Microservices: Consistent State Propagation With Debezium Engine
Learn challenges of state propagation across different (micro)services, architectural patterns for such challenges, and an implementation using Debezium Engine.
Join the DZone community and get the full member experience.
Join For FreeThis article outlines the main challenges of state propagation across different (micro)services together with architectural patterns for facing those challenges, providing an actual implementation using the Debezium Engine.
But first of all, let's define some of the basic concepts that will be used during the article.
- (Micro)service: I personally do not like this term. I prefer talking about bounded contexts and their internal domain/sub-domains. Running the bounded context and/or its domains as different runtimes (aka (micro)services) is a deployment decision, meaning that domain and sub-domains within a bounded context must be decoupled independently of how they are deployed (microservices vs modular monolith). For the sake of simplicity, in this article, I will use the word "microservice" to represent isolated runtimes that need to react to changes in the state maintained by other microservices.
- State: Within a microservice, its bounded context, domain, and subdomains define an internal state in the form of aggregates (entities and value objects). In this article, changes in the microservice's state shall be propagated to another runtime.
- State propagation: In a scenario where the application runtimes (i.e., microservices) are decoupled, independently of how they are deployed (Pod in Kubernetes, Docker container, OS service/process), state propagation represents the mechanism for ensuring that state mutation happened in a bounded context is communicated to the downstream bounded contexts.
Setting the Stage
As a playground for this article, we will use two bounded contexts defined as part of an e-learning platform:
- Course Management: Managing courses, including operations for course authoring
- Rating System: Enable platform users to rate courses
Between both contexts, there is an asynchronous, event-driven, relationship, so that whenever a course is created in the Course Management bounded context, an event is published and eventually received by the Rating System, which adapts the inbound event to its internal domain model using an anti-corruption layer (ACL) and creates an empty rating for that Course. The next image outlines this (simplified) context mapping:
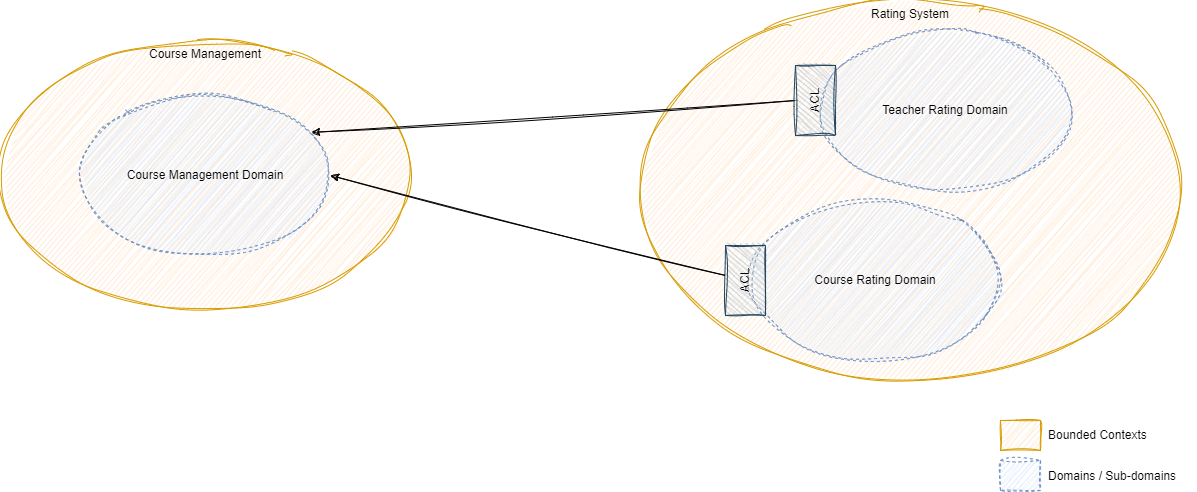
Bounded Context Mapping of the two services
The Challenge
The scenario is apparently pretty simple: we can just publish a message (CourseCreated) to a message broker (e.g., RabbitMQ) whenever a Course is created, and by having the Rating System subscribed to that event, it will eventually be received and processed by the downstream service. However, it is not so simple, and we have several "what-if" situations, like:
- What if the
Coursecreation transaction is eventually rolled back (e.g., the database does not accept the operation) but the message is correctly published to the message broker? - What if the
Courseis created and persisted, but the message broker does not accept the message (or it is not available)?
In a nutshell, the main challenge here is how to ensure, in a distributed solution, that both the domain state mutation and the corresponding event publication happen in a consistent and atomic operation so that both or none should happen.
There are certainly solutions that can be implemented and message producer or message consumer sides to try to solve these situations, like retries, publishing compensation events, and manually reverting the write operation in the database. However, most of them require the software engineers to have too many scenarios in mind, which is error-prone and reduces codebase maintainability.
Another alternative is implementing a 2-phase-commit solution at the infrastructure level, making the deployment and operations of the underlying infrastructure more complex, and most likely, forcing the adoption of expensive commercial solutions.
During the rest of the article, we will focus on a solution based on the combination of two important patterns in distributed systems: Transactional Outbox and Change Data Capture, providing a reference implementation that will allow software engineers to focus on what really matters: providing domain value.
Applicable Architecture Patterns
As described above, we need to ensure that state mutation and the publication of a domain event are atomic operations. This can be achieved by the combination of two patterns which are nicely explained by Chris Richardson in his must-read Microservices Patterns book; therefore, I will not explain them in detail here.
Transactional Outbox Pattern
Transactional Outbox focuses on persisting both state mutation and corresponding event(s) in an atomic database operation. In our case, we will leverage the ACID capabilities of a relational database, with one transaction that includes two write operations, one in the domain-specific table, and another that persists the events in an outbox (supporting) table.
This ensures that we will achieve a consistent state of both domains and the corresponding events. This is shown in the next figure:
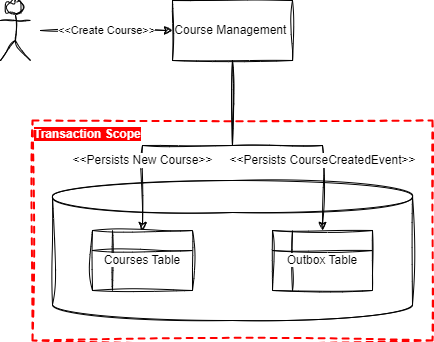
Transactional Outbox Pattern
Change Data Capture With Transaction Log Tailing
Once the events are available in the Outbox table, we need a mechanism to detect new events stored in the Outbox (Change Data Capture or CDC) and publish them to external consumers (Transaction Log Tailing Message Relay).
The Message Relay is responsible for detecting (i.e., CDC) new events available in the outbox table and publishing those events for external consumers via message broker (e.g., RabbitMQ, SNS + SQS) or event stream (e.g., Kafka, Kinesis).
There are different Change Data Capture (CDC) techniques for the Message Relay to detect new events available in the outbox. In this article, we will use the Log Scanners approach, named Transaction Log Tailing by Chris Richardson, where the Message Relay tails the database transaction log to detect the new messages that have been appended to the Outbox table. I personally prefer this approach since it reduces the amount of manual work, but might not be available for all databases.
The next image illustrates how the Message Relay integrates with the Transactional Outbox:
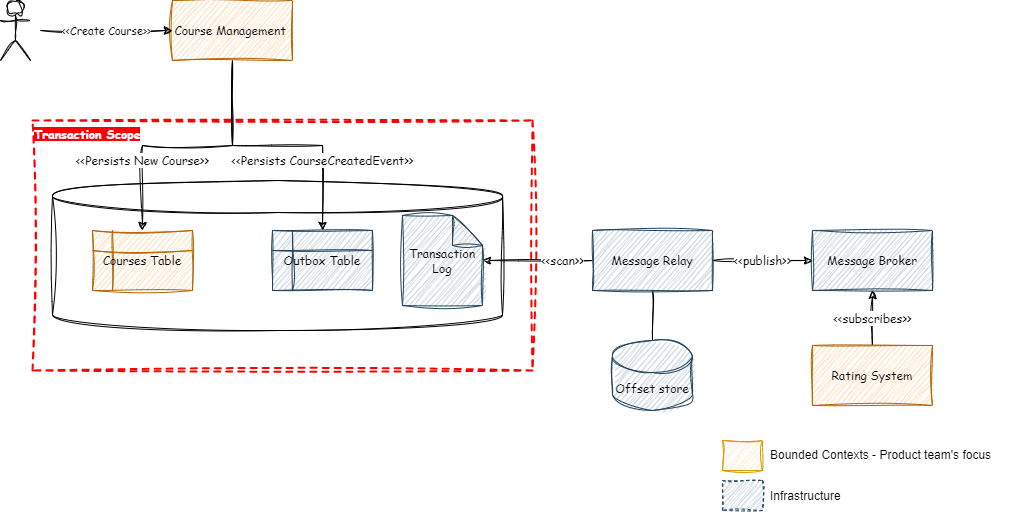
Transactional Outbox in combination with Transaction Log Tailing CDC
One of the main goals of this solution is to ensure that the software engineers of the two bounded contexts only need to focus on the elements with orange color in the diagram above; the grey components are just infrastructure elements that shall be transparent for the developers.
So, how do we implement the Transaction Log Tailing Message Relay?
Debezium
Debezium is a Log Scanner type change data capture solution that provides connectors for several databases, creating a stream of messages out of the changes detected in the database's transaction log. Debezium comes in two flavors:
- Debezium Server: This is a full-feature version of Debezium which leverages Apache Kafka and Kafka Connectors to stream data from the source database to the target system.
- Debezium Embedded/Engine: The simplified version can be embedded as a library in your product; it does not require an Apache Kafka service but still makes use of Kafka Connectors to detect changes in the data sources.
In this example, we will use Debezium Embedded, due to its simplicity (i.e., no Kafka instance is needed) but at the same time, it is robust enough to provide a suitable solution.
The first time a Debezium instance starts to track a database, it takes a snapshot of the current data to be used as a basis, once completed, only the delta of changes from the latest stored offset will be processed.
Debezium is highly configurable, making it possible to shape its behavior to meet different expectations, allowing, for instance, to define:
- The database operations to be tracked (updates, inserts, deletions, schema modifications)
- The database tables to be tracked
- Offset backing store solution (in-memory, file-based, Kafka-based)
- Offset flush internal
Some of these properties will be analyzed later in the article.
All Pieces Together
The next image shows the overall solution from the deployment perspective:
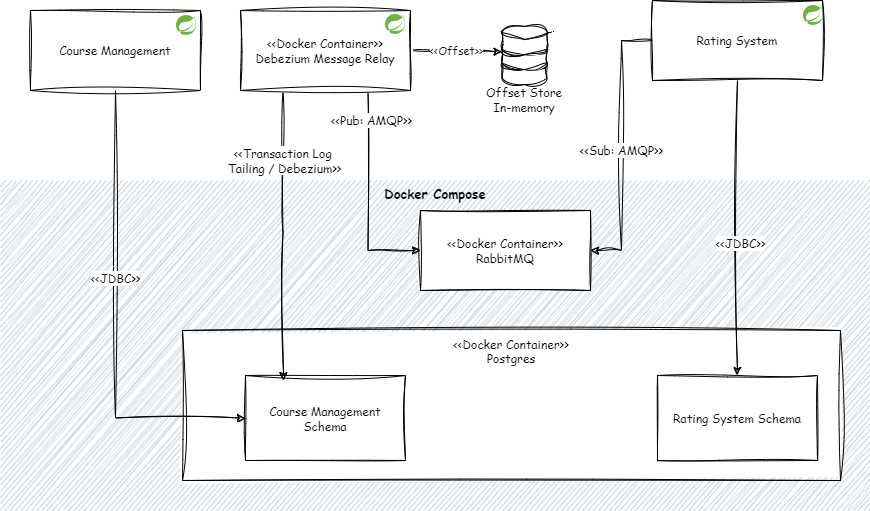
- Services: In this example, we will use Spring Boot for building the Course Management and Rating System bounded contexts. Each bounded context will be deployed as separate runtimes. The persistence solutions for both services will be PostgreSQL having each of the services a dedicated schema.
- Persistence: PostgreSQL is also deployed as a Docker container.
- Message Broker: For the message broker, we will use RabbitMQ, which is also running as a Docker container.
- Message Relay: Leveraging Spring Boot and Debezium Embedded provides the Change Data Capture (CDC) solution for detecting new records added in the outbox table of the Course Management service.
Show Me the Code
All the code described in this article can be found in my personal GitHub repository.
Overall Project Structure
The code provided to implement this example is structured as a multi-module Java Maven project, leveraging Spring Boot and following a hexagonal architecture-like structure.
There are three main package groups:
1. Toolkit Supporting Context
Modules providing shared components and infrastructure-related elements used by the functional bounded contexts (in this example Course Management and Rating System). For instance, the transactional outbox and the Debezium-based change data capture are shared concerns, and therefore their code belongs to these modules.

Where:
- toolkit-core: Core classes and interfaces, to be used by the functional contexts
- toolkit-outbox-jpa-postgres: Implementation of the transactional outbox using JPA for Postgres
- toolkit-cdc-debezium-postgres: Implementation of the message relay as CDC with Debezium embedded for Postgres
- toolkit-message-publisher-rabbitmq: Message publishers implementation for RabbitMQ
- toolkit-tx-spring: Provides programmatic transaction management with Spring
- toolkit-state-propagation-debezium-runtime: Runtime (service) responsible for the CDC and message publication to the RabbitMQ instance
2. Course Management Bounded Context
These modules conform to the Course Management bounded context. The module adheres to hexagonal architecture principles, similar to the structure already used in my previous article about repository testing.
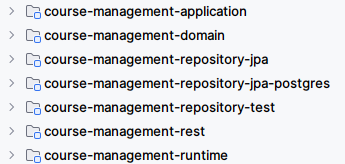
Where:
- course-management-domain: Module with the Course Management domain definition, including entities, value objects, domain events, ports, etc; this module has no dependencies with frameworks, being as pure Java as possible.
- course-management-application: Following hexagonal architecture, this module orchestrates invocations to the domain model using commands and command handlers.
- course-management-repository-test: Contains the repository test definitions, with no dependencies to frameworks, only verifies the expectation of the repository ports defined in the course-management-domain module
- course-management-repository-jpa: JPA implementation of the repository interface
CourseDefinitionRepositorydefined in the course-management-domain module; Leverages Spring Boot JPA - course-management-repository-jpa-postgres: Specialization of the repository JPA implementation of the previous module, adding postgres specific concerns (e.g., Postgres database migration scripts)
- course-management-rest: Inbound web-based adapter exposing HTTP endpoints for course creation
- course-management-runtime: Runtime (service) of the Course Management context
3. Rating System Bounded Context
For the sake of simplicity, this bounded context is partially implemented with only an inbound AMPQ-based adapter for receiving the messages created by the Course Management service when a new course is created and published by the CDC service (toolkit-state-propagation-debezium-runtime).

Where:
- rating-system-amqp-listener: AMQP listener leveraging Spring Boot AMQP, subscribes to messages of the Course Management context
- rating-system-domain: No domain has been defined for the Rating System context.
- rating-system-application: No application layer has been defined for the Rating System context.
- rating-system-runtime: Runtime (service) of the Rating System context, starting the AMQP listener defined in rating-system-amqp-listener
Request Flow
This section outlines the flow of a request for creating a course, starting when the user requests the creation of a course to the backend API and finalizing with the (consistent) publication of the corresponding event in the message broker.
This flow has been split into three phases.
Phase 1: State Mutation and Domain Events Creation
This phase starts with the request for creating a new Course Definition. The HTTP POST request is mapped to a domain command and processed by its corresponding command handler defined in course-management-application. Command handlers are automatically injected into the provided CommandBus implementation; in this example, the CommandBusInProcess defined in the toolkit-core module:
import io.twba.tk.command.CommandHandler;
import jakarta.inject.Inject;
import jakarta.inject.Named;
@Named
public class CreateCourseDefinitionCommandHandler implements CommandHandler<CreateCourseDefinitionCommand> {
private final CourseDefinitionRepository courseDefinitionRepository;
@Inject
public CreateCourseDefinitionCommandHandler(CourseDefinitionRepository courseDefinitionRepository) {
this.courseDefinitionRepository = courseDefinitionRepository;
}
@Override
public void handle(CreateCourseDefinitionCommand command) {
if(!courseDefinitionRepository.existsCourseDefinitionWith(command.getTenantId(), command.getCourseDescription().title())) {
courseDefinitionRepository.save(CourseDefinition.builder(command.getTenantId())
.withCourseDates(command.getCourseDates())
.withCourseDescription(command.getCourseDescription())
.withCourseObjective(command.getCourseObjective())
.withDuration(command.getCourseDuration())
.withTeacherId(command.getTeacherId())
.withPreRequirements(command.getPreRequirements())
.withCourseId(command.getCourseId())
.createNew());
}
else {
throw new IllegalStateException("Course definition with value " + command.getCourseDescription().title() + " already exists");
}
}
}The command handler creates an instance of the CourseDefinition entity. The business logic and invariants (if any) of creating a Course Definition are encapsulated within the domain entity. The creation of a new instance of the domain entity also comes with the corresponding CourseDefinitionCreated domain event:
@Getter
public class CourseDefinition extends MultiTenantEntity {
/* ... */
public static class CourseDefinitionBuilder {
/* ... */
public CourseDefinition createNew() {
//new instance, generate domain event
CourseDefinition courseDefinition = new CourseDefinition(tenantId, 0L, id, courseDescription, courseObjective, preRequirements, duration, teacherId, courseDates, CourseStatus.PENDING_TO_REVIEW);
var courseDefinitionCreatedEvent = CourseDefinitionCreatedEvent.triggeredFrom(courseDefinition);
courseDefinition.record(courseDefinitionCreatedEvent); //record event in memory
return courseDefinition;
}
}
}The event is "recorded" into the created course definition instance. This method is defined in the abstract class Entity of the toolkit-core module:
public abstract class Entity extends ModelValidator implements ConcurrencyAware {
@NotNull
@Valid
protected final List<@NotNull Event<? extends DomainEventPayload>> events;
private Long version;
public Entity(Long version) {
this.events = new ArrayList<>();
this.version = version;
}
/*...*/
protected void record(Event<? extends DomainEventPayload> event) {
event.setAggregateType(aggregateType());
event.setAggregateId(aggregateId());
event.setEventStreamVersion(Objects.isNull(version)?0:version + events.size());
this.events.add(event);
}
public List<Event<? extends DomainEventPayload>> getDomainEvents() {
return Collections.unmodifiableList(events);
}
}Once the course definition instance is in place, the command handler will persist the instance in the course definition repository, starting the second phase of the processing flow.
Phase 2, Persisting the State: Course Definition and Events in the Outbox
Whenever a domain entity is saved in the repository, the domain events associated with the domain state mutation (in this example, the creating of a CourseDefinition entity) are temporarily appended to an in-memory, ThreadLocal, buffer. This buffer resides in the DomainEventAppender of toolkit-core.
public class DomainEventAppender {
private final ThreadLocal<List<Event<? extends DomainEventPayload>>> eventsToPublish = new ThreadLocal<>();
/*...*/
public void append(List<Event<? extends DomainEventPayload>> events) {
//add the event to the buffer, later this event will be published to other bounded contexts
if(isNull(eventsToPublish.get())) {
resetBuffer();
}
//ensure event is not already in buffer
events.stream().filter(this::notInBuffer).map(this::addEventSourceMetadata).forEach(event -> eventsToPublish.get().add(event));
}
/*...*/
}Events are placed in this buffer from an aspect executed around methods annotated with AppendEvents. The pointcut and aspect (both in toolkit-core) look like:
public class CrossPointcuts {
@Pointcut("@annotation(io.twba.tk.core.AppendEvents)")
public void shouldAppendEvents() {}
}
@Aspect
@Named
public class DomainEventAppenderConcern {
private final DomainEventAppender domainEventAppender;
@Inject
public DomainEventAppenderConcern(DomainEventAppender domainEventAppender) {
this.domainEventAppender = domainEventAppender;
}
@After(value = "io.twba.tk.aspects.CrossPointcuts.shouldAppendEvents()")
public void appendEventsToBuffer(JoinPoint jp) {
if(Entity.class.isAssignableFrom(jp.getArgs()[0].getClass())) {
Entity entity = (Entity)jp.getArgs()[0];
domainEventAppender.append(entity.getDomainEvents());
}
}
}The command handlers are automatically decorated before being "injected" into the command bus. One of the decorators ensures the command handlers are transactional, and another ensures when the transaction completes the events in the in-memory-thread-local buffer are published to the outbox table consistently with the ongoing transaction. The next sequence diagram shows the decorators applied to the domain-specific command handler.
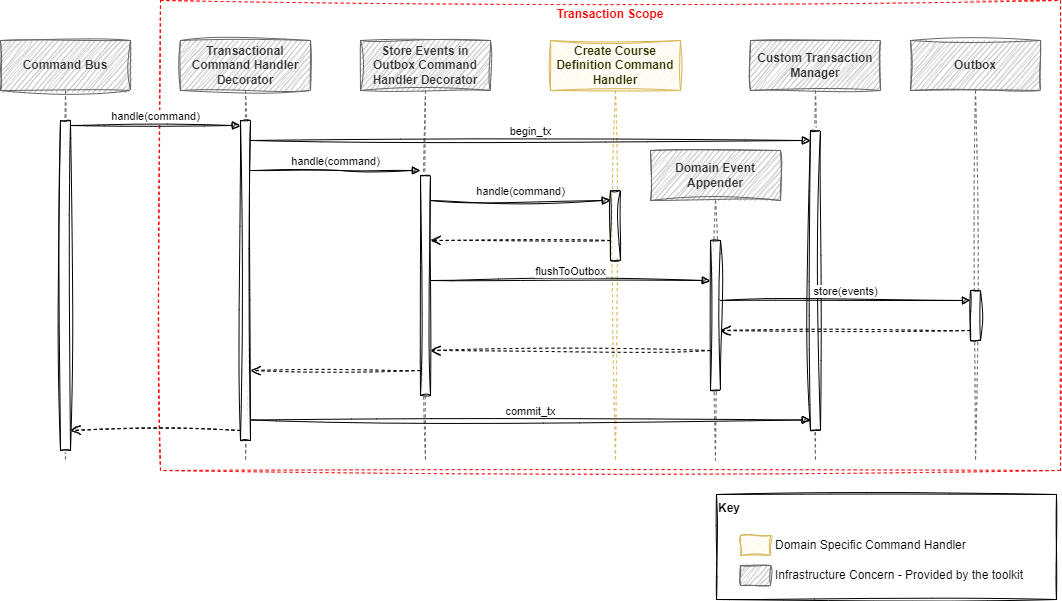
High-Level Processing Flow
The outbox is an append-only buffer (as a Postgres table in this example) where a new entry for each event is added. The outbox entry has the following structure:
public record OutboxMessage(String uuid,
String header,
String payload,
String type,
long epoch,
String partitionKey,
String tenantId,
String correlationId,
String source,
String aggregateId) {
}Where the actual event payload is serialized as a JSON string in the payload property. The outbox interface is straightforward:
public interface Outbox {
void appendMessage(OutboxMessage outboxMessage);
int partitionFor(String partitionKey);
}The Postgres implementation of the Outbox interface is placed in the toolkit-outbox-jpa-postgres module:
public class OutboxJpa implements Outbox {
private final OutboxProperties outboxProperties;
private final OutboxMessageRepositoryJpaHelper helper;
@Autowired
public OutboxJpa(OutboxProperties outboxProperties, OutboxMessageRepositoryJpaHelper helper) {
this.outboxProperties = outboxProperties;
this.helper = helper;
}
@Override
public void appendMessage(OutboxMessage outboxMessage) {
helper.save(toJpa(outboxMessage));
}
@Override
public int partitionFor(String partitionKey) {
return MurmurHash3.hash32x86(partitionKey.getBytes()) % outboxProperties.getNumPartitions();
}
/*...*/
}Phase 2 is completed, and now both the domain state and the corresponding event consistently persist under the same transaction in our Postgres database.
Phase 3: Events Publication
In order to make the domain events generated in the previous phase available to external consumers, the message relay implementation based on Debezium Embedded is monitoring the outbox table, so that whenever a new record is added to the outbox, the message relay creates a Cloud Event and publishes it to the RabbitMQ instance following the Cloud Event AMQP binding specification.
The following code snippet shows the Message Relay specification as defined in the toolkit-core module:
public class DebeziumMessageRelay implements MessageRelay {
private static final Logger log = LoggerFactory.getLogger(DebeziumMessageRelay.class);
private final Executor executor = Executors.newSingleThreadExecutor(r -> new Thread(r, "debezium-message-relay"));
private final CdcRecordChangeConsumer recordChangeConsumer;
private final DebeziumEngine<RecordChangeEvent<SourceRecord>> debeziumEngine;
public DebeziumMessageRelay(DebeziumProperties debeziumProperties,
CdcRecordChangeConsumer recordChangeConsumer) {
this.debeziumEngine = DebeziumEngine.create(ChangeEventFormat.of(Connect.class))
.using(DebeziumConfigurationProvider.outboxConnectorConfig(debeziumProperties).asProperties())
.notifying(this::handleChangeEvent)
.build();
this.recordChangeConsumer = recordChangeConsumer;
}
private void handleChangeEvent(RecordChangeEvent<SourceRecord> sourceRecordRecordChangeEvent) {
SourceRecord sourceRecord = sourceRecordRecordChangeEvent.record();
Struct sourceRecordChangeValue= (Struct) sourceRecord.value();
log.info("Received record - Key = '{}' value = '{}'", sourceRecord.key(), sourceRecord.value());
Struct struct = (Struct) sourceRecordChangeValue.get(AFTER);
recordChangeConsumer.accept(DebeziumCdcRecord.of(struct));
}
@Override
public void start() {
this.executor.execute(debeziumEngine);
log.info("Debezium CDC started");
}
@Override
public void stop() throws IOException {
if (this.debeziumEngine != null) {
this.debeziumEngine.close();
}
}
@Override
public void close() throws Exception {
stop();
}
}As can be seen in the code snippet above, the DebeziumEngine is configured to notify a private method handleChangeEvent when a change in the database is detected. In this method, a Consumer of CdcRecord is used as a wrapper of the internal Debezium model represented by the Struct class. Initial configuration must be provided to the Debezium Engine; in the example, this is done with the DebeziumConfigurationProvider class:
public class DebeziumConfigurationProvider {
public static io.debezium.config.Configuration outboxConnectorConfig(DebeziumProperties properties) {
return withCustomProps(withStorageProps(io.debezium.config.Configuration.create()
.with("name", "outbox-connector")
.with("connector.class", properties.getConnectorClass())
.with("offset.storage", properties.getOffsetStorage().getType()), properties.getOffsetStorage())
.with("offset.flush.interval.ms", properties.getOffsetStorage().getFlushInterval())
.with("database.hostname", properties.getSourceDatabaseProperties().getHostname())
.with("database.port", properties.getSourceDatabaseProperties().getPort())
.with("database.user", properties.getSourceDatabaseProperties().getUser())
.with("database.password", properties.getSourceDatabaseProperties().getPassword())
.with("database.dbname", properties.getSourceDatabaseProperties().getDbName()), properties)
.with("database.server.id", properties.getSourceDatabaseProperties().getServerId())
.with("database.server.name", properties.getSourceDatabaseProperties().getServerName())
.with("skipped.operations", "u,d,t")
.with("include.schema.changes", "false")
.with("table.include.list", properties.getSourceDatabaseProperties().getOutboxTable())
.with("snapshot.include.collection.list", properties.getSourceDatabaseProperties().getOutboxTable())
.build();
}
private static Configuration.Builder withStorageProps(Configuration.Builder debeziumConfigBuilder, DebeziumProperties.OffsetProperties offsetProperties) {
offsetProperties.getOffsetProps().forEach(debeziumConfigBuilder::with);
return debeziumConfigBuilder;
}
private static Configuration.Builder withCustomProps(Configuration.Builder debeziumConfigBuilder, DebeziumProperties debeziumProperties) {
debeziumProperties.getCustomProps().forEach(debeziumConfigBuilder::with);
return debeziumConfigBuilder;
}
}The most relevant properties are outlined below:
connector.class: The name of the connector to use; usually this is related to the database technology being tracked for changes. In this example, we are usingio.debezium.connector.postgresql.PostgresConnector.offset.storage: Type of storage for maintaining the offset; in this example, we are usingorg.apache.kafka.connect.storage.MemoryOffsetBackingStore, so that offsets are lost after restarting the service. See below.offset.flush.interval. ms: Number of milliseconds for the offsets to be persisted in the offset storedatabase.*: These properties refer to the database being tracked (CDC) for changes by Debezium.skipped.operations: If not specified, all the operations will be tracked. For our example, since we only want to detect newly created events, all the operations but inserts are skipped.table.include.list: List of the tables to include for the CDC; in this example, only the table where events are stored during Phase 2 is relevant (i.e.,outbox_schema.outbox)
The first thing Debezium will do after starting is take a snapshot of the current data and generate the corresponding events. After that, the offset is updated to the latest record, and the deltas (newly added, updated, or deleted records) are processed, updating the offset accordingly. Since in the provided example we are using an in-memory-based offset store, the snapshot is performed always after starting the service. Therefore, since this is not a production-ready implementation yet, there are two options:
- Use a durable offset store (file-based or Kafka-based are supported by Debezium Embedded)
- Delete the outbox table after the events are being processed, ensuring the delete operations are skipped by Debezium in its configuration.
The Message Relay is configured and initialized in the toolkit-state-propagation-debezium-runtime module. The values of the configuration properties needed by Debezium Embedded are defined in the Spring Boot properties.yaml file:
server:
port: 9091
management:
endpoints:
web:
exposure:
include: prometheus, health, flyway, info
debezium:
connector-class: "io.debezium.connector.postgresql.PostgresConnector"
custom-props:
"[topic.prefix]": "embedded-debezium"
"[debezium.source.plugin.name]": "pgoutput"
"[plugin.name]": "pgoutput"
source-database-properties:
db-name: "${CDC_DB_NAME}"
hostname: "${CDC_HOST}"
user: "${CDC_DB_USER}"
password: "${CDC_DB_PASSWORD}"
port: 5432
server-name: "debezium-message-relay"
server-id: "debezium-message-relay-1"
outbox-table: "${CDC_OUTBOX_TABLE}:outbox_schema.outbox"
outbox-schema: ""
offset-storage:
type: "org.apache.kafka.connect.storage.MemoryOffsetBackingStore"
flush-interval: 3000
offset-props:
"[offset.flush.timeout.ms]": 1000
"[max.poll.records]": 1000The engine is started using the Spring Boot lifecycle events:
@Component
public class MessageRelayInitializer implements ApplicationListener<ApplicationReadyEvent> {
private final MessageRelay messageRelay;
@Autowired
public MessageRelayInitializer(MessageRelay messageRelay) {
this.messageRelay = messageRelay;
}
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
messageRelay.start();
}
}The change data capture records (CdcRecord) are processed by the CloudEventRecordChangeConsumer which creates the Cloud Event representation of the CDC record and publishes it through the MessagePublisher.
public class CloudEventRecordChangeConsumer implements CdcRecordChangeConsumer {
/*...*/
@Override
public void accept(CdcRecord cdcRecord) {
final CloudEvent event;
try {
String payload = cdcRecord.valueOf("payload");
String uuid = cdcRecord.valueOf("uuid");
String type = cdcRecord.valueOf("type");
String tenantId = cdcRecord.valueOf("tenant_id");
String aggregateId = cdcRecord.valueOf("aggregate_id");
long epoch = cdcRecord.valueOf("epoch");
String partitionKey = cdcRecord.valueOf("partition_key");
String source = cdcRecord.valueOf("source");
String correlationId = cdcRecord.valueOf("correlation_id");
event = new CloudEventBuilder()
.withId(uuid)
.withType(type)
.withSubject(aggregateId)
.withExtension(TwbaCloudEvent.CLOUD_EVENT_TENANT_ID, tenantId)
.withExtension(TwbaCloudEvent.CLOUD_EVENT_TIMESTAMP, epoch)
.withExtension(TwbaCloudEvent.CLOUD_EVENT_PARTITION_KEY, partitionKey)
.withExtension(TwbaCloudEvent.CLOUD_EVENT_CORRELATION_ID, correlationId)
.withExtension(TwbaCloudEvent.CLOUD_EVENT_GENERATING_APP_NAME, source)
.withSource(URI.create("https://thewhiteboardarchitect.com/" + source))
.withData("application/json",payload.getBytes("UTF-8"))
.build();
messagePublisher.publish(event);
}
catch (Exception e) {
throw new RuntimeException(e);
}
}
}The provided MessagePublisher is a simple RabbitMQ outbound adapter converting the Cloud Event to the corresponding AMQP message as per the Cloud Event AMQP protocol binding.
