The Materialized Path Technique: Tree Structures for Relational Database Systems
Create three-dimensional tree structures in a relational database system using materialized paths.
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2021 Data Persistence Trend Report.
Conventional database systems such as MySQL or Microsoft SQL Server are based upon tables, implying rows and columns. This makes it difficult to represent relational graph objects, with records being parents and children of other records in the same table. In fact, this is one of the primary arguments for why developers are choosing NoSQL today, because it makes it so simple to represent graph objects.
In this article, I will not only disprove that assumption, but I will also explain how you can create three-dimensional tree structures in a relational database system in a way that even in theory, is not possible to reproduce in a NoSQL system. Afterward, you will understand how the need to persist graph objects is not an argument for using NoSQL. As an example, let us imagine a taxonomy system and how we could represent it in a relational database.
Trees in SQL
Let us out start out with the obvious intuitive solution to create a tree structure in SQL-based systems: You can create a foreign key, pointing into the primary key of the same table, and as such, illustrate trees. However, there exists no integrated method to easily select entire sub-trees and/or to check if a node is beneath another node in the hierarchy — or even (easily) count how many ancestors a given node has. A simple foreign key is, therefore, not the solution. Instead, let us look at the Materialized Path technique by using our file system to visualize a solution. Imagine you were to create a taxonomy database, but instead of persisting it to a database system, you use the file structure of your operating system as your persistent medium.
Tree Structures in a Taxonomy Database
For the exact scenario noted above, we could imagine a root folder structure such as the following:
- plants
- animals
- fungi
Then beneath the animal kingdom, we could add a mammals node. Beneath mammals we could imagine, for instance:
primatescatsdogs- and so on…
As we come to humanoids in this structure, which is found somewhere beneath primates, we could imagine a file path to the humanoids node resembling the following:
/animals/mammals/primates/humanoids
Notice how no information is lost in the above file path. Each species in our "database" would be a file, and each category would be a folder (see Figure 1).
Figure 1
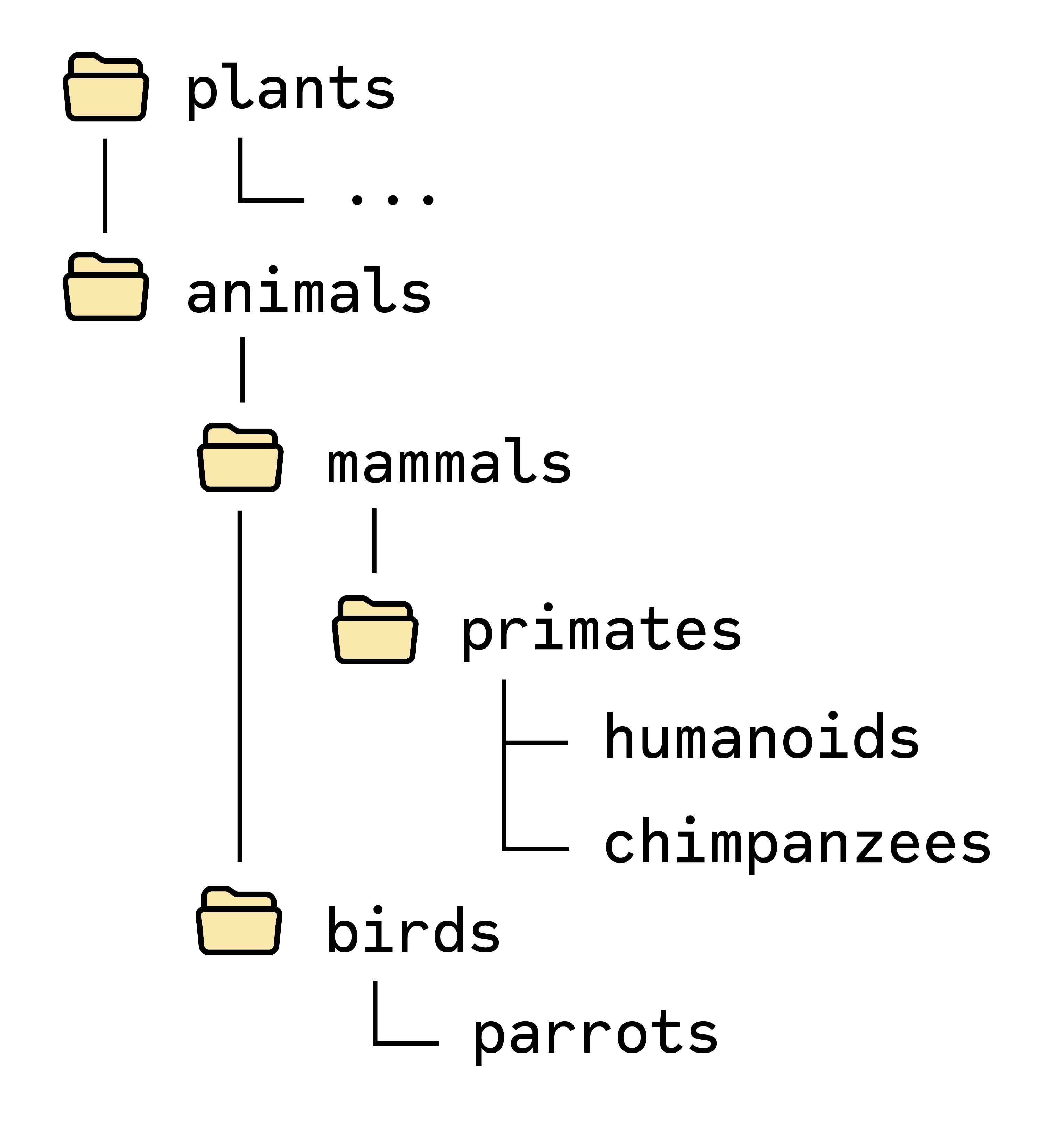
This allows us to do simple string comparisons on, for instance, chimpanzees and humanoids, as well as to find how far apart they are and easily calculate their distance. For example, the genetic distance between chimpanzees and humanoids is smaller than the distance between parrots being a bird of some sort and chimpanzees being within the primate group of our taxonomy.
