Architecture and Code Design, Pt. 2: Polyglot Persistence Insights To Use Today and in the Upcoming Years
We take into consideration the need to leverage a great number of storage options currently for persisting and managing data in Java applications.
Join the DZone community and get the full member experience.
Join For FreeThis two-part series explores from a persistence perspective topics such as application architecture, code design, framework solutions, traps, and news of the Jakarta EE world that can help you design and architect better solutions in the upcoming years.
In part one, we coved how potential behaviors that can add extra processing and resource consumption to your database's integration and got up to date with news on what's out there and what's coming for Java applications that rely on relational data storage integration.
In part two (this article), we take into consideration the need to leverage a great number of storage options currently for persisting and managing data in Java applications. They vary from relational (SQL) to NoSQL, in-memory graph databases, and can be either traditional on-premise and self-managed or run as a cloud service (DBaaS- Database as a Service). Taking this into consideration, get to know enterprise ways of handling polyglot persistence architectures for Java solutions and become aware of several roadblocks that are possibly slowing down both your service and your team's performance today.
Polyglot Persistence
As microservices architecture adoption gets consolidated, so do polyglot solutions — polyglot not only from a programming language aspect but also from a storage perspective as well. Solutions composed of smaller independent services allow each service to adopt the type of storage that best addresses its needs. It is, therefore, vital to understand the multiple types of persistence storage solutions out there. Adding to the previous insights on a relational database, next are the topics you must know today about other Java persistence integrations.
Java and NoSQL Persistence
Integrating Java solutions with NoSQL databases can be painless — if you don't plan to change the DB engine. Amongst SQL storage options, there are multiple options: Key-value, Column Families, Document, Graph, and more. For each type, the market is filled with vendors. If we pick key-value as an example, we could choose between Cassandra, Redis, Amazon DynamoDB, ArangoDB, Couchbase, and many others — but wait; Let's stop listing the options because, to be honest, looking at the whole NoSQL landscape, we can find more than 220 NoSQL database options!
As architects, how do we handle such a plurality of APIs and drivers, and how do we ensure our persistence code layer implementation can be performant today and survive future migrations and modernization without causing too much pain?
Whenever we integrate service and database:
- We must "teach" the application how to "speak the database language" — we do that by using a driver.
- We also must map our data model to the final database model structure — generally with annotations.
- We configure and fine-tune our database connections and integration through data sources and other configurations.
Today, there's no such thing as a Jakarta specification to help abstract and create a single way to handle this many different options. Using the vendor's driver API is a common way. As a consequence, multiple code changes are needed in case there's a need to migrate to another vendor solution. We won't even drill down the pain of migrating from one database type to another.
Java architects can ease this pain with the usage of the open-source project JNoSQL. It comes in handy by abstracting the different APIs provided by the NoSQL DB vendors and abstracting multiple NoSQL DB Types, allowing us to learn a single API and easily modify the backing storage solution if/when we need it. JNoSQL currently supports 30 different database options, including popular ones such as MongoDB, Elastic, Cassandra, Couchbase, Redis, Infinispan, Neo4j, and Hazelcast.
Using it is very straightforward: Once you add the JNoSQL dependency and the desired database's driver dependency, you will configure the connection details, and you're ready to start coding. The entities should look very familiar to you, as you'll be using annotations such as @Entity, @Id, and @Column.
Another good news is: Jakarta EE already has a specification approved and under development that should soon become part of the platform: Jakarta NoSQL. The specification should cover not only common APIs but also APIs for Pagination, bean validation supported with Bean Validation specification, configuration via MicroProfile Config, and much more.
SQL and NoSQL Integration Disparities: Is There a Way Out?
We understand the excitement that can come with the possibilities offered by specifications such as Jakarta NoSQL. Although architects might think: "I still have the problem of having to learn multiple APIs — for SQL and NoSQL. And I still have different ways of handling these two strategies and all the previously mentioned problems that come with such disparities.".
Well, here's more good news: the working groups of the Jakarta EE platform, with the help of the broader Java community, are planning to address this problem with the Jakarta Data specification. It aims to offer an abstraction to data integration — be it SQL or NoSQL, or even cloud-based data services. The Jakarta Data project is approved by the Eclipse Foundation and is currently in progress, planned to be an Apache Licensed specification for future Jakarta EE versions.
If you're a Java developer, architect, and/or enthusiast and love to contribute to open source, this is a great chance. All the community is welcome to be part of the Jakarta EE story by contributing to several specifications, including young and promising ones such as Jakarta Data.
More Roadblocks to Be Cautious With
After getting informed on relational and NoSQL data storage with Java applications, there's yet another persistence storage approach to be covered: in-memory storage. To be more precise, let's discuss persistence issues and challenges that every SQL/NoSQL-based Java service has to exist with, which are addressed by Java native in-memory storage solutions.
Model Mapping: Object Domain Model and Database Model
Data modeling is the process of identifying entities and their relationships. In relational databases, data is placed in normalized tables with foreign keys used to reference related data in other tables. Whenever we integrate with a database, we have to map our domain classes to database tables (or other models). The example below shows a domain mapping of the classes Person and Address to their respective tables in a relational database. Since it's mapped as an n-n relation, then we end up with one extra table, in this case, PERSON_ADDRESS:
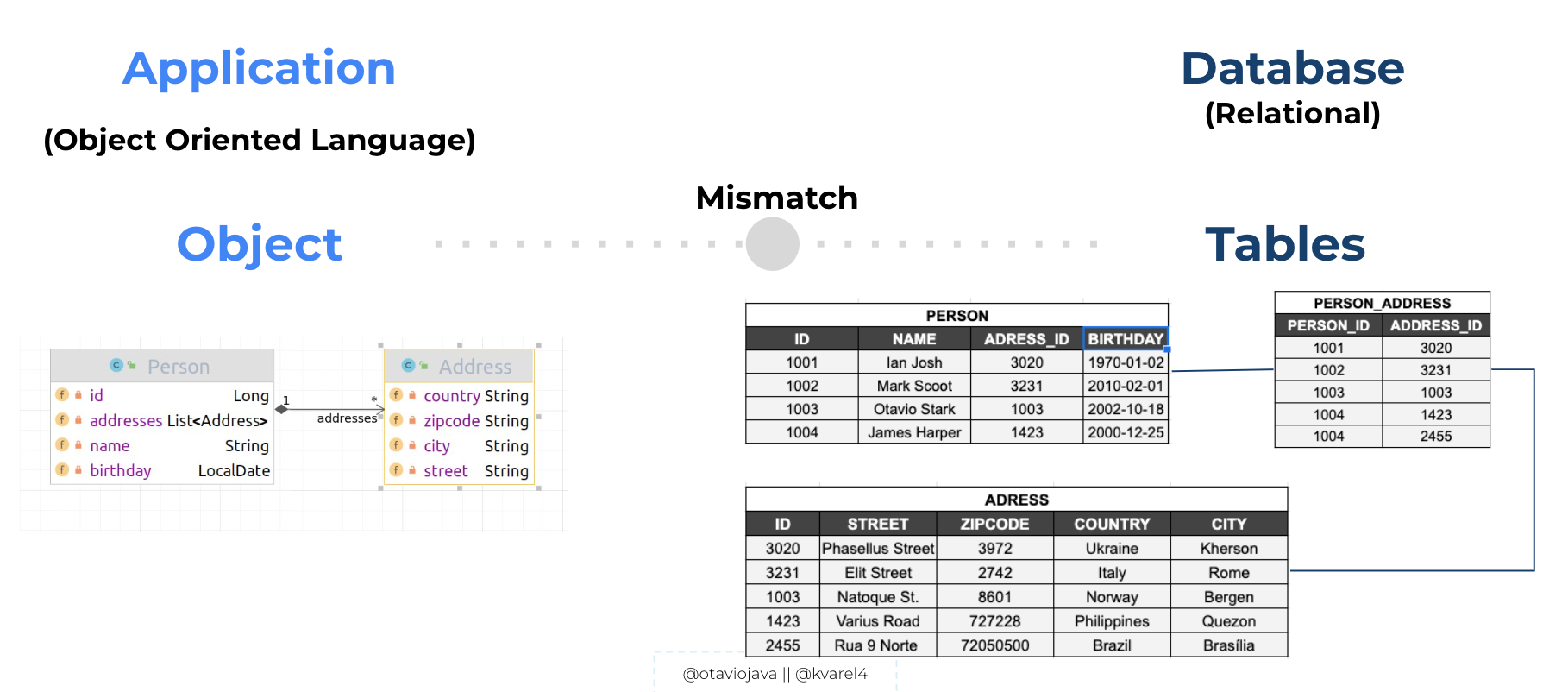
On the application side, we rely on the persistence configuration of the classes to map them as best as possible to the relational database model. Unfortunately, capabilities such as inheritance, polymorphism, and encapsulation, to mention some, come from the paradigm of Object Oriented Programming. Such features are not supported and have no equivalent representation in the paradigm brought by relational databases. The same is valid the other way around, where Java cannot do a perfect mapping of every behavior available within database models and systems.
Designing these data models requires good knowledge of both worlds and is a time-consuming task - especially when involving heavy documentation practices. Evolving these models can also be tricky since we must take into consideration not only the new application version deployment but, along with it, the respective database model and/or data must also be updated.
Database Operations and the Hidden Extra Processing
The Object-relational impedance mismatch is a well-known problem in the area of OOPs. It arises due to the fact that the object model and the relational model of data are not directly compatible. As a result, when data is mapped from one model to the other, some information is lost in the process. This loss of information can lead to performance degradation, as the data in the object model is not consistent with the data in the relational model.
Now, notice that every object needs proper conversion to its equivalent model in the database every time an operation happens. We can then comprehend that data conversion is happening through every read and right; in other words, we have extra processing and added latency due to the models' conversions: from the Java domain model to the Database model and vice versa.
Retrieving Data Nightmare: Complex Multi-Table Queries
If you ever came across a long and complex query, where to get the information you need, you must (right, left, inner, outer...) join multiple tables, group by, filter by, etc., and you know exactly how much time is spent, and how much pain and trouble that comes with it.
What if we could use Java Streams API instead? What if retrieving data was something as straightforward as the code below:
public static void booksByAuthor()
{
final Map<Author, List<Book>> booksByAuthor =
AcmeLibrary.data().books().stream()
.collect(groupingBy(book -> book.author()));
booksByAuthor.entrySet().forEach(e -> {
System.out.println(e.getKey().name());
e.getValue().forEach(book -> {
System.out.print('\t');
System.out.println(book.title());
});
});
}Our jobs would be way easier right?
How to Get Rid of the Roadblocks
Summarizing the performance villains that hide within our applications are:
- Domain mapping: mapping our Java domain model to database models (either SQL or NoSQL) is time-consuming and error-prone. It is also susceptible to adding complexity to maintenance as the model grows and evolves.
- Object-relational impedance mismatch: by using different paradigms between programing language and database, we go down the path of having extra processing for conversions on every database operation.
- Complex queries: even with the support of ORMs, we end up having to use complex queries with multiple joins and tables to retrieve the data we need. Such queries are also harder to maintain and track.
To enhance a database layer's performance, improve the development experience, and reduce costs, we can rely on in-memory persistence storage solutions.
To better explain this approach, we'll reference the technology called MicroStream. MicroStream is an open-source project, and its latest version is 7.1. The fact that it is built on top of CDI allows it to integrate smoothly with multiple runtime solutions such as Helidon (which officially supports MicroStream), Payara Micro, and Wildfly. Some interesting facts about:
- It's a Java native storage solution, and it runs on a JVM. You can run this storage solution wherever you can run a JVM. Since running on a JVM, it also brings a garbage collector for storage.
- Save time by skipping data mapping. There's no need to map your class attributes to database tables and columns. The data is stored as an object graph. Any Java type can be persisted without pain.
Java
public class Book { private final String id; private final String title; private final String author; private final Year release; ... } - Data manipulation: Instead of having the traditional four CRUD operations, you can rely uniquely on two APIs that allow you to read and save the object's graph.
Java@Storage public class Library { private final Set<Book> books; public Library() { books = new HashSet<>(); } public void add(Book book){ this.books.add(book); } public List<Book> getBooks() { return this.books.stream().collect(Collectors.toUnmodifiableList()); } }
- Retrieving data couldn't be easier: Instead of complex SQL queries, since we are integrating with Java-based storage, we can rely on our good old get methods. Even better: we can use the powerful Java Streams API to filter and group data as needed.
- Choose where to store your data: "Run away from vendor lock-in" is a recommendation you've probably heard several times. It is also valid for your chosen persistence storage. When using an in-memory persistence strategy, you will need to leverage how much memory you'll have available to load a data set. It's totally possible that you have such a large data set that you'll need an external persistence solution working along with your in-memory storage. If using MicroStream, you have a large set of options to use as an external storage target. By using internal connectors, it abstracts this integration for the developer and allows the application to use in-memory persistence backed by multiple types of storage solutions such as RDBMS, NoSQL, Object Stores, distributed cache, and more.
Other than the technical benefits we've pointed out so far, a Java in-memory data storage solution such as MicroStream can be quite simple to get started with, and over time an architectural solution that follows this approach can be highly cost-saving if compared to traditional relational database clusters or even DBaaS offerings. To learn more about this technology and see it in action, check out the following video:
Conclusion
Java is a powerful programming language that can be used to create high-performance applications. When working with databases, there are a number of factors that can affect both a solution's performance and architectural design quality aspects. In this two-part series, we learned the following:
- What's new on the recent Jakarta EE 10 release with respect to persistence with JPA.
- How data-related design patterns and persistence framework implementation choices can impact our code design positively or negatively.
- How we can prospect polyglot Java solutions that handle not only traditional relational databases but also NoSQL databases, putting in place the challenges of the current path offered by vendors in contrast to the Jakarta EE specification under development, Jakarta NoSQL.
- In-memory database solutions advantages if compared to storage that can't match OOP; How such solutions can help you optimize the performance of your application.
With the proper information and guidance on how to analyze, architects can then make strategic and solid implementation decisions for their solution's persistence layer and avoid future pain for the whole organization.
Opinions expressed by DZone contributors are their own.
Comments