Moving From Apache Thrift to gRPC: A Perspective From Alluxio
Explore moving from Apache Thrift to gRPC.
Join the DZone community and get the full member experience.
Join For Free
As part of the Alluxio 2.0 release, we have moved our RPC framework from Apache Thrift to gRPC. In this article, we will talk about the reasons behind this change as well as some lessons we learned along the way.
Alluxio is an open-source distributed virtual file system, acting as the data access layer that enables big data and ML applications to process data from multiple heterogeneous storage systems with locality and many other benefits. Alluxio is built with a master/worker architecture where masters handle metadata operations and workers handle requests to read and write data. In Alluxio 1.x, the RPC communication between clients and servers is built mostly on top of Apache Thrift. Thrift enabled us to define Alluxio service interface in simple IDL files and implement client binding using native Java interfaces generated by Thrift compiler. However, we faced several challenges as we continued developing new features and improvements for Alluxio.
Limitation of Apache Thrift
One of the biggest drawbacks of Thrift is the lack of support for streaming large amounts of data, which is critical for Alluxio to serve data-intensive workloads as a distributed file system. In Alluxio 1.x, we implemented a light-weight data streaming framework as a workaround on top of Netty, which is a Java-based asynchronous event-driven network framework. Here is an illustration of our architecture in terms of RPC clients and servers:
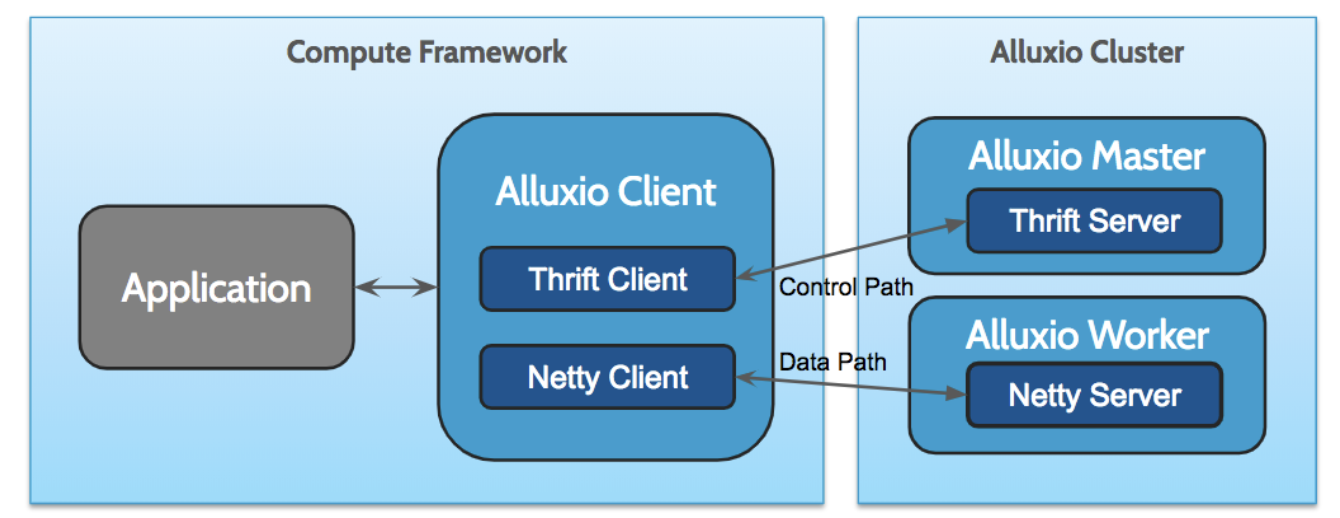
While Netty provides a high-performance and flexible network API, its programming interface is in a fairly low level and requires us to implement a lot of higher-level but important functions on top of it, such as flow control and file system authentication. Not only does this make it more expensive to implement new service endpoints, but it also heavily increases the complexity of the Alluxio client, making it more difficult to provide client bindings for new languages.
This architecture also requires us to maintain two network stacks: the master control RPC services built with Thrift and the worker data/control RPC services built with Netty. Defining services in two different ways makes the codebase harder to maintain and reason. For each common feature used across services, we also need to provide two implementations, adding more workload to the engineering team.