To illustrate this, I have written out the path for these three animals beneath, with their commonalities in bold:
- /animals/mammal/primates/humanoids
- /animals/mammal/primates/chimpanzees
- /animals/birds/parrots
Notice how easy it is to spot in the above path that humanoids and chimpanzees have more commonalities than, for instance, humanoids and parrots. In fact, the similarities could easily be measured as follows:
similarity = string_length(common_path(lhs, rhs))
The above example is how the Materialized Path pattern works. And to apply this technique to your relational database structure is surprisingly simple.
Materialized Paths in a Taxonomy Database
Imagine a single table representing all species and categories we have in our taxonomy database. The table could resemble the following:
Name(primary key, unique, string)Path(unique, string)IsGroup(Boolean,truefor groups having children, andfalsefor leaf species)
At this point, we can represent humanoids as a record with the following values:
Name–humanoidsPath– /animals/mammals/primates/humanoidIsGroup–false
Now, if we need to count all species in our single table database that are of type mammals, we can easily accomplish that using the following SQL:
select count(*) from species where path like '/animals/mammals/%' and IsGroup=false
Flipping the above IsGroup value to true returns all groups of species beneath mammals.
With indexing turned on for our Path column, the above should execute in a handful of milliseconds, regardless of how large your database becomes. Without the Materialized Path pattern, we would first have to count all children of the mammal type, then all children of those, and after, recursively continue this process until we only have leaf nodes left. The CPU time and the database stress level would probably increase somewhere between 5-10 orders of magnitudes, easily.
By applying materialized paths to our database, we have effectively made simple queries between 10,000-10,000,000,000 times faster, depending upon the size of our database.
Of course, if you wish, you can also easily extend the above database schema by adding a referential integrity column (e.g., ParentId) that points to the primary key in the same table. Then have a trigger upon inserts, which automatically creates your path on inserts, by selecting the parent path and appending the name of the current inserted record as the last part of the materialized path parts. You can use your creativity here for yourself; however, it is important to implement as much referential integrity as possible to avoid having non-root objects (e.g., cats and dogs) being allowed to exist without parent references.
To achieve this, make sure you do not allow updates to the path column, but always make sure it is created automatically on inserts. Otherwise, you might end up with a database existing in an inconsistent and damaged state. To illustrate the problem, imagine having the following folder on your file system:
/foo/bar/howdy
But nowhere within your foo folder can the bar folder be found. This would become the database equivalent of a "dangling pointer," which is a bad thing, for the record.
Visualizing self-referencing tree structures might be difficult for the human mind due to their recursive nature. So let us use an analogy for them and look at other use cases to help our brains imagine them.
This is an excerpt from DZone's 2021 Data Persistence Trend Report.
For more:
Read the Report
Applications for the Materialized Path
The Materialized Path approach is extremely useful, and the taxonomy scenario is only one possible use case. You could also build a virtual file system using this technique, or for that matter, use materialized paths to create genealogy databases. Every time you need relational data, where each record might point into another record within the same table, materialized paths should be considered since they make it so much easier to handle your data and extract sub-graphs of your original dataset.
Materialized paths allow you to "project" three-dimensional datasets (graph objects) into a fundamentally two-dimensional data structure (tables) without losing data — similar to how artists can create 3D paintings of humans on 2D surfaces (canvas), adding shade and depth without losing information in the process. These artists create the understanding of which objects are in front of others, resulting in the illusion of three dimensions, even though the canvas itself is fundamentally two-dimensional.
Coolness Calculations
When I was a noob developer some 20 years ago, I actually "invented" this idea, referring to it as "genetic trees." Thinking they were so brilliant, I even considered patenting them. Later, one of my colleagues politely pointed out that it was already a 15-20-year-old idea at that time, except it had a different name — the name being Materialized Path, of course.
Now for the record, I didn’t originally apply this to SQL and relational databases but rather to reading EdiFact files, creating a schema by parsing the official documentation as published by the UN at that time. However, my feeling at that time of having invented something truly brilliant should give you some clues as to how cool materialized paths truly are. And once you understand how and when to apply them, the two-dimensional canvas your database is truly pops out the same way a painting does.
The Materialized Path technique is one of those patterns you do not need often, but when you do, it would be close to impossible to achieve what you want to accomplish without them.
| Thomas Hansen, Head of Development at TTCM @mrgaia on DZone | Creator of polterguy.github.io Autodidact software developer with 40 years of experience, since the age of 8, and 20+ years as a professional, creating enterprise software for dozens of companies around the world. |
Opinions expressed by DZone contributors are their own.
Comments