here, we added the field demand, in which the requested number of elements will be stored. Also, to prevent recursion, we added an if statement and checked if demand is greater than zero. This assumption is valid because of rule 3.01, which says that only a Subscriber has access to a Subscription, and the request() method must be called inside the Subscriber context.
Also, it is good to emphasize that the request method may be called concurrently, and it is important to adjust demand in a thread-safe manner. For that purpose, the type of the demand field is AtomicLong. Finally, the for-loop statement was a bit modified for atomic API usage.
If we run TCK against the current implementation, we will find that all tests have been passed, which was our primary goal!
However, this implementation contains some hidden, very dangerous pitfalls that may not be noticed at first glance (thanks to David Karnok, who highlighted those points). To understand the problem, let's imagine high-concurrent access to the request() method. The first problem is depicted in the next piece of code:
//---------Thread A---------|-----------------------Thread B--------------------------
if (demand.get() > 0) { // | demand -> 1
// | for(; ... ; executing --> demand.decrementAndGet())
// | demand -> 0
// | for(; executing --> demand.get() > 0 && ...)
// | exiting loop
demand.getAndAdd(n); // | <-- executing
// | demand -> n
return;
}Here, two separate threads are concurrently working in the request() method. That situation is allowed from both Reactive Streams specification (rule 2.7) and the JMM specification. In this example, the Thread B is near the end of the looping. At the same time, the Thread A has just finished thread-safe validation inside the if-statement. It may happen that between the if-statement and the subsequent demand.getAndAdd(n) instruction, we execute instructions from the concurrent Thread B. In that case, we come to the point when both threads exit the request() method, and a subscriber will have received no data until the next request() call.
This issue may be fixed by enhancing the code in the following way:
...
@Override
public void request(long n) {
...
if (demand.getAndAdd(n) > 0) {
return;
}
for (...Here, three redundant code lines were eliminated and replaced with one atomic CAS operation. getAndAdd() returns the previous value, which in turn allows for correct demand validation and prevents a violation of rule 3.3. Finally, all tests will be green if we run them.
Despite the fact that all TCK verifications have passed, there is another case that is still missed in the verification suite. In comparison to the previous case, which was quite unpredictable and hard to test, the second one is quite obvious. According to rule 3.17, which states...
SubscriptionMUST support an unbounded number of calls torequestand MUST support a demand up to 2^63-1 (java.lang.Long.MAX_VALUE). A demand equal or greater than 2^63-1 (java.lang.Long.MAX_VALUE) MAY be considered by thePublisheras “effectively unbounded”
...the next piece of code should be valid:
new StreamPublisher(...)
.subscribe(new Subscriber() {
public void onSubscribe(Subscription s) {
new Thread(() -> s.request(Long.MAX_VALUE)).start();
new Thread(() -> s.request(Long.MAX_VALUE)).start();
}
...
})Despite the fact that the above example is quite illogical, it is still valid. However, in that case, we will break our publisher because of a number overflow. To prevent the mentioned case, before adjusting the demand, we should verify if the sum is not overflowed. However, this action leads to the previous problem again. To solve this problem, we need to replace if (demand.getAndAdd(n) > 0) with the old-good CAS-Loop pattern (wiki):
for (;;) {
long currentDemand = demand.getAcquire(); // (1)
if (currentDemand == Long.MAX_VALUE) { // (2)
return;
}
long adjustedDemand = currentDemand + n;
if (adjustedDemand < 0L) { // (3)
adjustedDemand = Long.MAX_VALUE;
}
if (demand.compareAndSet(currentDemand, adjustedDemand)) { // (4)
if (currentDemand > 0) { // (5)
return;
}
break;
}
}Let's analyze the code:
Thread-safe value retrieving with guarantees that subsequent loads and stores are not reordered before this access. (JDK9 docs)
Additional validation to ensure that value adjusting is necessary.
Additional value validation on number overflow cases.
Thread-safe conditional CAS operation. This code block prevents value collision and ensures that the local, initial value and in-shared memory one are the same, otherwise, we repeat.
Additional value validation that prevents recursion (rule 3.3) if
currentDemandis greater than zero.
Now, if we run a new test along with TCK tests, we will find that everything is fine and all tests are passed.
To summarize: Throughout this topic, we have taken an overview of the plain implementation of Publisher. We have seen the corner cases, which points we should pay attention to first, and which toolset will be useful during the verification stage. As we have seen, TCK helps us a lot in solving issues in our code. However, TCK is not a silver bullet and missing some corner cases. Nonetheless, TCK will be a very useful as integration test-suite for the most of Reactive-Streams rules. Overall, the Reactive Streams specification is not rocket science, and with proper attention, every experienced Java developer may create their own implementation.
In the next parts of this topic, we will be:
- Implementation of a custom Subscriber.
- Implementation of the async StreamPublisher.
- Implementation of our own RxJava-like library.
The source code of this solution may be found on GitHub.
Published at DZone with permission of Oleh Dokuka. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments