Memory Layout of Multi-Dimensional Arrays
Multi-dimensional arrays are really fascinating for developers, and influence memory layout.
Join the DZone community and get the full member experience.
Join For Freewhen working with multi-dimensional arrays, one important decision programmers have to make fairly early on in the project is what memory layout to use for storing the data, and how to access such data in the most efficient manner. since computer memory is inherently linear - a one-dimensional structure, mapping multi-dimensional data on it can be done in several ways. in this article i want to examine this topic in detail, talking about the various memory layouts available and their effect on the performance of the code.
row-major vs. column-major
by far the two most common memory layouts for multi-dimensional array data are row-major and column-major .
when working with 2d arrays (matrices), row-major vs. column-major are easy to describe. the row-major layout of a matrix puts the first row in contiguous memory, then the second row right after it, then the third, and so on. column-major layout puts the first column in contiguous memory, then the second, etc.
higher dimensions are a bit more difficult to visualize, so let's start with some diagrams showing how 2d layouts work.
2d row-major
first, some notes on the nomenclature of this article. computer memory will be represented as a linear array with low addresses on the left and high addresses on the right. also, we're going to use programmer notation for matrices: rows and columns start with zero, at the top-left corner of the matrix. row indices go over rows from top to bottom; column indices go over columns from left to right.
as mentioned above, in row-major layout, the first row of the matrix is placed in contiguous memory, then the second, and so on:

another way to describe row-major layout is that column indices change the fastest . this should be obvious by looking at the linear layout at the bottom of the diagram. if you read the element index pairs from left to right, you'll notice that the column index changes all the time, and the row index only changes once per row.
for programmers, another important observation is that given a row index
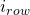 and a column index
and a column index
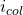 , the offset of the element they denote in the linear representation is:
, the offset of the element they denote in the linear representation is:
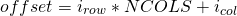
where ncols is the number of columns per row in the matrix. it's easy to see this equation fits the linear layout in the diagram shown above.
2d column-major
describing column-major 2d layout is just taking the description of row-major and replacing every appearance of "row" by "column" and vice versa. the first column of the matrix is placed in contiguous memory, then the second, and so on:

in column-major layout, row indices change the fastest . the offset of an element in column-major layout can be found using this equation:
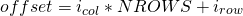
where nrows is the number of rows per column in the matrix.
beyond 2d - indexing and layout of n-dimensional arrays
even though matrices are the most common multi-dimensional arrays programmers deal with, they are by no means the only ones. the notation of multi-dimensional arrays is fully generalizable to more than 2 dimensions. these entities are commonly called "n-d arrays" or "tensors".
when we move to 3d and beyond, it's best to leave the row/column notation of matrices behind. this is because this notation doesn't easily translate to 3 dimensions due to a common confusion between rows, columns and the cartesian coordinate system. in 4 dimensions and above, we lose any purely-visual intuition to describe multi-dimensional entities anyway, so it's best to stick to a consistent mathematical notation instead.
so let's talk about some arbitrary number of dimensions
d
, numbered from 1 to
d
. for each dimension
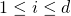 ,
,
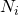 is the size of the dimension. also, the index of an element in dimension
is the size of the dimension. also, the index of an element in dimension
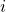 is
is
 . for example, in the latest matrix diagram above (where column-layout is shown), we have
. for example, in the latest matrix diagram above (where column-layout is shown), we have
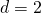 . if we choose dimension 1 to be the row and dimension 2 to be the column, then
. if we choose dimension 1 to be the row and dimension 2 to be the column, then
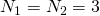 , and the element in the bottom-left corner of the matrix has
, and the element in the bottom-left corner of the matrix has
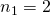 and
and
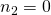 .
.
in row-major layout of multi-dimensional arrays, the last index is the fastest changing. in case of matrices the last index is columns, so this is equivalent to the previous definition.
given a
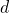 -dimensional array, with the notation shown above, we compute the memory location of an element from its indices as:
-dimensional array, with the notation shown above, we compute the memory location of an element from its indices as:
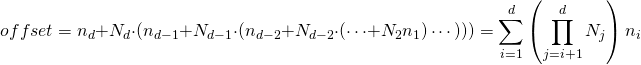
for a matrix,
, this reduces to:
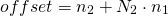
which is exactly the formula we've seen above for row-major layout, just using a slightly more formal notation.
similarly, in column-major layout of multi-dimensional arrays, the
first
index is the fastest changing. given a
-dimensional array, we compute the memory location of an element from its indices as:
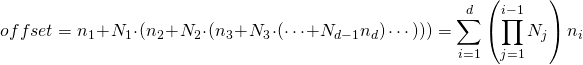
and again, for a matrix with
this reduces to the familiar:
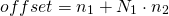
example in 3d
let's see how this works out in 3d, which we can still visualize. assuming 3 dimensions: rows, columns and depth. the following diagram shows the memory layout of a 3d array with
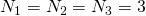 , in
row-major
:
, in
row-major
:

note how the last dimension (depth, in this case) changes the fastest and the first (row) changes the slowest. the offset for a given element is:
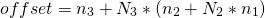
for example, the offset of the element with indices 2,1,1 is 22.
as an exercise, try to figure out how this array would be laid out in column-major order. but beware - there's a caveat! the term column-major may lead you to believe that columns are the slowest-changing index, but this is wrong. the last index is the slowest changing in column-major, and the last index here is depth, not columns. in fact, columns would be right in the middle in terms of change speed. this is exactly why in the discussion above i suggested dropping the row/column notation when going above 2d. in higher dimensions it becomes confusing, so it's best to refer to the relative change rate of the indices, since these are unambiguous.
in fact, one could conceive a sort of hybrid (or "mixed") layout where the second dimension changes faster than the first or the third. this would be neither row-major nor column-major, but in itself it's a consistent and perfectly valid layout that may benefit some applications. more details on why we would choose one layout over another are later in the article.
history: fortran vs. c
while knowing which layout a particular data set is using is critical for good performance, there's no single answer to the question which layout "is better" in general. it's not much different from the big-endian vs. little-endian debate; what's important is to pick up a consistent standard and stick to it. unfortunately, as almost always happens in the world of computing, different programming languages and environments picked different standards.
among the programming languages still popular today, fortran was definitely one of the pioneers. and fortran (which is still very important for scientific computing) uses column-major layout. i read somewhere that the reason for this is that column vectors are more commonly used and considered "canonical" in linear algebra computations. personally i don't buy this, but you can make your own judgement.
a slew of modern languages follow fortran's lead - matlab, r, julia, to name a few. one of the strongest reasons for this is that they want to use lapack - a fast fortran library for linear algebra, so using fortran's layout makes sense.
on the other hand, c and c++ use row-major layout. following their example are a few other popular languages such as python, pascal and mathematica. since multi-dimensional arrays are a first-class type in the c language, the standard defines the layout very explicitly in section 6.5.2.1 .
in fact, having the first index change the slowest and the last index change the fastest makes sense if you think about how multi-dimensional arrays in c are indexed.
given the declaration:
int x[3][5];
then x is an array of 3 elements, each of which is an array of 5 integers. x[1] is the address of the second array of 5 integers contained in x, and x[1][4] is the fifth integer of the second 5-integer array in x. these indexing rules imply row-major layout.
none of this is to say that c could not have chosen column-major layout. it could, but then its multi-dimensional array indexing rules would have to be different as well. the result could be just as consistent as what we have now.
moreover, since c lets you manipulate pointers, you can decide on the layout of data in your program by computing offsets into multi-dimensional arrays on your own. in fact, this is how most c programs are written.
memory layout example - numpy
so far we've discussed memory layout purely conceptually - using diagrams and mathematical formulae for index computations. it's worthwhile to see a "real" example of how multi-dimensional arrays are stored in memory. for this purpose, the numpy library of python is a great tool since it supports both layout kinds and is easy to play with from an interactive shell.
the numpy.array constructor can be used to create multi-dimensional arrays. one of the parameters it accepts is order, which is either "c" for c-style layout (row-major) or "f" for fortran-style layout (column-major). "c" is the default. let's see how this looks:
in [42]: ar2d = numpy.array([[1, 2, 3], [11, 12, 13], [10, 20, 40]], dtype='uint8', order='c')
in [43]: ' '.join(str(ord(x)) for x in ar2d.data)
out[43]: '1 2 3 11 12 13 10 20 40'in "c" order, elements of rows are contiguous, as expected. let's try fortran layout now:
in [44]: ar2df = numpy.array([[1, 2, 3], [11, 12, 13], [10, 20, 40]], dtype='uint8', order='f')
in [45]: ' '.join(str(ord(x)) for x in ar2df.data)
out[45]: '1 11 10 2 12 20 3 13 40'for a more complex example, let's encode the following 3d array as a numpy.array and see how it's laid out:

this array has two rows (first dimension), 4 columns (second dimension) and depth 2 (third dimension). as a nested python list, this is its representation:
in [47]: lst3d = [[[1, 11], [2, 12], [3, 13], [4, 14]], [[5, 15], [6, 16], [7, 17], [8, 18]]]
and the memory layout, in both c and fortran orders:
in [50]: ar3d = numpy.array(lst3d, dtype='uint8', order='c')
in [51]: ' '.join(str(ord(x)) for x in ar3d.data)
out[51]: '1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18'
in [52]: ar3df = numpy.array(lst3d, dtype='uint8', order='f')
in [53]: ' '.join(str(ord(x)) for x in ar3df.data)
out[53]: '1 5 2 6 3 7 4 8 11 15 12 16 13 17 14 18'note that in c layout (row-major), the first dimension (rows) changes the slowest while the third dimension (depth) changes the fastest. in fortran layout (column-major) the first dimension changes the fastest while the third dimension changes the slowest.
performance: why it's worth caring which layout your data is in
after reading the article thus far, one may wonder why any of this matters. isn't it just another way of divergence of standards, a-la endianness? as long as we all agree on the layout, isn't this just a boring implementation detail? why would we care about this?
the answer is: performance. we're talking about numerical computing here (number crunching on large data sets) where performance is almost always critical. it turns out that matching the way your algorithm works with the data layout can make or break the performance of an application.
the short takeaway is: always traverse the data in the order it was laid out . if your data sits in memory in row-major layout, iterate over each row before going to the next one, etc. the rest of the section will explain why this is so and will also present a benchmask with some measurements to get a feel of the consequences of this decision.
there are two aspects of modern computer architecture that have a large impact on code performance and are relevant to our discussion: caching and vector units. when we iterate over each row of a row-major array, we access the array sequentially. this pattern has spatial locality , which makes the code perfect for cache optimization. moreover, depending on the operations we do with the data, the cpu's vector unit can kick in since it also requires consecutive access.
graphically, it looks something like the following diagram. let's say we have the array: int array[128][128], and we iterate over each row, jumping to the next one when all the columns in the current one were visited. the number within each gray cell is the memory address - it grows by 4 since this is an array if integers. the blue numbered arrow enumerates accesses in the order they are made:
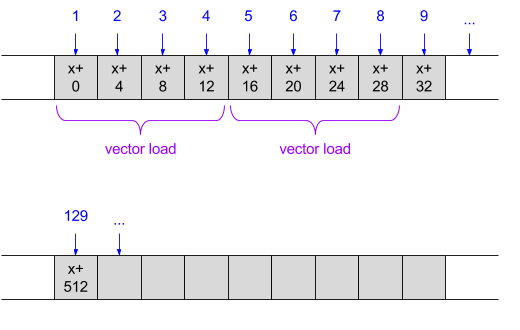
here, the optimal usage of caching and vector instructions should be obvious. since we always access elements sequentially, this is the perfect scenario for the cpu's caches to kick in - we will always hit the cache . in fact, we always hit the fastest cache - l1, because the cpu correctly pre-fetches all data ahead.
moreover, since we always read one 32-bit word after another, we can leverage the cpu's vector units to load the data (and perhaps process is later). the purple arrows show how this can be done with sse vector loads that grab 128-bit chunks (four 32-bit words) at a time. in actual code, this can either be done with intrinsics or by relying on the compiler's auto-vectorizer (as we will soon see in an actual code sample).
contrast this with accessing this row-major data one column at a time, iterating over each column before moving to the next one:
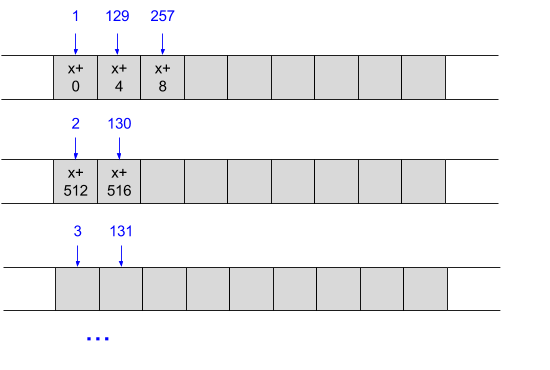
we lose spatial locality here, unless the array is very narrow. if there are few columns, consecutive rows may be found in the cache. however, in more typical applications the arrays are large and when access #2 happens it's likely that the memory it accesses is nowhere to be found in the cache. unsurprisingly, we also lose the vector units since the accesses are not made to consecutive memory.
but what should you do if your algorithm needs to access data column-by-column rather than row-by-row? very simple! this is precisely what column-major layout is for. with column-major data, this access pattern will hit all the same architectural sweetspots we've seen with consecutive access on row-major data.
the diagrams above should be convincing enough, but let's do some actual measurements to see just how dramatic these effects are.
the full code for the benchmark is available here , so i'll just show a few selected snippets. we'll start with a basic matrix type laid out in linear memory:
// a simple matrix of unsigned integers laid out row-major in a 1d array. m is
// number of rows, n is number of columns.
struct matrix {
unsigned* data = nullptr;
size_t m = 0, n = 0;
};the matrix is using row-major layout: its elements are accessed using this c expression:
x.data[row * x.n + col]here's a function that adds two such matrices together, using a "bad" access pattern - iterating over the the rows in each column before going to the next column. the access patter is very easy to spot looking at c code - the inner loop is the faster-changing index, and in this case it's rows:
void addmatrixbycol(matrix& y, const matrix& x) {
assert(y.m == x.m);
assert(y.n == x.n);
for (size_t col = 0; col < y.n; ++col) {
for (size_t row = 0; row < y.m; ++row) {
y.data[row * y.n + col] += x.data[row * x.n + col];
}
}
}and here's a version that uses a better pattern, iterating over the columns in each row before going to the next row:
void addmatrixbyrow(matrix& y, const matrix& x) {
assert(y.m == x.m);
assert(y.n == x.n);
for (size_t row = 0; row < y.m; ++row) {
for (size_t col = 0; col < y.n; ++col) {
y.data[row * y.n + col] += x.data[row * x.n + col];
}
}
}how do the two access patterns compare? based on the discussion in this article, we'd expect the by-row access pattern to be faster. but how much faster? and what role does vectorization play vs. efficient usage of cache?
to try this, i ran the access patterns on matrices of various sizes, and added a variation of the by-row pattern where vectorization is disabled . here are the results; the vertical bars represent the bandwidth - how many billions of items (32-bit words) were processed (added) by the given function.
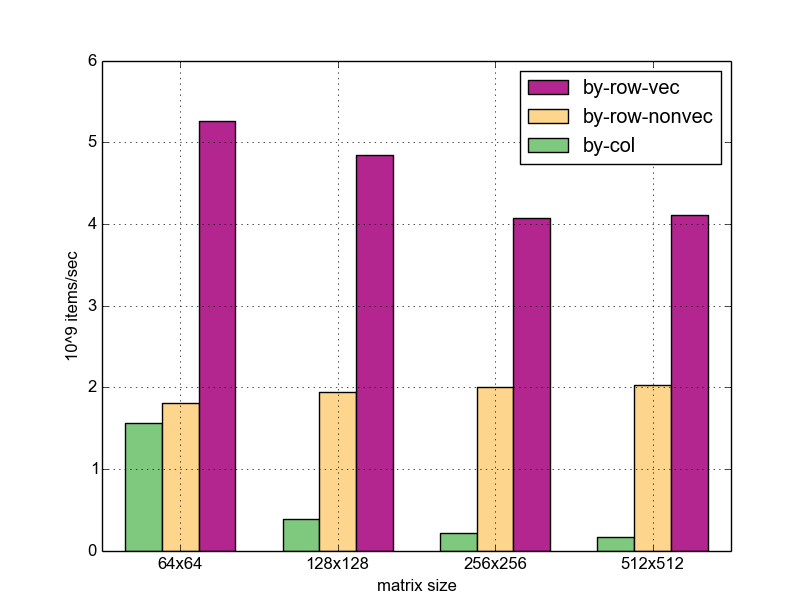
some observations:
- for matrix sizes above 64x64, by-row access is significantly faster than by-column (6-8x, depending on size). in the case of 64x64, what i believe happens is that both matrices fit into the 32-kb l1 cache of my machine, so the by-column pattern actually manages to find the next row in cache. for larger sizes the matrices no longer fit in l1, so the by-column version has to go to l2 frequently.
- the vectorized version beats the non-vectorized one by 2-3x in all cases. on large matrices the speedup is a bit smaller; i think this is because at 256x256 and beyond the matrices no longer fit in l2 (my machine has 256kb of it) and needs slower memory access. so the cpu spends a bit more time waiting for memory on average.
- the overall speedup of the vectorized by-row access over the by-column access is enormous - up to 25x for large matrices.
i'll have to admit that, while i expected the by-row access to be faster, i didn't expect it to be this much faster. clearly, choosing the proper access pattern for the memory layout of the data is absolutely crucial for the performance of an application.
summary
this article examined the issue of multi-dimensional array layout from multiple angles. the main takeaway is: know how your data is laid out and access it accordingly. in c-based programming languages, even though the default layout for 2d-arrays is row-major, when we use pointers to dynamically allocated data, we are free to choose whatever layout we like. after all, multi-dimensional arrays are just a logical abstraction above a linear storage system.
due to the wonders of modern cpu architectures, choosing the "right" way to access multi-dimensional data may result in colossal speedups; therefore, this is something that should always be on the programmer's mind when working on large multi-dimensional data sets.
taken from draft n1570 of the c11 standard. the term "word" used to be clearly associated with a 16-bit entity at some point in the past (with "double word" meaning 32 bits and so on), but these days it's too overloaded. in various references online you'll find "word" to be anything from 16 to 64 bits, depending on the cpu architecture. so i'm going to deliberately side-step the confusion by explicitly mentioning the bit size of words. see the benchmark repository for the full details, including function attributes and compiler flags. a special thanks goes to nadav rotem for helping me think through an issue i was initially having due to g++ ignoring my no-tree-vectorize attribute when inlining the function into the benchmark. i turned off inlining to fix this.
Published at DZone with permission of Eli Bendersky. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments