MuleSoft: Salesforce.com and Bulk API Query with Primary Key (PK) Chunking
It takes some grit work to get a mass amount of data from Salesforce.com using the Bulk API and PK chunking in Mule flows.
Join the DZone community and get the full member experience.
Join For FreeAmong the many powerful connectors MuleSoft has in its repository, the Salesforce.com connector is one of the most used. I've used the Salesforce connector to update and insert (upsert) data into sObjects using both the SOAP API and Bulk API, but recently, it was mentioned to me that a group of data scientists wanted to get an export of some of the Salesforce objects. I've seen the "Bulk Query" operations in the Salesforce connector, so I immediately said "Yeah, sure! It can be done. Anything can be done with MuleSoft."
Before I took on the task, I ran the query in the Salesforce developer workbench. The batch job failed due to too many retries. There is a limit of 15 retries before the Salesforce servers deem the query as a failure. I also created a Bulk Query using the Salesforce connector and it, too, failed.
Doing some reading, I realized that I needed to enable a special feature called Primary Key (PK) chunking. I thought, "OK...shouldn't be too difficult." I went through every operation and discovered no way to use the connector with PK chunking. I opened a support ticket with MuleSoft and their engineers acknowledged the connector didn't have this feature. The "PK chunking" option will be added to a future connector. Cool, a feature request is added to the backlog at MuleSoft.However, I still needed to export the Salesforce data. I had to do some reading on the Bulk API.
I used the Salesforce Bulk API Developer Guide to execute the examples with my query to be sure I could retrieve the data using their cURL examples with PK chunking and to understand the object types needed when checking the batch jobs and retrieving the resulting data.
What is PK chunking? PK chunking takes a query and splits it up by the Primary Key (or ID) and retrieves a set number of records per batch. Salesforce has PK chunking documented on their developer site.
This article explains how to get a mass amount of data from Salesforce using the Bulk API and PK chunking in Mule flows. This project is written in the perspective of happy Path, therefore, it's lacking exception policies and parallel retrieving (that's on my to-do list).
Assumptions:
Understanding of MuleSoft Anypoint Studio and the project building process.
Understanding of Salesforce object structures, SOQL, and the Bulk API usages.
Knowledge of how to create a Salesforce Connector Configuration.
This project was built with the following MuleSoft versions:
MuleSoft EE 3.8.1.
Salesforce Connector 8.1.0.
Limitations of the Salesforce Bulk Query are:
Retrieved File Size (batch file): 1GB.
Number of attempts to query: 15 attempts at 10 minutes each to process the batch.
Query processing: Two-minute limit to process the query. If the query doesn't start in two minutes, an error of QUERY_TIMEOUT will return.
The bulk API query doesn't support the following SOQL:
COUNT.
ROLLUP.
SUM.
GROUP BY CUBE.
OFFSET.
Nested SOQL queries (join).
Relationship fields (i.e., relationship__r).
Breakdown of a Bulk Query Application
I am going to explain the MuleSoft process to create a bulk API query job with PK chunking and retrieve the results.
Note: The global configurations and property values have been left out of this article.
Bulk_API_Query_Main Flow
This flow is self-explanatory. It's configured with a synchronous processing strategy to make sure events end before the next flow starts.
Visual:
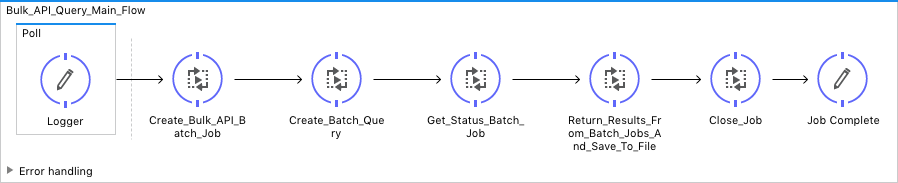
XML:
<flow name="Bulk_API_Query_Main_Flow" processingStrategy="synchronous">
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="1000"
timeUnit="DAYS" />
<logger message="#["Start time is " + server.dateTime]"
level="INFO" doc:name="Logger" />
</poll>
<flow-ref name="Create_Bulk_API_Batch_Job" doc:name="Create_Bulk_API_Batch_Job" />
<flow-ref name="Create_Batch_Query" doc:name="Create_Batch_Query" />
<flow-ref name="Get_Status_Batch_Job" doc:name="Get_Status_Batch_Job" />
<flow-ref name="Return_Results_From_Batch_Jobs_And_Save_To_File"
doc:name="Return_Results_From_Batch_Jobs_And_Save_To_File" />
<flow-ref name="Close_Job" doc:name="Close_Job" />
<logger
message="#["The job is complete. The number of records processed were: " + payload.numberRecordsProcessed + ". The total processing time was: " + flowVars.totalTime + " minutes."]"
level="DEBUG" doc:name="Job Complete" />
</flow>Create_Bulk_API_Batch_Job Flow
The Salesforce connector does not have the PK chunking header option. This is a manual flow to create the Bulk Batch Query Job.
Visual:

Looking closer at the XML, notice that I create an XML body payload (lines seven through 16). The options include the operation, object, concurrencyMode, and contentType. Use the API reference if you want to use a different return payload, the choices are CSV, JSON, and XML.
Lines 23 through 27 set up the PK chunking header. In this example, I set the value to "true." If you want different chunking sizes, or use a parent or refer to the Bulk API Guide or the PK chunking documentation website for all the options.
XML:
<sub-flow name="Create_Bulk_API_Batch_Job">
<sfdc:get-session-id config-ref="Salesforce__Basic_Authentication"
doc:name="Salesforce" />
<set-variable variableName="sessionId" value="#[payload]"
doc:name="set sessionId" />
<logger message="#[flowVars.sessionId]" level="DEBUG" doc:name="Logger" />
<set-payload
value="<?xml version="1.0" encoding="UTF-8"?>
<jobInfo
xmlns="http://www.force.com/2009/06/asyncapi/dataload">
<operation>query</operation>
<object>${sfdc.object}</object>
<concurrencyMode>Parallel</concurrencyMode>
<contentType>CSV</contentType>
</jobInfo>"
encoding="UTF-8" mimeType="application/xml" doc:name="Set POST Body message" />
<until-successful maxRetries="5"
failureExpression="#[message.inboundProperties['http.status'] != 201]"
synchronous="true" doc:name="Until Successful">
<http:request config-ref="Create_SFDC_BulkAPI_Job" path="/services/async/38.0/job"
method="POST" metadata:id="a5678fac-1111-1234-81b7-e30000015f"
doc:name="Create Batch Query Job">
<http:request-builder>
<http:header headerName="Sforce-Enable-PKChunking"
value="true" />
<http:header headerName="X-SFDC-Session" value="#[flowVars.sessionId]" />
</http:request-builder>
<http:success-status-code-validator
values="200..599" />
</http:request>
</until-successful>
<logger message="#[xpath3('//*[local-name()="id"]')]"
level="DEBUG" doc:name="Logger" />
<set-variable variableName="jobId"
value="#[xpath3('//*[local-name()="id"]')]" doc:name="Set JobId" />
<sfdc:job-info config-ref="Salesforce__Basic_Authentication"
jobId="#[flowVars.jobId]" doc:name="Salesforce" />
</sub-flow>Create_Batch_Query Flow
This is a self-explanatory flow. It uses the Salesforce connector to create the batch query job using the bulk job ID in the previous step.
Visual:

XML:
<sub-flow name="Create_Batch_Query">
<sfdc:create-batch-for-query config-ref="Salesforce__Basic_Authentication"
query="${sfdc.query}" doc:name="Create a batch query for the created job">
<sfdc:job-info ref="#[payload]" />
</sfdc:create-batch-for-query>
</sub-flow>Get_Status_Batch_Job Flow
This flow will halt the application for five minutes to allow the batch query jobs to complete. This flow needs some work. I need to add additional logic to the Groovy script to check for failures and InProcesses states. Remember: Happy path.
Visual:
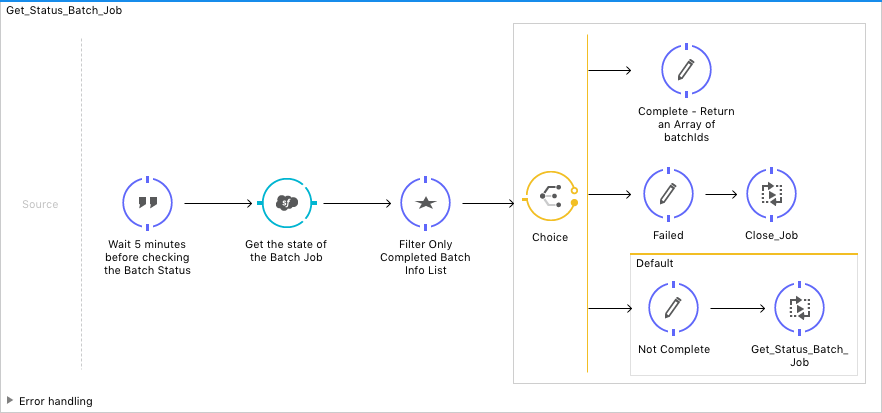
The Groovy script on lines nine through 11 consumes the batchInfoList object returned from Salesforce, then iterates through the elements and returns the batch job IDs for any element that has a "completed" state. A very groovy find command — pun intended.
XML:
<flow name="Get_Status_Batch_Job" processingStrategy="synchronous">
<expression-component
doc:name="Wait 5 minutes before checking the Batch Status"><![CDATA[java.lang.Thread.sleep(300000);]]></expression-component>
<sfdc:batch-info-list config-ref="Salesforce__Basic_Authentication"
doc:name="Get the state of the Batch Job" jobId="#[flowVars.jobId]">
</sfdc:batch-info-list>
<scripting:component doc:name="Filter Only Completed Batch Info List"
doc:description="Need to create choice logic with the groovy script">
<scripting:script engine="Groovy"><![CDATA[def theResults = payload.batchInfo.toList().findResults{it.state.toString() == 'Completed' ? it.id : null};
return theResults;]]></scripting:script>
</scripting:component>
<choice doc:name="Choice">
<when expression="#[payload.size() > 0]">
<logger message="Complete" level="DEBUG"
doc:name="Complete - Return an Array of batchIds" />
</when>
<when expression="#[payload == 'failed']">
<logger message="Failed" level="DEBUG" doc:name="Failed" />
<flow-ref name="Close_Job" doc:name="Close_Job" />
</when>
<otherwise>
<logger message="Not Complete" level="DEBUG" doc:name="Not Complete" />
<flow-ref name="Get_Status_Batch_Job" doc:name="Get_Status_Batch_Job" />
</otherwise>
</choice>
</flow>Return_Results_From_Batch_Jobs_And_Save_To_File Flow
This is another manual flow to retrieve the batch job results (hoping this is in a future connector). PK chunking returns a BatchInfoList object; however, the Salesforce connector does not accept the BatchInfoList object as an argument to any of its operations, just the BatchInfo object. This flow needs some work, but it works. I would like to run ~15 parallel connects to retrieve the result set.
Visual:
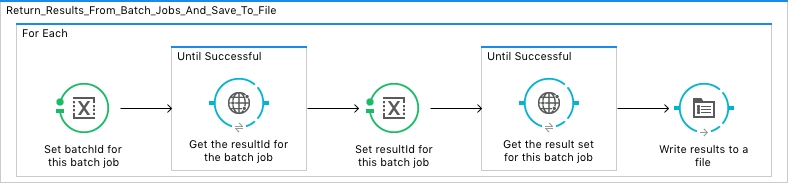
For each batch job ran on the Salesforce servers, the ID is needed to get the ResultId and then the resultset. Finally, the results are appended to a file. The destination could be anything you want (for example, SFTP, S3 bucket, Kafka queue, or Hadoop HDFS, to name a few).
XML:
<sub-flow name="Return_Results_From_Batch_Jobs_And_Save_To_File">
<foreach doc:name="For Each">
<set-variable variableName="batchId" value="#[payload]"
doc:name="Set batchId for this batch job" />
<until-successful maxRetries="5"
failureExpression="#[message.inboundProperties['http.status'] != 200]"
synchronous="true" doc:name="Until Successful">
<http:request config-ref="Create_SFDC_BulkAPI_Job"
path="/services/async/38.0/job/{jobId}/batch/{batchId}/result"
method="GET" doc:name="Get the resultId for the batch job">
<http:request-builder>
<http:uri-param paramName="jobId" value="#[flowVars.jobId]" />
<http:uri-param paramName="batchId" value="#[flowVars.batchId]" />
<http:header headerName="X-SFDC-Session" value="#[flowVars.sessionId]" />
</http:request-builder>
<http:success-status-code-validator
values="200..599" />
</http:request>
</until-successful>
<set-variable variableName="resultId"
value="#[xpath3('//*[local-name()="result"]')]" doc:name="Set resultId for this batch job" />
<until-successful maxRetries="5"
failureExpression="#[message.inboundProperties['http.status'] != 200]"
synchronous="true" doc:name="Until Successful">
<http:request config-ref="Create_SFDC_BulkAPI_Job"
path="/services/async/38.0/job/{jobId}/batch/{batchId}/result/{resultId}"
method="GET" doc:name="Get the result set for this batch job">
<http:request-builder>
<http:uri-param paramName="jobId" value="#[flowVars.jobId]" />
<http:uri-param paramName="batchId" value="#[flowVars.batchId]" />
<http:uri-param paramName="resultId" value="#[flowVars.resultId]" />
<http:header headerName="X-SFDC-Session" value="#[flowVars.sessionId]" />
</http:request-builder>
<http:success-status-code-validator
values="200..599" />
</http:request>
</until-successful>
<file:outbound-endpoint path="src/main/resources/output"
connector-ref="Output_File" responseTimeout="10000"
doc:name="Write results to a file" />
</foreach>
</sub-flow>Close_Job
The result set will be kept for seven days on the Salesforce servers. When all the data is consumed from the Salesforce servers, it's good practice to close the job and free up some space.
Visual:

XML:
<sub-flow name="Close_Job">
<sfdc:close-job config-ref="Salesforce__Basic_Authentication"
jobId="#[flowVars.jobId]" doc:name="Close the Salesforce Job" />
</sub-flow>Conclusion
As you can see, it takes some work to export large amounts of data from Salesforce.com. This is a good use case for one-time or occasional export and backup. In my test Salesforce org, I loaded 60M Contacts with 20 custom fields with data. The query process took less than five minutes and the retrieval process took 1.5 hours. That's not bad for successfully exporting 60M records. I could refine the result retrieval process in parallel and drastically reduce the overall time to export the data.
The negative part of using the bulk query is the limitations of the SOQL queries: no joins or reference fields.
I wouldn't try this with any other data integration tool than Mule.
References
Please check out these Reference links to help explain things even more clearly.
Opinions expressed by DZone contributors are their own.
Comments