MERGE and Liquid Clustering: Common Performance Issues
A practical look at common pitfalls and performance challenges when using MERGE operations on liquid-clustered Delta tables, and how to avoid them.
Join the DZone community and get the full member experience.
Join For FreeAs a Spark support engineer, I still encounter many cases where MERGE or JOIN operations on Delta tables do not perform as expected, even when liquid clustering is used. While liquid clustering is a significant improvement over traditional partitioning and offers many advantages, people still sometimes struggle with it. There is often an assumption that enabling liquid clustering will automatically result in efficient merges, but in practice, this is not always true, and the reason is a lack of understanding.
Here are the most common issues when executing a merge on a liquid clustering table.
1. Clustering By a Key, Merging by Another
This is one of the most straightforward and common problems. If a table is clustered by one key but the MERGE condition uses a different key, liquid clustering cannot help.
When the merge key is not part of the clustering keys, Spark is generally unable to prune files when scanning the target table. Each incoming key must be searched across the entire dataset. As a result, Spark often performs a full scan and falls back to a Sort Merge Join or, when the dataset is small enough, a Broadcast Nested Loop Join, both of which can be expensive at scale.
2. Clustering by Multiple Keys, Merging By Only One
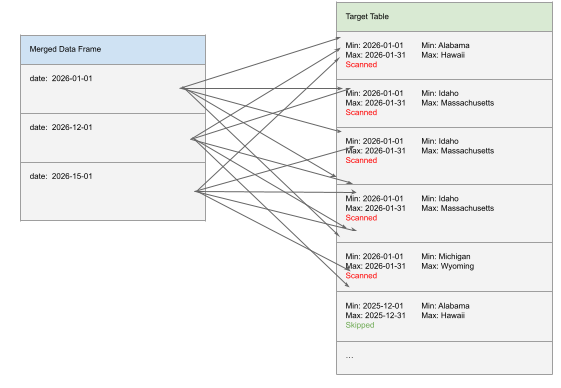
In some cases, users do merge on a clustering key but still observe little or no pruning. A frequent cause is clustering on multiple columns.
Liquid clustering relies on indexing, but adding more clustering keys dilutes the effectiveness of the index for each individual column. Instead of having a strong index on a single dimension, the data layout is optimized across combinations of keys. When a merge filters on only one of those keys, pruning becomes much less effective.
3. Clustering and Merging on the Same Key, But the Key Has No Natural Order
Liquid clustering is well-suited for high-cardinality dimensions, but the type of key still matters. If the clustering key does not have a logical or natural order, it may not behave well as a merge key.
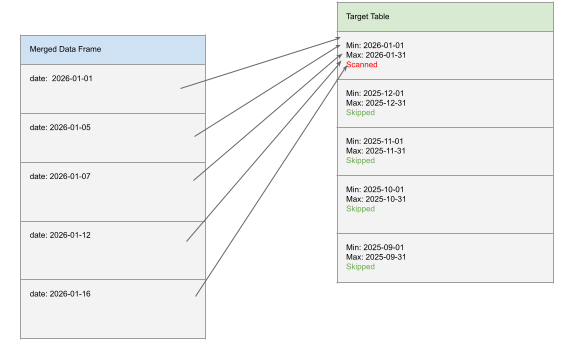
Date or timestamp columns are usually excellent candidates. For example, merging data from only the previous month into a table clustered by date allows Spark to prune most of the files efficiently.
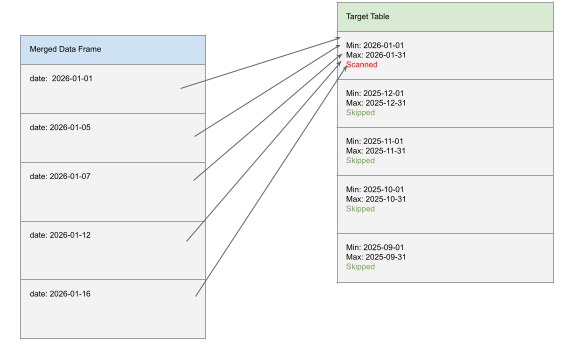
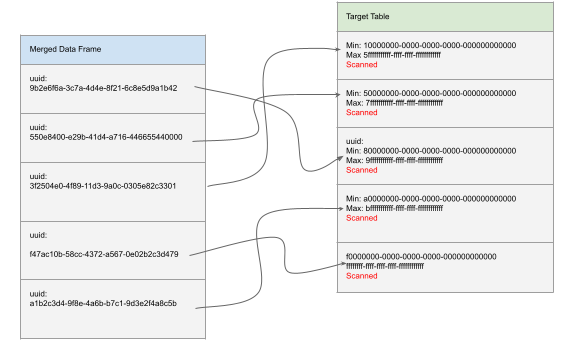
By contrast, consider a user ID represented as a UUID. Even if the table is clustered by this column, pruning will likely be minimal. Liquid clustering indexes data using value ranges. Dates have a natural ordering, so filtering by a range maps cleanly to those indexes. UUIDs, however, are effectively random, causing most ranges to overlap and forcing Spark to scan a large portion of the table.
4. Clustering and Merging by an Ordered Key, But It Has a Very Wide Merge Range
There are cases where users correctly cluster and merge on an ordered key, such as a creation date, yet the merge still takes a long time. In these scenarios, the issue often lies in the incoming dataframe rather than the target table.
Liquid clustering uses min–max ranges to index data files. If the incoming dataset contains values spanning a very large range, for example, dates from three years ago through today, those ranges overlap many indexed files. This overlap significantly reduces pruning and results in large scans despite correct clustering.
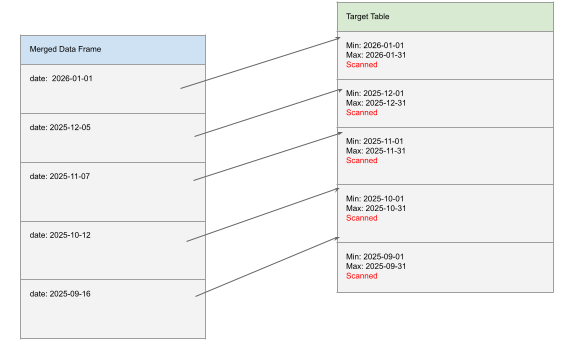
5. Complex or Non-Pushdown-Friendly Filtering Conditions
One of the common ways to force pruning is to use hard-coded filtering inside the merge condition or right before doing the merge. That is indeed a very good solution to help Spark AQE understand which files can be skipped; however, it doesn’t always work. Even when it appears that Spark should be able to skip files, it sometimes cannot. A common reason is overly complex filtering logic.
Filters involving functions, casts, nested expressions, or non-deterministic logic can prevent predicate pushdown and make it difficult for Spark to reason about value ranges. When Spark cannot translate filters into simple range predicates, file skipping becomes ineffective.
Since this post is already quite long, I’ll write a separate one with examples of such complex filtering conditions.
In case you do use complex conditions, though, one of the things that can help is to enable Photon on the cluster. Photon has some performance improvements that work in such cases.
Recommendations
The most important advice is when designing a merge on a liquid clustered table, keep in mind the two sides of the merge — the target table and the merged dataframe. Try to see how you can make sure that the range of values of the key in the merged dataframe will be pulled by Spark from only a limited number of files.
Here are some practical practices you can follow:
- Use a merge key that is also a clustering key.
- Minimize the number of clustering keys.
- Prefer clustering keys with a logical order (such as dates or timestamps).
- Keep the value range of the merge key in the incoming dataframe as narrow as possible.
- Apply filters early, ideally before the merge or directly in the merge condition. Keep filtering conditions as much as possible.
- Regularly optimize the table to maintain an efficient layout.
Liquid clustering is a powerful optimization, but its effectiveness depends heavily on how well the clustering strategy aligns with merge patterns and data characteristics. Understanding these trade-offs is key to avoiding unexpected performance bottlenecks.
Published at DZone with permission of Avi Yehuda. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments