Maintaining ML Model Accuracy With Automated Drift Detection
This tutorial demonstrates how to implement automated drift detection, triggers alerts, and automatically retrains models to maintain accuracy in production environments.
Join the DZone community and get the full member experience.
Join For FreeIn production machine learning (ML) systems, data drift is defined as changes in the statistical features of input data over time. Such shifts can weaken model performance, resulting in erroneous predictions. As a result, monitoring and mitigating data drift is critical for maintaining the trustworthiness of machine learning models.
KitOps is an open-source DevOps solution for packaging and versioning AI/ML models, datasets, code, and configurations into a reproducible artifact known as a ModelKit. By standardizing these components, KitOps enables the seamless integration of drift detection and management into MLOps workflows, improving collaboration among data scientists, developers, and operations teams.
Understanding Data Drift
Data drift can take numerous forms:
- Covariate drift. Shifts in the distribution of input features. For example, if a model was trained on customer age data ranging from 20 to 40 years, but the customer base later switches to an age range of 30 to 50 years, the input feature distribution will have shifted.
- Prior probability drift. Refers to shifts in the distribution of the target variable. For example, in a fraud detection model, increasing the fraction of fraudulent transactions over time changes the prior probability of the target variable.
- Concept drift. Shifts in the relationship between input features and target variables. This happens when the underlying patterns that the model has learned shift. For example, if seasonal factors affect sales differently in subsequent years, the model's learned associations may no longer be valid.
Data drift is commonly caused by changes in user behavior, market dynamics, or external variables influencing the data-generation process. To maintain long-term model accuracy and reliability, these drifts must be detected and addressed early.
Setting Up the Environment
Our use case involves monitoring an Iris classification model for data drift. By identifying and addressing drift early, we can ensure that the model remains reliable and continues to deliver accurate predictions. Therefore, to effectively monitor and manage data drift in a time-series forecasting model, follow these steps:
Install and Download the KitOps CLI and Required Libraries
Visit the KitOps GitHub Releases page and download the appropriate version for your operating system. Ensure that Python 3.8+ and essential libraries like scikit-learn and pandas are installed.
Load and Split Data
We will create a file for data loading and pre-processing, and we will start by loading the Iris dataset and splitting it into training and testing sets.
# data_loading.py
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def load_and_split_data(test_size=0.2, random_state=42):
"""
Loads the Iris dataset and splits it into training and test sets.
"""
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=test_size, random_state=random_state
)
return X_train, X_test, y_train, y_testThis function divides the dataset into training and testing sets, ensuring a proper foundation for model training and drift detection.
Train and Save the Model
Next is training and saving the trained model. For this, we will create another Python script, as this training file also supports retraining the model, which will be explained later in the blog.
# model_training.py
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
import joblib
import pandas as pd
def train_and_save_model(X_train, y_train, model_path='iris_model.pkl', stats_path='feature_stats.csv'):
"""
Trains a RandomForest model, saves it, and updates feature statistics.
Parameters:
X_train (ndarray): Training feature data.
y_train (ndarray): Training labels.
model_path (str): Path to save the trained model.
stats_path (str): Path to save feature statistics.
"""
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
joblib.dump(model, model_path)
# Save feature statistics
df_train = pd.DataFrame(X_train, columns=load_iris().feature_names)
feature_stats = df_train.describe().transpose()
feature_stats.to_csv(stats_path)
print("Model and feature statistics saved successfully.")
This step generates a trained model iris_model.pkl and a feature_stats.csv file containing statistical summaries of the training data.
Initialize Drift Detectors and Alerts
We will also set up some drift detectors using the training data statistics, as we will be using Kolmogorov-Smirnov (KS) drift detection to monitor feature-level drifts. Moreover, we will add code to detect potential drifts in the new dataset using initialized detectors.
# drift_detection.py
import pandas as pd
import numpy as np
from scipy.stats import ks_2samp
def load_feature_stats(stats_path='feature_stats.csv'):
return pd.read_csv(stats_path, index_col=0)
def check_for_drift(new_data, stats_path='feature_stats.csv', significance_level=0.05):
feature_stats = load_feature_stats(stats_path)
drift_alerts = []
for feature in feature_stats.index:
old_mean = feature_stats.loc[feature, 'mean']
old_std = feature_stats.loc[feature, 'std']
# Generate synthetic baseline data from stored stats
baseline_data = np.random.normal(loc=old_mean, scale=old_std, size=1000)
new_feature_data = new_data[feature].values
# Perform KS test
ks_stat, p_val = ks_2samp(baseline_data, new_feature_data)
if p_val < significance_level:
drift_alerts.append(f'Drift detected in feature: {feature}')
return drift_alerts
Creating Main.py File
This main.py file allows to check for new data, provide drift detection and allows the model for retraining if the data drift is detected.
# main.py
from data_loading import load_and_split_data
from model_training import train_and_save_model
from drift_detection import check_for_drift
from sklearn.datasets import load_iris
import pandas as pd
import joblib
MODEL_PATH = "iris_model.pkl"
STATS_PATH = "feature_stats.csv"
def main():
# Load and split data
X_train, X_test, y_train, y_test = load_and_split_data()
# Load the model (if exists)
try:
model = joblib.load(MODEL_PATH)
print("Model loaded successfully.")
except FileNotFoundError:
print("No existing model found. Training a new model.")
train_and_save_model(X_train, y_train, MODEL_PATH, STATS_PATH)
# Monitor for drift
new_data = pd.DataFrame(X_test, columns=load_iris().feature_names)
drift_alerts = check_for_drift(new_data, STATS_PATH)
if drift_alerts:
print("\nData drift detected!")
for alert in drift_alerts:
print(alert)
# Retrain the model if drift is detected
print("\nRetraining model due to drift...")
train_and_save_model(X_train, y_train, MODEL_PATH, STATS_PATH)
print("Model retrained and saved.")
if __name__ == "__main__":
main()
Creating a Kitfile and Packaging Your Project
A Kitfile is a YAML-based manifest that defines the components of your AI/ML project, including models, datasets, code, and documentation. By creating a Kitfile, you can package your project into a ModelKit, facilitating easy sharing and deployment.
Therefore, in your project directory, create a file named Kitfile (without any extension) and define its structure as follows:
manifestVersion: '1.0.0'
package:
name: IrisModelWithDriftDetection
version: '1.0.0'
description: A RandomForest model trained on the Iris dataset with integrated data drift detection.
authors:
- Siddhesh Bangar
code:
- path: ./src/data_loading.py
description: Script for loading and splitting the Iris dataset.
license: MIT
- path: ./src/model_training.py
description: Script for training the RandomForest model and saving feature statistics.
license: MIT
- path: ./src/drift_detection.py
description: Script for initializing drift detectors and monitoring new data.
license: MIT
- path: ./src/main.py
description: Main script to orchestrate data loading, model training, and drift detection.
license: MIT
datasets:
- name: Iris Dataset
path: ./data/iris_data.csv
description: The UCI Iris dataset used for model training.
license: CC BY 4.0
- name: Feature Statistics
path: ./data/feature_stats.csv
description: This Feature Stats gets updated based on data drift detection.
license: CC BY 4.0
model:
name: RandomForestClassifier
path: ./models/iris_model.pkl
framework: scikit-learn
version: '1.0.0'
description: RandomForest model trained on the Iris dataset.
This structure specifies the metadata, code, model, datasets, and documentation included in your ModelKit. For more details on Kitfile structure, refer to the Kitfile Overview.
Package the ModelKit
With the Kitfile in place, use the kit pack command to package your project. Here, I am saving my model files in jozu.ml registry, so the command would be:
kit pack . -t jozu.ml/siddhesh-bangar/iris-model:1.0.0But you can save your model files in various other registries (Github, Docker, etc.). This command packages your project into a ModelKit and tags it appropriately. For more information on the kit pack command, see the Kit CLI Reference.
Use a kit list command to check if you have packed your ModelKit. If yes, it will be shown in your packed ModelKit list.

Push the ModelKit to a Remote Registry
To share your ModelKit, first log in to your registry and then push it to a remote registry using the following commands:
kit login REGISTRY_NAME -u USERNAME -p PASSWORD
kit push jozu.ml/siddhesh-bangar/iris-model:1.0.0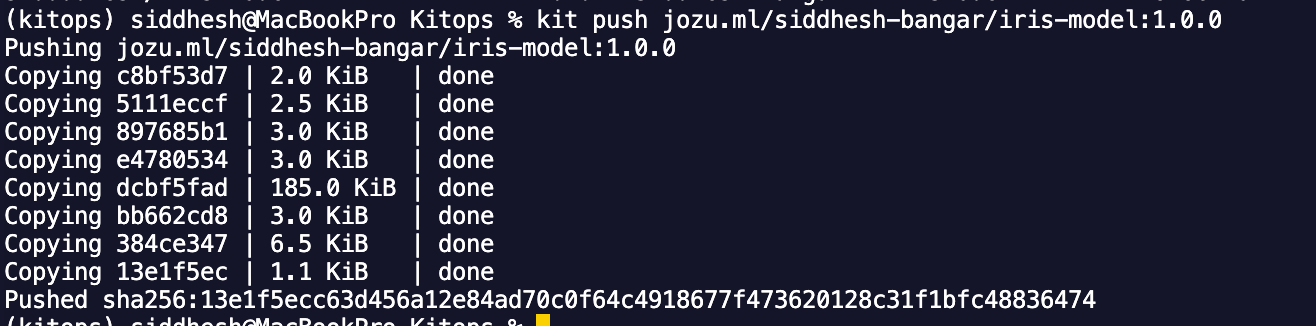
After logging in, the kit push command uploads your ModelKit to the specified registry, making it accessible for others to pull and use.
Testing Data Drift
Before simulating drift, let’s first run the system with normal data. You can train the model by executing:
python main.pyThis is supposed to show if you are training your model for the first time and you don’t have the iris_model.pkl file and feature_stat.csv file in your models and dataset folder, respectively.

If a model already exists:

Since the model is trained on the Iris dataset, no drift will be detected initially.
Simulating Data Drift
We now simulate drift by modifying feature distributions. The easiest way to do this is to increase or decrease the values of one or more features.
First, we will create a script for manually creating new_data.csv, which will help us detect drift in the machine learning model pipeline.
# simulate_drift.py
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
# Load the original Iris dataset
iris = load_iris()
new_data = pd.DataFrame(iris.data, columns=iris.feature_names)
# Introduce drift by shifting feature distributions
new_data.iloc[:, 0] += np.random.normal(loc=5, scale=2, size=new_data.shape[0]) # Large shift in feature 1
new_data.iloc[:, 1] *= 1.5 # Scale feature 2 by 1.5 times
new_data.iloc[:, 2] -= np.random.uniform(2, 5, size=new_data.shape[0]) # Decrease feature 3 values
new_data.iloc[:, 3] = np.random.normal(loc=10, scale=3, size=new_data.shape[0]) # Replace feature 4 with new distribution
# Save the new drifted data
new_data.to_csv("new_data.csv", index=False)
print("Drifted data saved as new_data.csv")
Running Drift Detection on Modified Data
Next, you can modify the main.py and add the new data to the training pipeline so that data drift can be detected.
# Modified main.py
from data_loading import load_and_split_data
from model_training import train_and_save_model
from drift_detection import check_for_drift
import pandas as pd
import joblib
MODEL_PATH = "iris_model.pkl"
STATS_PATH = "feature_stats.csv"
def main():
# Load and split data
X_train, X_test, y_train, y_test = load_and_split_data()
# Load the model (if exists)
try:
model = joblib.load(MODEL_PATH)
print("Model loaded successfully.")
except FileNotFoundError:
print("No existing model found. Training a new model.")
train_and_save_model(X_train, y_train, MODEL_PATH, STATS_PATH)
# Monitor data drift
# Load new test data from CSV (Fixed the issue)
try:
new_data = pd.read_csv("new_data.csv")
except FileNotFoundError:
print("Error: 'new_data.csv' not found! Make sure to create or generate drifted data.")
return
# Check for drift
drift_alerts = check_for_drift(new_data, STATS_PATH)
if drift_alerts:
print("\nData drift detected!")
for alert in drift_alerts:
print(alert)
# Retrain model if drift is detected
print("\nRetraining model due to drift...")
train_and_save_model(X_train, y_train, MODEL_PATH, STATS_PATH)
print("Model retrained and saved.")
else:
print("No drift detected. Model remains unchanged.")
if __name__ == "__main__":
main()
The output should show something like this:
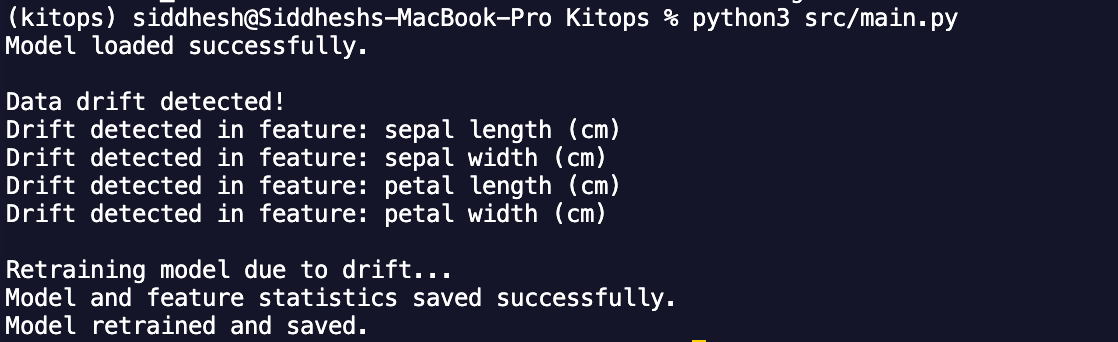
You can verify the model updates by checking that iris_model.pkl and feature_stats.csv have been updated. Run the script again without modifying new_data.csv. The model should now not detect drift since the stats are updated.
Later, make changes in the Kitfile, which includes the version (For example, 1.0.1). You can pack the Kitfile and then push it again through the kit pack and push the commands mentioned above.
Track Retrained Models and Enable Rollbacks
KitOps manages model versions through ModelKits, allowing you to track retrained models and perform rollbacks if necessary.
Versioning
Each retrained model is assigned a unique version in the Kitfile.
KitOps maintains a history of your ModelKits, allowing you to track different versions effectively.kit list as explained previously
This command displays all ModelKits in your local repository, including their versions and associated metadata.
Rollback
To revert to a previous model version, use the KitOps CLI to pull and deploy the desired ModelKit.
If you need to revert to a prior model version, KitOps simplifies the process.
kit pull your_registry_address/your_username/retrained_model:1.0.0Replace 1.0.0 with the version number you wish to deploy. After pulling, deploy the model as per your deployment pipeline requirements.
By following these steps, you can automate the detection of data drift, retrain your machine learning models accordingly, and manage model versions effectively using KitOps.
Conclusion
Monitoring and managing data drift is critical for maintaining robust machine learning models in production environments. With KitOps, integrating drift detection, automating retraining pipelines, and managing model versions becomes seamless.
By following the outlined process:
- You can detect feature drift effectively using statistical measures and automated alerts.
- Automate the retraining of models to address detected drift and ensure model reliability.
- Leverage KitOps for version control, enabling efficient tracking and rollback of models.
The combination of these capabilities ensures that your models remain accurate and trustworthy in dynamic environments. With tools like KitOps, organizations can confidently deploy, monitor, and manage machine learning models, enhancing operational efficiency and reliability.
Opinions expressed by DZone contributors are their own.
Comments