public class MessagePublisherRabbitMq implements MessagePublisher {
/*...*/
@Override
public boolean publish(CloudEvent dispatchedMessage) {
MessageProperties messageProperties = new MessageProperties();
messageProperties.setContentType(MessageProperties.CONTENT_TYPE_JSON);
rabbitTemplate.send("__MR__" + dispatchedMessage.getExtension(CLOUD_EVENT_GENERATING_APP_NAME), //custom extension for message routing
dispatchedMessage.getType(),
toAmqpMessage(dispatchedMessage));
return true;
}
private static Message toAmqpMessage(CloudEvent dispatchedMessage) {
return MessageBuilder.withBody(Objects.nonNull(dispatchedMessage.getData()) ? dispatchedMessage.getData().toBytes() : new byte[0])
.setContentType(MessageProperties.CONTENT_TYPE_JSON)
.setMessageId(dispatchedMessage.getId())
.setHeader(CLOUD_EVENT_AMQP_BINDING_PREFIX + CLOUD_EVENT_TENANT_ID, dispatchedMessage.getExtension(CLOUD_EVENT_TENANT_ID))
.setHeader(CLOUD_EVENT_AMQP_BINDING_PREFIX + CLOUD_EVENT_TIMESTAMP, dispatchedMessage.getExtension(CLOUD_EVENT_TIMESTAMP))
.setHeader(CLOUD_EVENT_AMQP_BINDING_PREFIX + CLOUD_EVENT_PARTITION_KEY, dispatchedMessage.getExtension(CLOUD_EVENT_PARTITION_KEY))
.setHeader(CLOUD_EVENT_AMQP_BINDING_PREFIX + CLOUD_EVENT_SUBJECT, dispatchedMessage.getSubject())
.setHeader(CLOUD_EVENT_AMQP_BINDING_PREFIX + CLOUD_EVENT_SOURCE, dispatchedMessage.getSource().toString())
.build();
}
}After Phase 3, the events are published to the producer's (Course Management Service) message relay RabbitMQ exchange defined under the convention __MR__<APP_NAME>. In our example, __MR__course-management, messages are routed to the right exchange based on a custom cloud event extension as shown in the previous code snippet.
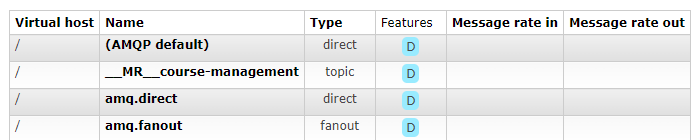 Visit my GitHub repository and check the readme file to see how to spin up the example.
Visit my GitHub repository and check the readme file to see how to spin up the example.
Alternative Solutions
This example makes use of Debezium Embedded to provide a change data capture and message relay solution. This works fine for technologies supported by Debezium through its connectors.
For non-supported providers, alternative approaches can be applied:
- DynamoDB Streams: Suitable for DynamoDB databases; in combination with Kinesis, it can be used for subscribing to changes in a DynamoDB (outbox) table
- Custom database polling: This could be implemented for supporting databases with no connectors for Debezium.
Adding any of those alternatives in this example would simply just provide specific implementations of the MessageRelay interface, without additional changes in any of the other services.
Conclusion
Ensuring consistency in the state propagation and data exchange between services is key for providing a reliable distributed solution. Usually, this is not carefully considered when designing distributed, event-driven software, leading to undesired states and situations especially when those systems are already in production.
By the combination of the transactional outbox pattern and message relay, we have seen how this consistency can be enforced, and by using the hexagonal architecture style, the additional complexity of implementing those patterns can be easily hidden and reused across bounded context implementations.
The code of this article is not yet production-ready, as concerns like observability, retries, scalability (e.g., with partitioning), proper container orchestration, etc. are still pending. Subsequent articles will go through those concerns using the provided code as a basis.
Published at DZone with permission of David Cano. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments