Microservices, Event-Driven Architecture and Kafka
Join the DZone community and get the full member experience.
Join For FreeImagine having a huge monolith application with a lot of complex functionalities strongly tied together. The scalability is a big challenge, the deployment process could become very cumbersome, and, since the internal components are highly coupled, to change the functional flow isn’t gonna be that easy.
Maybe a lot of people are familiar with this concept since this was the standard way to build an application until few years ago and that there are still a lot of monoliths in production these days.
But in the meantime, especially after the “explosion” of cloud services, the process of building a product shifted to a microservices approach. Small microservices with a well defined scope, which communicate with others to accomplish a business scope.
Despite having their disadvantages, like a complex integration testing, more remote calls, bigger security challenges, etc., they proved their power in this industry. Since the microservices are decoupled, they could scale more easily, and if you want to make a change, you can change just a single component and the rest of the microservices, as long as the contract between them is respected, should not be impacted by that change.
But still, not everything was sugar and honey of course. This situation shortly evolved into having a lot of microservices, each one talking with everyone else, “tied” together like a spaghetti code in a monolith.
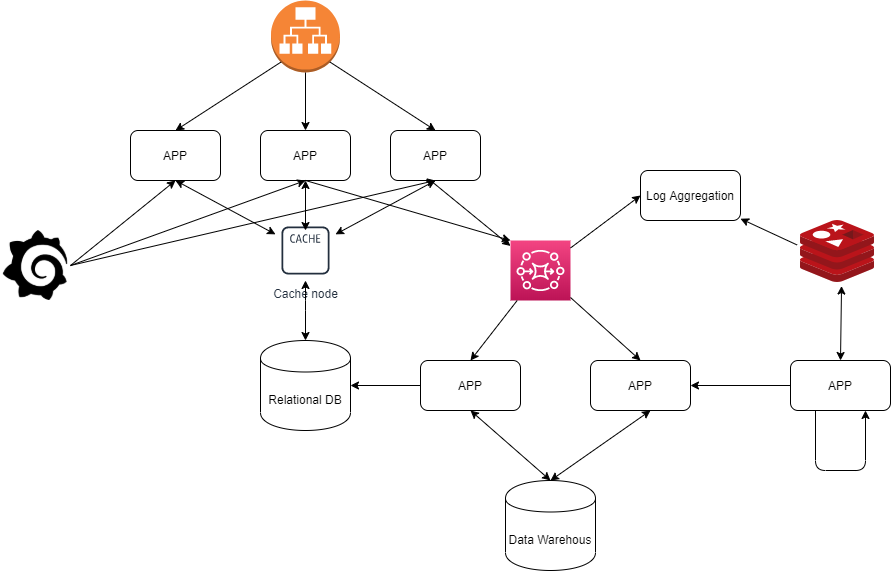
So, instead of having a single monolith, you now have a lot of microservices, which communicate together through REST, Soap, message queues, or other communication channels. This is more scalable indeed. But is this easier to develop? Is it easier to understand the workflow?
The answer is no! It’s even harder. To understand the workflow of a monolith you had to go from method to method and class to class. Now you have to go from microservice to microservice. To make some changes you have to ensure the backward compatibility between microservices.
For testing, instead of doing a synchronous test, you now have to make an async integrated test, consisting of different microservices that talk to each other, and, eventually, are deployed on different instances. It doesn’t seems easier. So was a mistake to move to a microservices approach? The answer is no. We just needed a paradigm change.
Event-Driven Architecture
To overcome these kind of issues, some of the microservices applications have adopted the event-driven architecture. This happened because the event-driven architecture has some characteristics which are suitable for a microservices approach. Let’s have a look on them.
Events Map With the Business Flow
Form a business point of view it's easier to understand and to describe an workflow as a sequence of events. The business man doesn’t care about your internal logic. He sees events.
For example, let’s say we have an online store. You have a few entities like: customer, order, payment and products. And the flow is like that: a customer orders some products and, if the payment is successful, the products should be delivered to the customer. If you implement this in a non event way, your workflow could look something like this:
a customer authenticates using an web interface to the online store.
the customer, through the web interface, opens a http session with the server.
the customer makes a REST call for ordering some products.
on the server side, an order object is created and products are added to it.
the server sends to the customer a payment request.
if the payment is successful the server confirms the order, the warehouse is updated, and the products delivery will begin.
This is fine, but the business man doesn't care about details like REST protocol, sessions, authentication, etc. He says everything like a flow of events, which, as a consequence, could trigger other events:
a customer creates an order
the customer receives a payment request
if the payment is successful the stock is updated and the order is delivered
This is more humanly readable and, if a new business requirement appears, it is easier to change the flow.
Events maps with actions, and the microservices will care just about the events, not about the other microservices. We will have a microservice that will get an event, do some actions, and possibly, send another event.
In our case, a client app will get some input from the customer and it will trigger a create-order event. Some order-service will receive this event, it will create an order and it will send an order-created event to the payment-service. This service will send a payment request to the customer and it will try to validate the payment. If the payment is successful, it will send a payment-successful event to an warehouse-service, which, in turn, it will update the stock and will deliver the products.
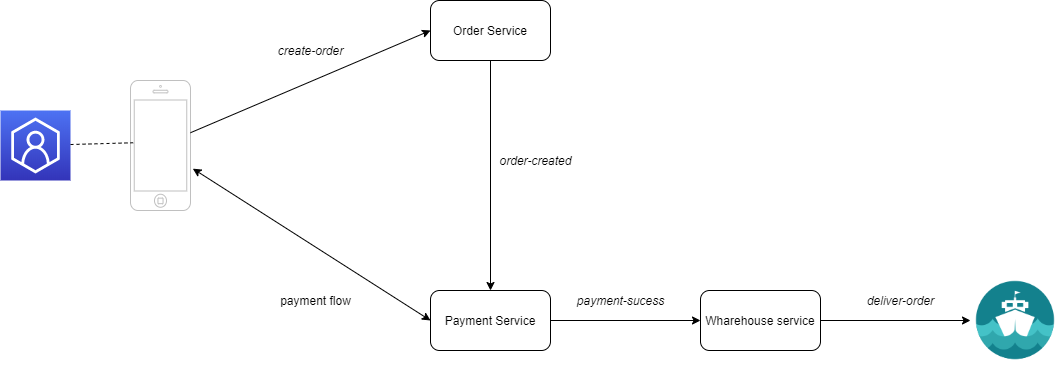
The flow is simpler, and the microservices are decoupled. If you want to add another service that should log the created orders, the changes are minimal. You need to create that service and to subscribe it to the create-order events. Since this would be decoupled from the other services, the original workflow will not suffer any modifications and the risks would be minimal.
Event-Driven Architecture Patterns
Event Driven architecture comes in different flavours. Let’s have a look on the most common patterns.
Event Notification
In this design pattern the events are meant to just notify a state change. They don’t carry any state, they are just telling that something has happened. Usually, the sender doesn’t expect any response. It is not meant for a back and forth communication. An event notification implies a clear separation between the sender and the eventual receivers. As such, there is low coupling between them. Anyone can receive the notification, the sender just doesn’t care.
Let’s have a look on the online-store example to see how this pattern would apply. If a customer completes a payment, then the payment service can send a notification telling that the payment was successful. It doesn't expect anything back. And what the other services will do with this notification, it’s entirely up to them.
Of course, this can bring some disadvantages. If many services are listening for this kind of notification, and if this notification is part of a complex logic, it’s pretty hard to follow the flow and to see what is happening. It could require to inspect the flow on production environment to actually be able to reproduce a problem.
But, despite its disadvantages, considering the low coupling between components and the ease with which you can scale, the event notification pattern is very useful.
Event-Carried State Transfer
As the name suggests, in this pattern the event will contain an entire state not just a notification. All the information that a client needs are contained in that event. The client doesn’t need to call the sender for extra information.
If we look on the previous example, if a customer wants to buy some products, it will select them and it will create an order. Then, the order will be published to the order service. The order event contains all the necessary information to complete the order. The customer details, the billing address, the products, the payment method, etc. It doesn’t need any other detail from the customer.
Obviously, the downside is that you carry a lot of information from a service to another.
Event Sourcing
Another event driven pattern is the event-sourcing. Here, all the events are recorded and the system’s state could be recreated by replying all the events. The entire record base becomes the single source of truth.
A very familiar example is a versioning service like GIT, where the current state is created by replying all the commits. Of course, there are some optimization that you can do. GIT for example, keeps a snapshot alongside with the commits, so when you clone a project, you don’t actually reply all the commits from the beginning, you start from a snapshot. However, the record list is the single source of truth.
This can bring multiple benefits like
Strong audit capabilities. You can see what happened at every point in time.
You can recreate historic states.
You can explore alternative histories by going back to an old state and applying different events.
If you want to find more about event-driven patterns please follow this link.
Kafka and Event-Driven Architecture
There are many technologies these days which you can use to stream events from a component to another, like Aws Kinesis, Apache Flink, Rabbit Mq and many others.
In and this article I want to talk about Apache Kafka, which is maybe the most popular streaming service out there, and why it’s a good fit for Event-driven architecture.
Traditionally there are two kinds of messaging models:
message queues: where a consumer read from the queue.
advantage: The advantage of this messaging type is the scalability. If you need more workers to handle the events you simply add more consumers.
disadvantage: One event is consumed just by one consumer. If you want two different consumers to get the same event, you can’t.
publish-subscriber: where a consumer subscribes to a publisher for getting some kind of events. Using this model more consumer could get the same data. But, since all the messages goes to all the consumers, you can’t parallelize the work.
advantage: the events are distributed to more consumers.
disadvantage: it is not scalable.
Apache Kafka is a distributed streaming platform capable of handling trillions of events per day. Considering it's design, it gives you both the advantages of a queue message and a publish-subscriber service.
How it Works
Kafka stores the events in topics. A topic is a logical split among the data, like a category. For example: all the events corresponding to a customer request can be kept on a dedicated topic called customer-requests and all the events corresponding to a payment received can be held on other topic called payment-received. So, if you want to consume just the customer request then you subscribe to customer-requests topic. This looks like having multiple message queues, one queue per category.
Internally, a topic can be split into partitions. A partition is an ordered, immutable sequence of records.
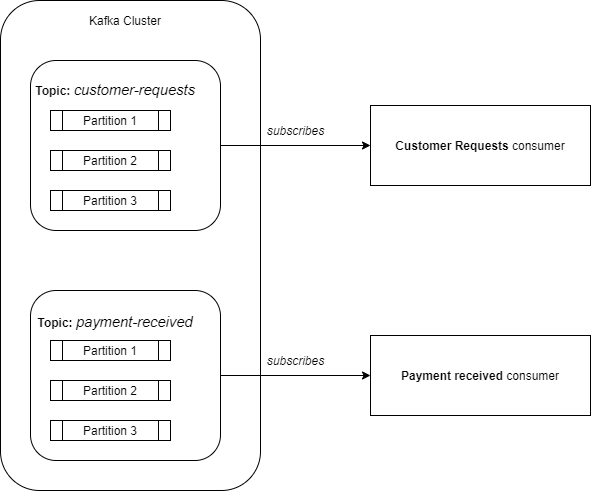
Producers
Producers publish data into topics. Beside this, the producer is also responsible for selecting in which topic partition to put the data. By default, Kafka will calculate the key’s hashcode and uses it to select the partitions.
Consumers
A consumer subscribes to a topic and then it will start to receive data from that topic. Consumers can be define in a consumer-group (which is just a label). But, using this consumer-group is a critical point for scaling the load. The relation between a consumer-group and a kafka topic is like a publish-subscriber service, where the subscriber is the entire consumer-group.
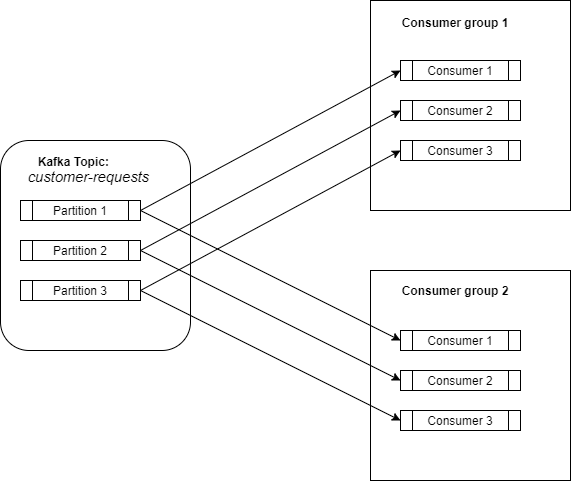
So, all the data from a topic will be distributed to all the consumer groups which are subscribed to that specific topic. Right now, we have all the advantages of a publish-subscriber service, were all the data is distributed to all the subscribers.
Scalability
In this case, how do we scale? Like I said before, the data in a topic is splitted into many partitions, and the consumer-groups consists of different consumers (which can be different processes on different machines).
Kafka ensures that a partition will be consumed by only a single consumer per consumer-group. A consumer can consume data from zero, one, or more partitions.
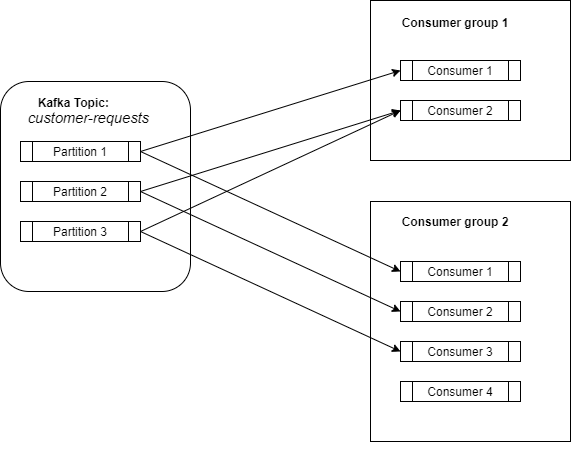
And now, inside a consumer-group, we have a messaging queue, where a consumer goes to a queue and gets one element. And that’s how we obtained scalability. You need more workers? Increase the number of consumer and partitions. Ideally it will be a one-to-one mapping.
And this is how Kafka combines both the advantages of a messaging queue and a publish subscriber, eliminating their disadvantages. The data could be distributed to more consumers without sacrificing the scalability. All this was obtained with the concepts of partitions and consumer group.
Other Advantages
Message Ordering
Kafka doesn’t guarantee the order of the data in a topic, but it does guarantee the order of the data per partition, and, as a partition is consumed by a single consumer per consumer-group, you have the guarantee that those events are consumed in the right order. This is in contrast with a messaging queue, where, even if the events are kept in order, since many consumers get the data concurrently you can’t guarantee the processing order.
Data Distribution
A Kafka cluster can consist of multiple servers, where each server handles a fair share of partitions. But, additionally, the partitions could be replicated to more than one server.
Each partition has a leader which is responsible for populating and handling the read request for that partition. But, since the partition is replicated, if the leader dies, some other follower will become the new leader so no data will be lost.
As such, this kind of distribution guarantees that for a topic with a replication factor N, a Kafka Cluster will tolerate N-1 fails without any data loss.
Storage
In Kafka, the consumers are decoupled from the producers. Producers publish data and consumers come and control what data they want to consume, by specifying the message offset, and how often. As such, Kafka becomes a storage service. The data stays in the cluster for a configured retention time, no matter if the data was read by some consumers or not.
Moreover, since the partitions are replicated for failover, data is implicit replicated. So, like I said before, with a replication factor N, Kafka guarantees no data loss for a maximum of N-1 failures.
Conclusion
These days, especially after the “explosion” of cloud services, we feel the need to migrate to microservices more and more instead of building monoliths. Small decoupled microservices which can be developed separately, with different programming languages, by different teams and which can scale separately by their specific needs. Of course, for achieving a business scope, you need to tie more microservices together.
There are many ways to do this but, as we saw, the event-driven architecture has some characteristics which make it pretty suitable for tying up services together.
An event-driven design comes with the need for a common event channel. Among different solutions out there, Kafka is maybe the most popular one. Combining both the advantages of a publish-subscriber service and a messaging queue, Kafka is a very performant and scalable platform wich can deliver millions of events (or even trillions) per day.
Opinions expressed by DZone contributors are their own.
Comments