Increase Model Flexibility and ROI for GenAI App Delivery With Kubernetes
Kubernetes enables a multiple model operating approach for GenAI app delivery that can increase innovation while reducing costs.
Join the DZone community and get the full member experience.
Join For FreeAs with past technology adoption journeys, initial experimentation costs eventually shift to a focus on ROI. In a recent post on X, Andrew Ng extensively discussed GenAI model pricing reductions. This is great news, since GenAI models are crucial for powering the latest generation of AI applications. However, model swapping is also emerging as both an innovation enabler, and a cost saving strategy, for deploying these applications. Even if you've already standardized on a specific model for your applications with reasonable costs, you might want to explore the added benefits of a multiple model approach facilitated by Kubernetes.
A Multiple Model Approach to GenAI
A multiple model operating approach enables developers to use the most up-to-date GenAI models throughout the lifecycle of an application. By operating in a continuous upgrade approach for GenAI models, developers can harness the specific strengths of each model as they shift over time. In addition, the introduction of specialized, or purpose-built models, enables applications to be tested and refined for optimal accuracy, performance and cost.
Kubernetes, with its declarative orchestration API, is perfectly suited for rapid iteration in GenAI applications. With Kubernetes, organizations can start small and implement governance to conduct initial experiments safely and cost-effectively. Kubernetes’ seamless scaling and orchestration capabilities facilitate model swapping and infrastructure optimization while ensuring high performance of applications.
Expect the Unexpected When Utilizing Models
While GenAI is an extremely powerful tool for driving enhanced user experience, it's not without its challenges. Content anomalies and hallucinations are well-known concerns for GenAI models. Without proper governance, raw models—those used without an app platform to codify governance— are more likely to be led astray or even manipulated into jailbreak scenarios by malicious actors. Such vulnerabilities can result in financial loss amounting to millions in token usage and severely impact brand reputation. The financial implications of security failures are massive. A report by Cybercrime Magazine earlier this year suggests that cybercrime will cost upwards of $10 trillion annually by next year. Implementing effective governance and mitigation, such as brokering models through a middleware layer, will be critical to delivering GenAI applications safely, consistently, and at scale.
Kubernetes can help with strong model isolation through separate clusters and then utilize a model proxy layer to broker the models to the application. Kubernetes' resource tagging adds another layer of value by allowing you to run a diverse range of model types or sizes, requiring different accelerators within the same infrastructure. This flexibility also helps with budget optimization, as it prevents defaulting to the largest, most expensive accelerators. Instead, you can choose a model and accelerator combo that strike a balance between excellent performance and cost-effectiveness, ensuring the application remains efficient while adhering to budget constraints.
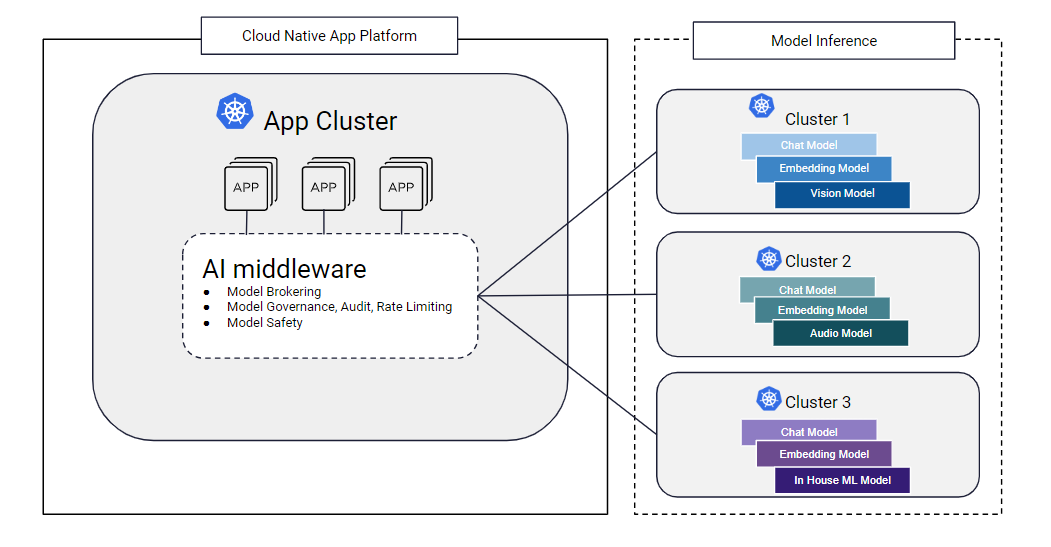
Example 1: Model curation for additional app platform governance and flexibility
Moreover, role-based access controls in Kubernetes ensures that only authorized individuals or apps can initiate requests to certain models in an individual cluster. This not only prevents unnecessary expenses from unauthorized usage, but also enhances security across the board. Additionally, with the capacity to configure specific roles and permissions, organizations can better manage and allocate resources, minimize risks, and optimize operational efficiency. Rapidly evolving GenAI models benefit from these governance mechanisms while maximizing potential benefits.
Scaling and Abstraction for GenAI! Oh My!
The scale of the model you choose for your GenAI application can vary significantly depending on the applications’ requirements. Applications might work perfectly well with a simple, compact, purpose-built model versus a large, complex model that demands more resources. To ensure the optimal performance of your GenAI application, automating deployment and operations is crucial. Kubernetes can be made to facilitate this automation across multiple clusters and hosts using GitOps or other methodologies, enabling platform engineers to expedite GenAI app operations.
One of the critical advantages of using Kubernetes for delivering GenAI apps is its ability to handle GPU and TPU accelerated workloads. Accelerators are essential for training and inferencing of complex models quickly and efficiently. With Kubernetes, you can easily deploy and manage clusters with hardware accelerators, allowing you to scale your GenAI projects as needed without worrying about performance being limited by hardware. The same can be said for models optimized for modern CPU instruction sets which helps avoid the need to schedule for more scarce GPUs and TPUs resources.
In addition to handling GPU-accelerated workloads, Kubernetes also has features that make it well-suited for inferencing tasks. By utilizing capabilities like Horizontal Pod Autoscaling, Kubernetes can dynamically adjust resources based on the demand for your inferencing applications. This ensures that your applications are always running smoothly and can handle sudden spikes in traffic. On top of all this, the ML tooling ecosystem for Kubernetes is quite robust and allows for keeping data closer to the workloads. For example, JupyterHub can be used to deploy Jupyter notebooks right next to the data with GPUs auto-attached, allowing for enhanced latency and performance during the model experimentation phase.
Getting Started With GenAI Apps With Kubernetes
Platform engineering teams can be key enablers for GenAI application delivery. By simplifying and abstracting away complexity from developers, platform engineering can facilitate ongoing innovation with GenAI by curating models based on application needs. Developers don't need to acquire new skills in model evaluation and management; they can simply utilize the resources available in their Kubernetes-based application platform. Also, platform engineering can help with improved accuracy and cost effectiveness of GenAI apps by continuously assessing accuracy and optimizing costs through model swapping. With frequent advancements and the introduction of smaller GenAI models, applications can undergo refinements over time.
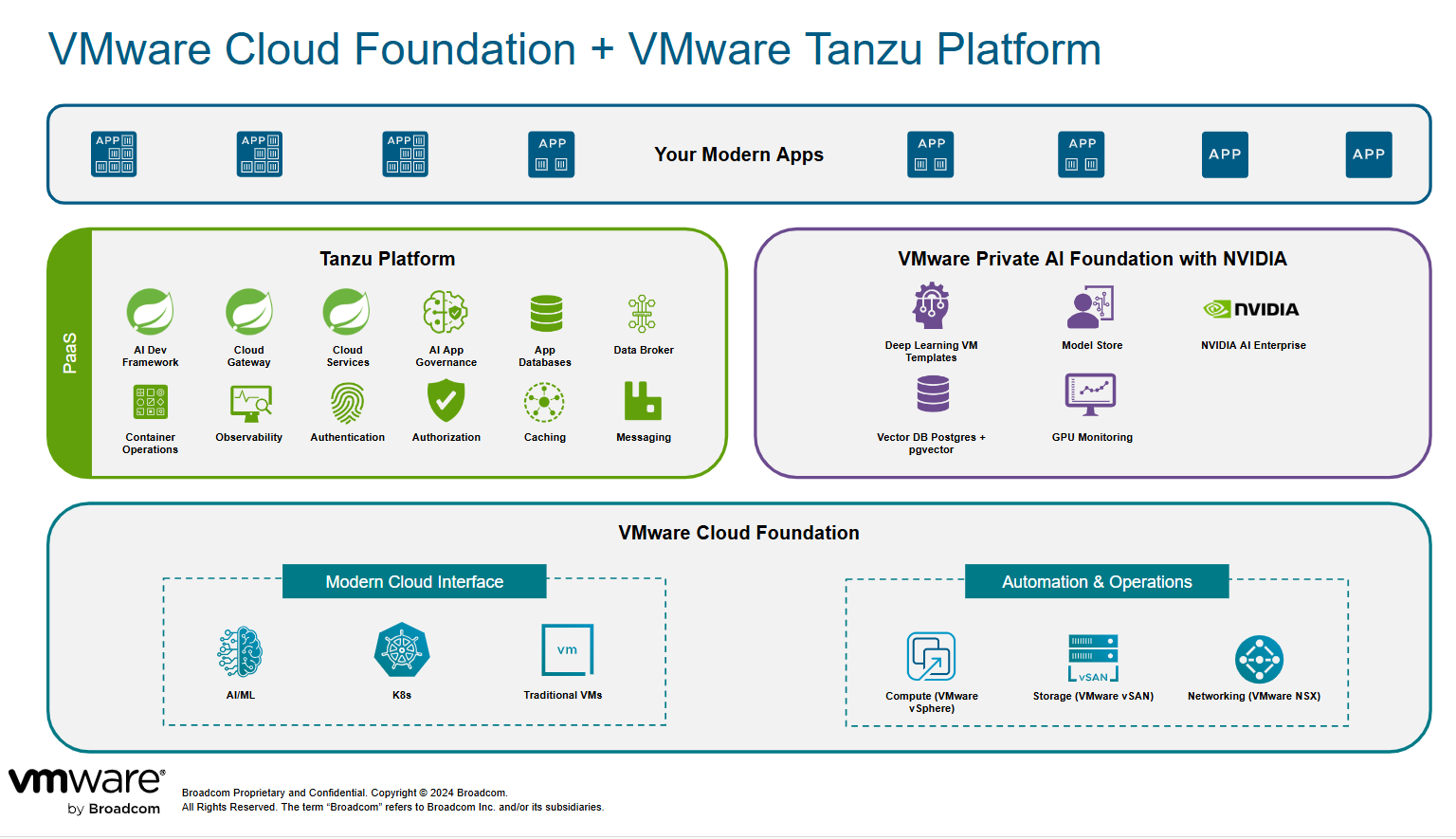
Kubernetes is pivotal in this continuous GenAI model upgrade approach, offering flexibility to accommodate model changes while adding access governance to the models. Kubernetes also facilitates seamless scaling and optimization of infrastructure while maintaining high-performance applications. Consequently, developers have the freedom to explore various models, and platform engineering can curate and optimize placement for those innovations.
This article was shared as part of DZone's media partnership with KubeCon + CloudNativeCon.
View the Event
Opinions expressed by DZone contributors are their own.
Comments