Benefit of gRPC
gRPC is a high-performance open-source RPC framework developed by Google. Since its release in 2015, it has matured quite a lot and become one of the most popular options for cross-language RPC communication. There are many good features, some of the ones we benefit the most from are:
Built-in streaming RPC support: This means that we can use the same RPC framework to handle one-off RPC calls on the control paths as well as data transfer through chunking. This will greatly help us unify the network code path and simplify the logic.
The interceptor API: The gRPC interceptor API provides a powerful way to add common functionalities to multiple service endpoints. This makes it easy for us to implement health check and authentication shared by master and worker interfaces.
Built-in flow control and TLS support: Built on top of HTTP/2 protocol, gRPC comes with many great features that we previously had to implement on top of Netty. This helps us keep the client simpler and makes it easy to implement more language bindings.
Excellent community support: As an open source project, gRPC is growing really fast with good community support and maintenance. Its documentation is also rich and helpful.
Implementation
We started looking into the migration last year. We went through initial design and prototype to solve some technical challenges, as well as early benchmarks to understand the performance capability. The following diagram shows the newly unified network stack with gRPC in place:
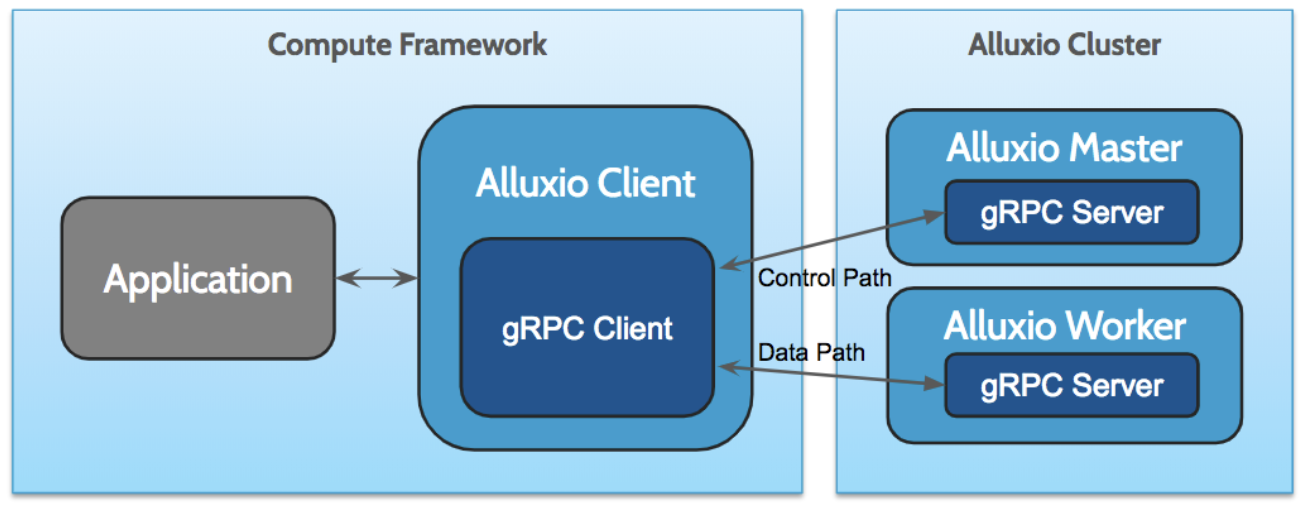
Replacing the RPC framework is non-trivial work. A lot of code was added, refactored, and most importantly, simplified to work with the new APIs. There are several challenges we faced during the implementation phase.
One issue we encountered is related to the release of gRPC channels. When channels are shut down concurrently, some underlying HTTP/2 messages could end up getting ping-ponged between the client and server (This looked like an aggravated variance of this issue). Increased occurrences of such stale messages can cause cascading performance degradation, especially in a testing environment where channels are recycled rapidly. We have observed that serializing the shutdown of gRPC channels solved this issue.
Another challenge is the lack of support for Java SASL authentication. Although gRPC comes with TLS and OAuth support, it, unfortunately, does not provide a way to secure RPC with SASL authentication framework. To work around this problem, we built our own authentication layer by implementing a dedicated authentication service endpoint and initiating an authentication handshake using interceptors.
Building with gRPC as a Java module dependency can also cause some issues, especially when it is built into Alluxio client jar, which will be loaded into 3rd-party application JVM. Since gRPC depends on the very popular protobuf module, packing gRPC and protobuf to our client jar can easily cause protobuf version conflict with applications that also depend on protobuf. We solved this problem by relocating the gRPC and protobuf modules within Alluxio client.
Besides dealing with functionality challenges, a lot of time is spent on tuning the performance. Here are the things we have learned:
Pick the right executor: Executors provided during the initialization of gRPC client/server plays an important role in the request throughput the server can achieve. gRPC requests are not bound to a dedicated thread but instead distributed to an executor thread pool. We have observed some significant contention with the default cached executor thread pool. To mitigate that, we have tried a couple of different executors. We played with
FixedThreadPool, which provides good blocking RPC performance. However, it performs unacceptably worse for non-blocking RPCs because it only uses a single task queue. We also triedForkJoinPool, which internally distributes work across many queues and does “work stealing” for maintaning the balance between them. For non-blocking RPCs, we have seen the best performance when usingForkJoinPool. For blocking RPCs, it provides a managed blocking API for the purpose of receiving hints in case a worker is getting blocked, with which we were able to achieve a throughput very close to the throughput when usingFixedThreadPool. In the end, we choseForkJoinPooloverFixedThreadPoolfor a generally more favorable throughput in more common Alluxio use cases.
The experiments with executors are mostly focused on improving the throughput of handling metadata requests. We have also done a lot of work to improve data transfer performance. Here are some tips for streaming data efficiently with gRPC:
Use multiple channels for maximum throughput: While most short RPC calls benefit from multiplexing, data transfer requires utilizing all network bandwidth, which a single connection does not provide. As recommended by the gRPC team, we switched to using multiple channels to max out our data transfer throughput.
Use a bigger chunk size: There is some overhead associated with sending each message, such as message headers and context switching. The smaller each chunk is, the more chunks the pipeline will have to process for the same amount of data, which, in turn, will introduce more overhead. We end up using a relatively big chunk size to minimize such impact.
Don't throw away Netty: even though all data are sent via gRPC. Given that gRPC does not expose a public interface that works with Netty
ByteBuf, we switched to using Java NIOByteBufferin our early implementation of gRPC service endpoints. That turned out to introduce some significant bottleneck even though we used off-heap buffers. The lesson learned here is to not get rid of Netty just because gRPC doesn’t expose interfaces with Netty buffers. Netty provides some very efficient APIs for managing buffers, which will keep things fast outside of the gRPC pipeline.Implement zero-copy: Another overhead we observed switching to gRPC is excessive buffer copying. This is because gRPC, by default, uses protobuf for message serialization, which introduces extra copy operations. There is currently no official API for getting raw buffers in and out of gRPC without having to go through protobuf serialization or throw away the nice generated RPC bindings. We end up using some ideas from the gRPC user group and implemented a workaround to achieve zero-copy.
Use manual back pressure control: Back pressure control in gRPC Java SDK is provided through the
isReadyflag andonReadyevent from the stream observers. It triggers theonReadyevent once the data in the buffer is less than 32KB. This is a relatively small buffer size and can cause some contention as the sender keeps waiting for the data to be removed from the buffer, especially since we bumped up the chunk size. Unfortunately, as of now, there is no way we can adjust the buffer size. We end up implementing manual back pressure control with which we were able to achieve some more improvement on throughput.
Conclusion
Thrift served well as a fast and reliable RPC framework powering the metadata operations in Alluxio 1.x. Its limitation in handling streamed data has led us to a journey in search of better alternatives. gRPC provides some nice features that help us in building a simpler, more unified API layer. In this post, we discussed some lessons learned to move from Thrift to gRPC, including performance tuning tips that helped us achieve comparable performance for both one-off RPC calls as well as data streams. We hope this helps if you are looking at gRPC as an option for building high-performance services. Check out our blog for more articles on how we build Alluxio.
Opinions expressed by DZone contributors are their own.
Comments